一. 大规模导入数据
1. 使用load命令导入数据
LOAD DATA LOCAL INFILE 'F:sql1.log' INTO TABLE tb_user_1 fields TERMINATED by ',' lines TERMINATED by ' ';
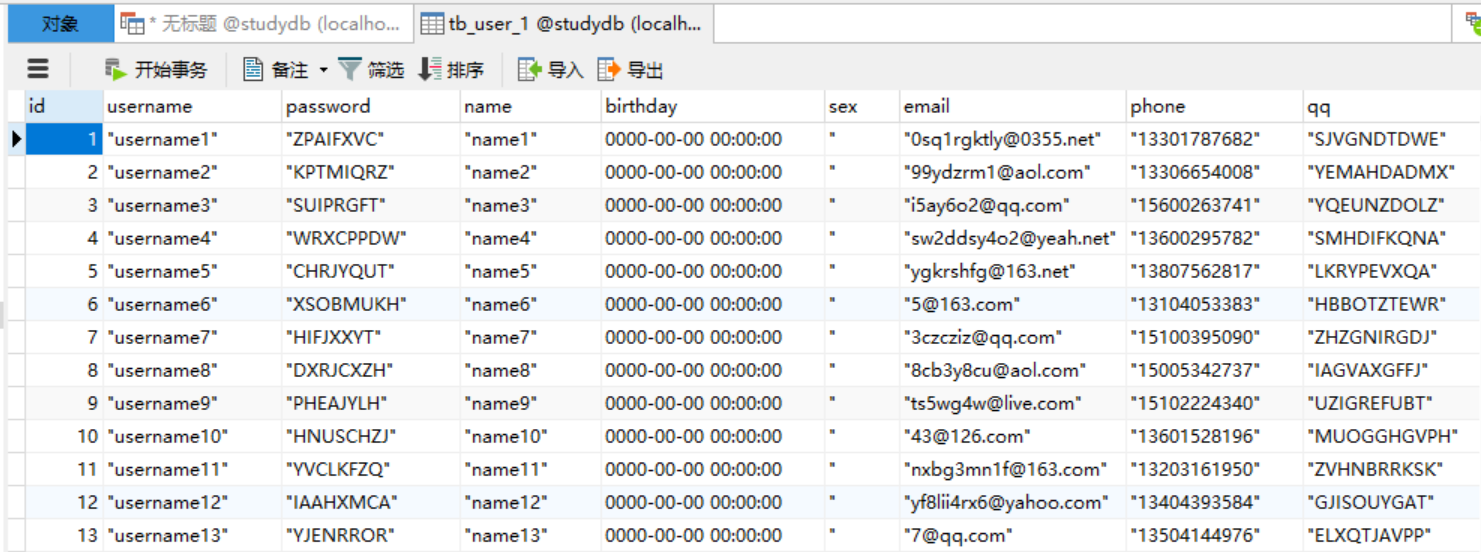
数据格式:

导入结果:
2. 对于InnoDB类型的表,提升导入效率
(1)数据按主键顺序插入,上面的sql1.log就是按主键顺序排序的,导入效率比乱序要高。
(2)关闭唯一性校验(对于有唯一性索引的表)
-- 导入前 SET UNIQUE_CHECKS=0; -- 导入后 SET UNIQUE_CHECKS=1;
(3)手动提交事务
-- 导入前 SET AUTOCOMMIT=0; -- 导入后 SET AUTOCOMMIT=1;
二. 优化insert语句
(1)合并多个insert语句块
-- 原始 insert into s_contact values(1,5,'Amy',10001,'家属'); insert into s_contact values(2,8,'Tom',10002,'同事'); insert into s_contact values(3,18,'Jerry',10003,'陌生人'); -- 优化 insert into s_contact values (1,5,'Amy',10001,'家属'), (2,8,'Tom',10002,'同事'), (3,18,'Jerry',10003,'陌生人');
(2)在事务中进行数据插入
