一. 概述
2) 行锁:操作时,会锁定当前操作行。
• 从对数据操作的类型分:
1) 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
2) 写锁(排它锁):当前操作没有完成之前,它会阻断其他写锁和读锁。
三. MySQL锁
相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。下表中罗列出了各存储引擎对锁的支持情况:
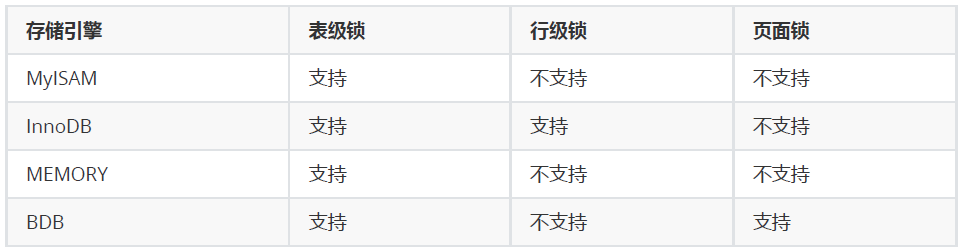
MySQL这3种锁的特性可大致归纳如下:

从上述特点可见,很难笼统地说哪种锁更好,只能就具体应用的特点来说哪种锁更合适!仅从锁的角度来说:表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web 应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并查询的应用,如一些在线事务处理(OLTP)系统。
(1)MyISAM 表锁
MyISAM 存储引擎只支持表锁,MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT 等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此,用户一般不需要直接用 LOCK TABLE 命令给 MyISAM 表显式加锁。
显式加表锁语法:
-- 加读锁 lock table table_name read; -- 加写锁 lock table table_name write;
锁模式的相互兼容性如表中所示:

简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁,则既会阻塞读,又会阻塞写。
此外,MyISAM 的读写锁调度是写优先,这也是MyISAM不适合做写为主的表的存储引擎的原因。因为写锁后,其他线程不能做任何操作,大量的更新会使查询很难得到锁,从而造成永远阻塞。
(2)InnoDB行锁
存储引擎InnoDB与MyISAM的最大不同有两点:一是支持事务;二是采用了行级锁。InnoDB 实现了以下两种类型的行锁:
- 共享锁(S):又称为读锁,简称S锁,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁(X):又称为写锁,简称X锁,排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。
虽然与MyISAM的读写锁很相似,但是这里是以事务为对象的行锁,教材中的锁就是行锁;这里提到了事务,那先回顾一下事务的概念。
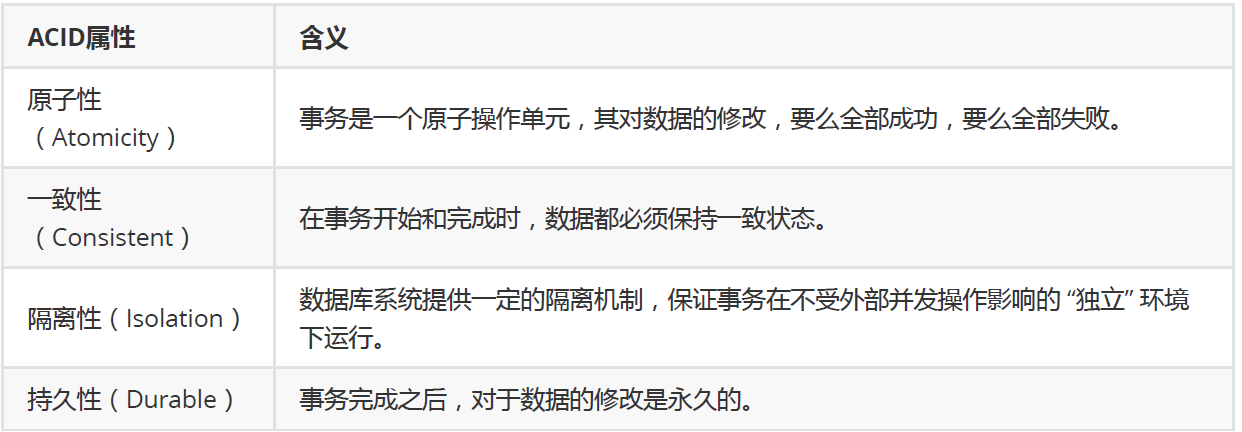
首先是事务的四个特性:
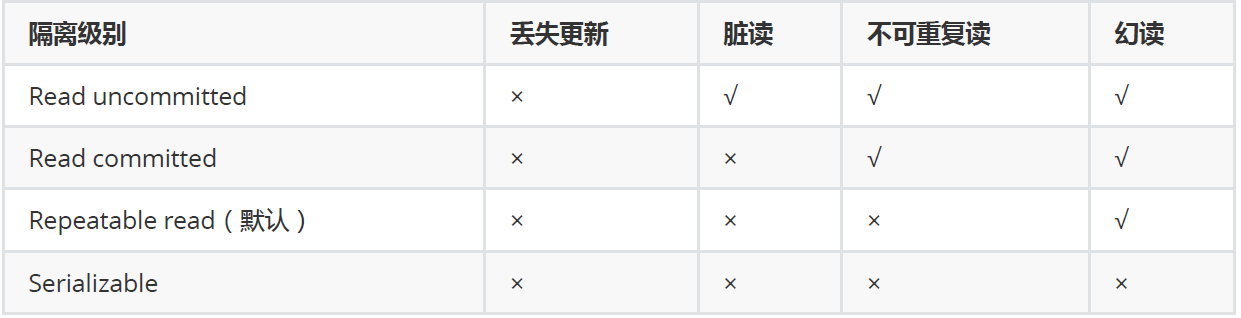
并发事务处理带来的问题:

为了解决上述提到的事务并发问题,数据库提供一定的事务隔离机制来解决这个问题。数据库的隔离级别有4个,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏写、脏读、不可重复读、幻读这几类问题。
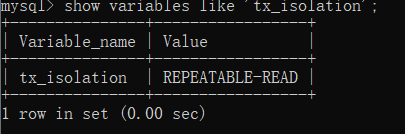
MySQL的数据库的默认隔离级别为Repeatable read ,查看方式:
InnoDB通过MVCC(多版本并发控制来实现读已提交和可重复读):在每行后面有两个隐藏列,即创建时间和删除时间,其实是版本号;当前事务只查找版本小于等于当前版本号的数据行
show variables like 'tx_isolation';
那我们回到InnoDB的锁,对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;也可以通过显式的语句加锁:
-- 共享锁(S) SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE -- 排他锁(X) SELECT * FROM table_name WHERE ... FOR UPDATE
使用InnoDB行锁可能出现的问题:
- 如果不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,实际效果跟表锁一样。
- 当我们用范围条件,而不是使用相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据进行加锁; 对于键值在条件范围内但并不存在的记录,叫做 "间隙(GAP)" ,InnoDB也会对这个 "间隙" 加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
总而言之,InnoDB存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面带来了性能损耗可能比表锁会更高一些,但是在整体并发处理能力方面要远远由于MyISAM的表锁的。当系统并发量较高的时候,InnoDB的整体性能和MyISAM相比就会有比较明显的优势。但也要避免使用不当的情况,如避免升级为行锁,避免间隙锁,控制事务大小等。
四. 乐观锁
(1)概述
上面所述的加锁方式都属于悲观锁,依赖了数据库的锁机制;事实上悲观锁指的就是总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞,直到它拿到锁。
而乐观锁机制采取了更加宽松的加锁机制。乐观锁是相对悲观锁而言,也是为了避免数据库幻读、业务处理时间过长等原因引起数据处理错误的一种机制,但乐观锁不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。
相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。
(2)实现方式
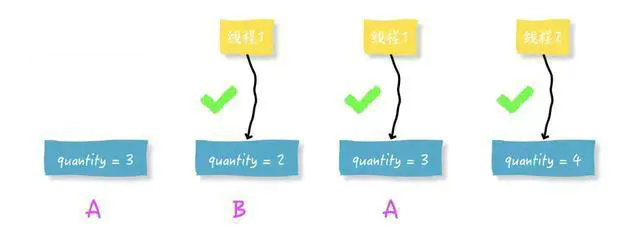
有一个比较好的办法可以解决ABA问题,那就是通过一个单独的可以顺序递增的version字段。改为以下方式即可:

除了version以外,还可以使用时间戳(TimeStamp),因为时间戳天然具有顺序递增性。
(3)总结
乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。悲观锁依赖数据库锁,效率低。更新失败的概率比较低。而现在实际的生产环境中,尤其高并发量的业务场景下,乐观锁使用的更多。
参考:https://www.jianshu.com/p/d2ac26ca6525