start transaction; insert into s_contact values(1,5,'Amy',10001,'家属'); insert into s_contact values(2,8,'Tom',10002,'同事'); insert into s_contact values(3,18,'Jerry',10003,'陌生人'); commit;
(3)按照主键顺序插入
按照主键顺序插入数据,插入的效率和执行速度会更优。
三. 优化order by语句
先回顾一下Extra中的两种信息:
- Using filesort:说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为“文件排序”, 效率低。MySQL中对于filesort有两种算法:一是"两次扫描算法",取出排序字段和行指针进行排序,排序之后回表读数据;另一种是"一次扫描算法",一次性取出所有字段,在排序缓冲区排序,这种做法排序时内存开销较大,但IO次数少。
- Using index:通过有序索引顺序扫描直接返回有序数据,不需要额外排序,操作效率高,我们希望优化为这种情况。
在尝试之前检查一下s_patient表中的索引:

(1)覆盖索引的order by
explain select id, hospital_id, username from s_patient order by hospital_id,username;
在这一条SQL中,我们的select字段和排序(order by)字段都覆盖在索引内find_partient2和主索引内,因此满足了Using index;

而如果在select字段或排序字段添加一个不在find_patient2或主索引的属性,则会变成Using filesort(较差的效率),如下图所示;

上面的cur_condition是在另一个索引中的,和hospital_id非同索引,无法直接返回,效率变低,这也提醒了我们在SQL中对字段做出合理的选择。
(2)多字段,全升序或全降序
在覆盖索引的前提下,如果我们对索引中多字段进行排序,要么全部升序asc,要么都降序desc,否则还会出现Using filesort;
explain select id, hospital_id from s_patient order by hospital_id desc,username asc; explain select id, hospital_id from s_patient order by hospital_id desc,username desc;
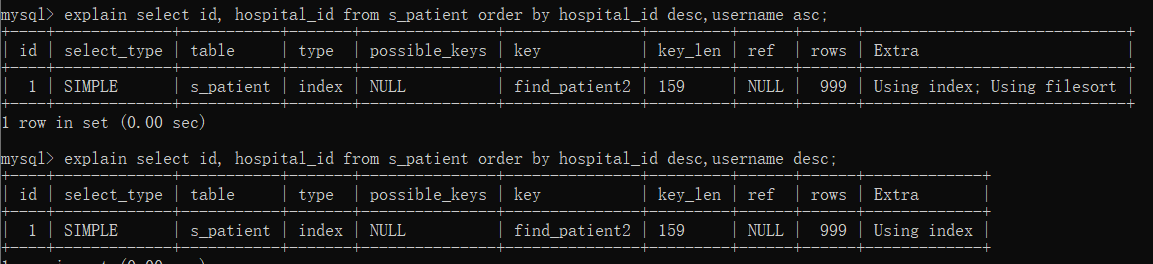
因此多字段时,我们尽量让整体符合一个顺序,如果不能满足应注意到此处有效率降低的filesort。
(3)多字段,排序顺序需和索引保持一致
在上面的情况下,如果把username放到hospital_id前面,也会出现额外排序(filesort)。

(4)对filesort优化
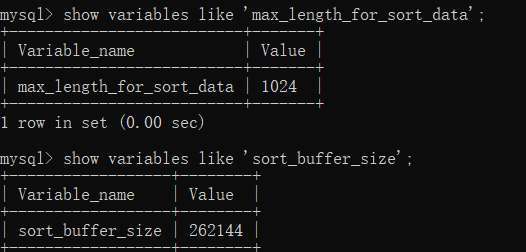
经过上面的优化,处理了大部分filesort,但根据系统中需求,不能完全避免filesort,对于剩余使用了filesort的SQL,我们要对filesort进行优化,也就是使用我们上面提到的"一次扫描算法"。
优化方法:适当提高 sort_buffer_size 和 max_length_for_sort_data 系统变量,来增大排序区的大小,提高排序的效率;当MySQL发现排序区足够大时,会使用第二次filesort算法,即一次扫描,效率会比两次扫描算法高。
四. 优化group by语句
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作。当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算。所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引。
如果查询包含 group by 但是用户想要避免排序结果的消耗, 则可以执行order by null 禁止排序。如下 :

省去了一个filesort,这里Using temporary表示使用临时表,由于索引find_patient建立在(sex, hometown, cur_condition),毕竟hometown没有满足最左匹配,这里效率还算可以。
那如果想把Using temporary优化掉,可以把hometown前面的sex也加上,这样就是纯利用索引,提高效率。

五. 嵌套查询语句优化
这部分只有一个原则:子查询尽量用效率更高的多表连接查询替代。比如下面的例子,我们查询正在用药的患者的姓名,地区,和当前状态,就会联查s_patient和s_medicine两表。
explain select username,hometown,cur_condition from s_patient where id in (select patient_id as id from s_medicine); explain select username,hometown,cur_condition from s_patient,s_medicine where s_medicine.patient_id=s_patient.id;
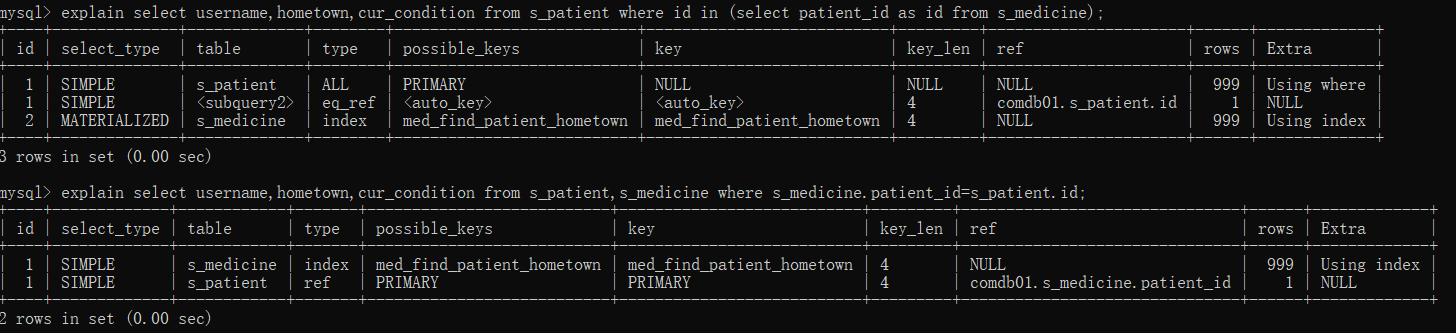
很明显第二种联查方式比第一种子查询执行条目少,且type由ALL提升到ref,效率优化明显。
六. 优化or查询
在索引规则的一篇中已经提到,or连接的属性只要有一个无索引,则整体索引不生效,且不能使用复合索引。
优化方式:用union替换or。
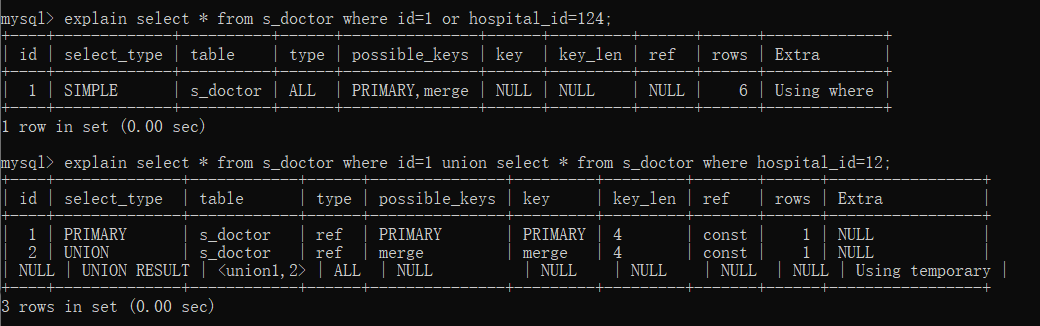
通过这条对s_doctor表的查询,可以发现union的type为ref,明显比or的情况更优。
七. 优化分页查询
分页查询在这个项目中使用频率很高,上图就是一个分页例子,对应到SQL查询中使用的就是limit关键字;
-- limit 第几篇,每篇行数 select * from s_patient limit 80,10;
不过这种SQL查询的问题在于,当篇数变得很大时效率会很低,比如篇数=10000时,需要对前100010条记录排序,然后只取出其中100000-100010的记录,无用的排序代价太高。
优化思路一:在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
select * from s_patient,(select id from s_patient order by id limit 80,10) a where s_patient.id=a.id;
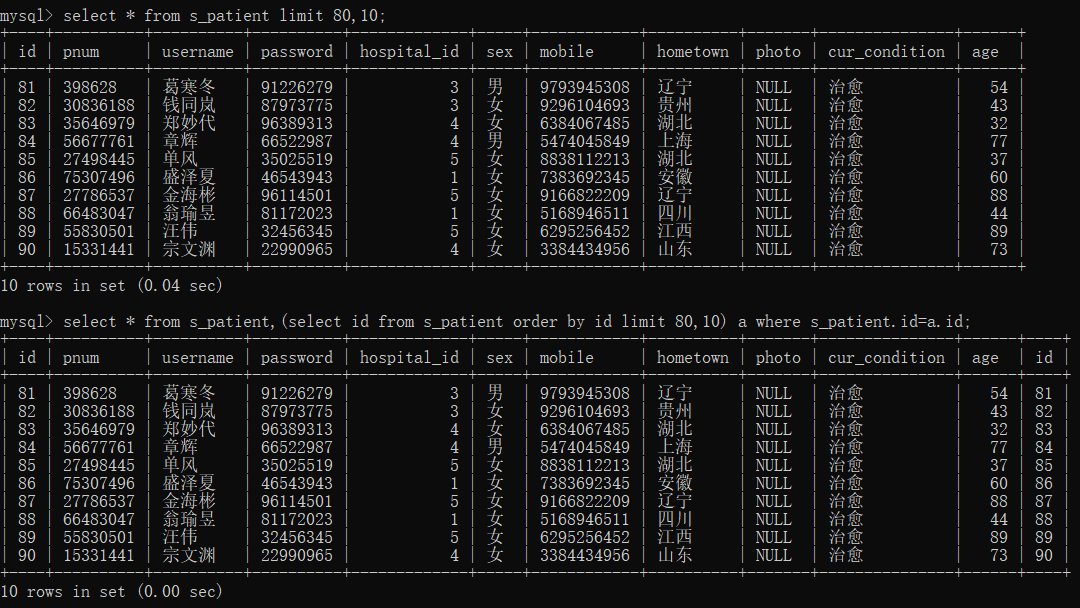
可以看出数据量不大的情况下时间优化也是很明显的;
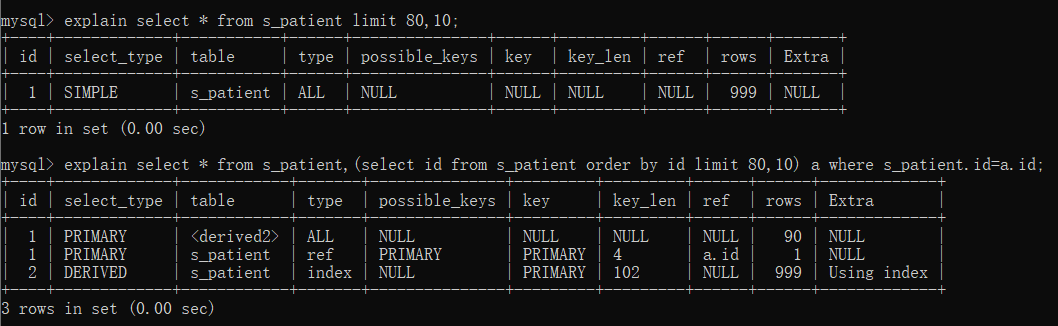
再对两次查询做explain,可以看到第一次执行走的是ALL全表扫描,第二次优化后的使用到了主键索引。
优化思路二:对于主键自增的表(且id无断层),可以把Limit 查询转换成某个位置的查询 。
select * from s_patient where id>800 limit 10;
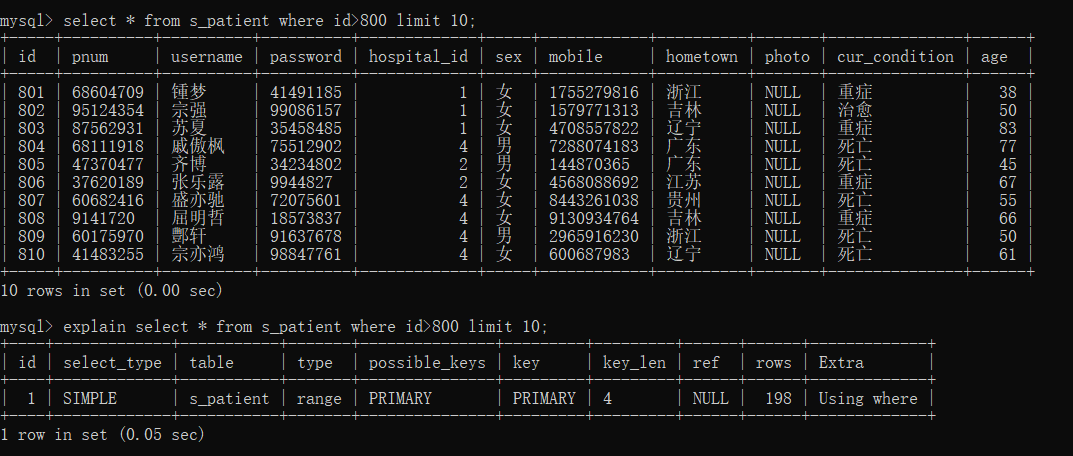
由于项目中patient表的id自增,所以可以直接利用索引锁定要找的位置(800以后),然后找出10条记录,explain可以看出直接走了主键索引,显然这种优化效率更高,也是我们使用的方案。
八. 显式指明索引
use index:在查询语句中表名的后面,添加 use index 来提供希望MySQL去参考的索引列表,就可以让MySQL不再考虑其他可用的索引。
explain select hospital_id from s_patient use index(find_patient2) where hospital_id=9; -- 指明走find_patient2索引
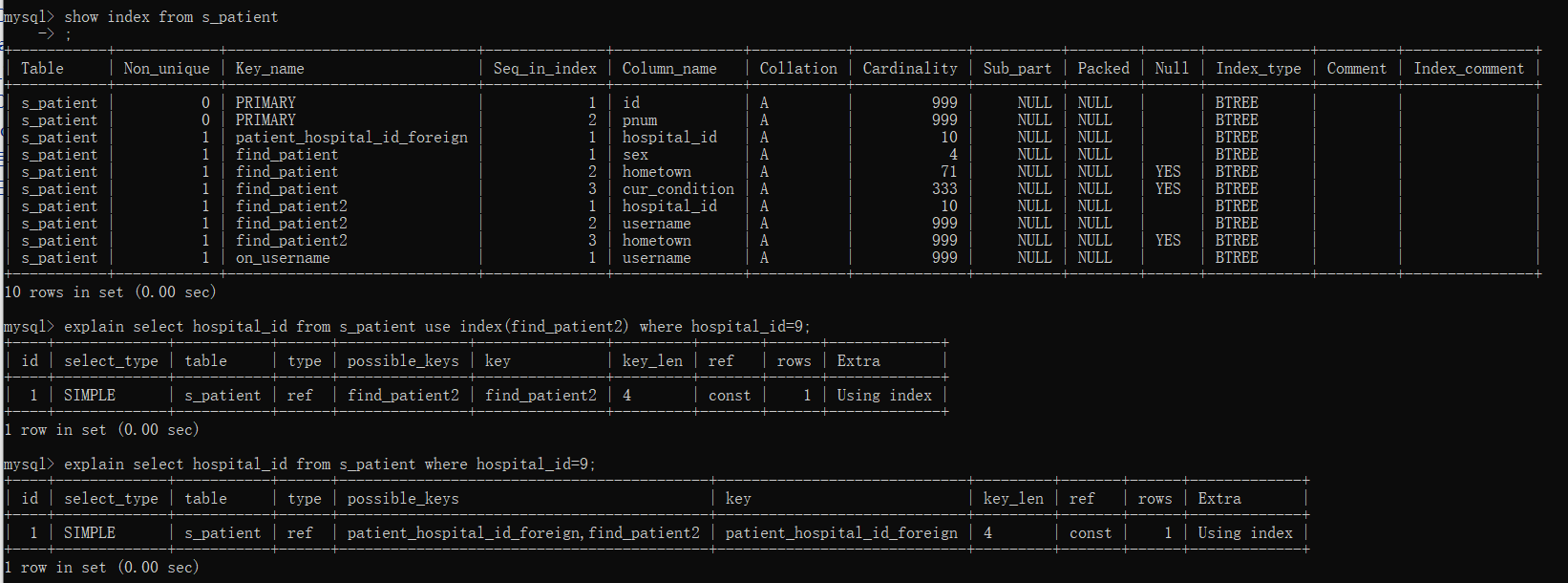
ignore index:如果只是单纯的想让MySQL忽略一个或者多个索引,则可以使用 ignore index 作为 hint 。
explain select hospital_id from s_patient ignore index(find_patient2) where hospital_id=9;

force index:为强制MySQL使用一个特定的索引,可在查询中使用 force index 作为hint 。
explain select * from s_doctor force index(i_mobile) where mobile='123';
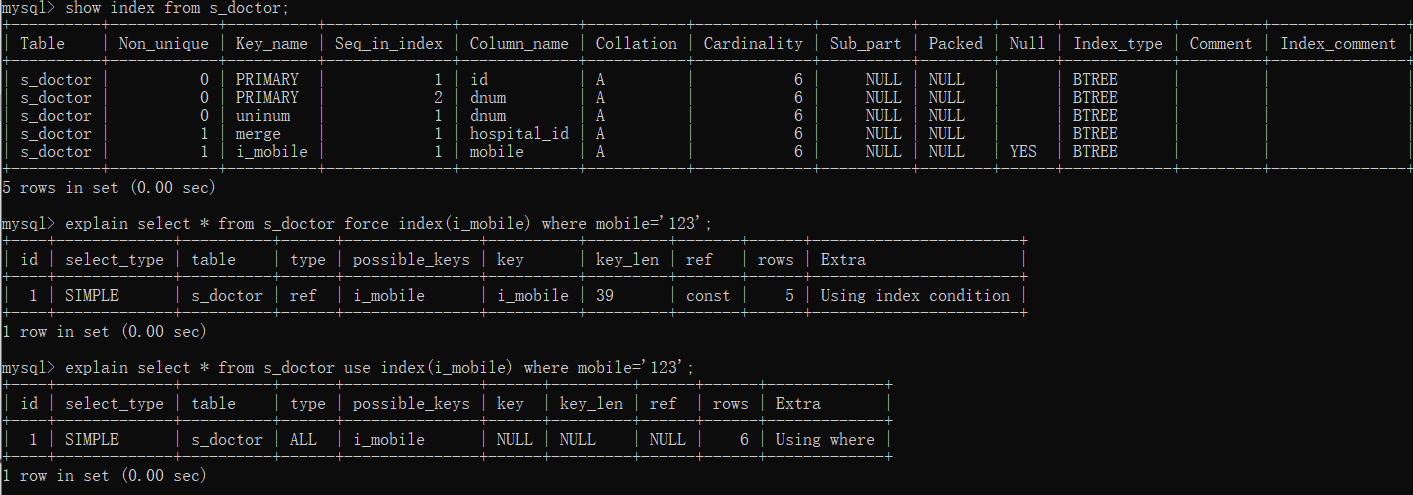
由于我们查询的示例mobile='123'在表中是不显著的数据,所以MySQL自动优化为不走索引更快,但是我们加上force index强制走了i_mobile索引。