索引是数据库优化最常用也是最重要的手段之一, 通过索引通常可以帮助用户解决大多数的MySQL的性能优化问题。很多时候我们因为而在使用SQL时违背了一些规则,导致查询未走索引,效率降低。我们希望索引生效,让执行效率提高。
(1)全值匹配
对索引中所有的列都指定具体值。
比如我们现在在患者表的sex, homtown, cur_condition建立一个多列索引。因为在系统中根据这三项查询患者的的功能时提供给用户的,所以这也是一条使用率很高的SQL语句。建立索引后对我们的查询作explain查看执行情况。
create index find_patient on s_patient(sex,hometown,cur_condition); explain select * from s_patient where sex='男' and hometown='上海' and cur_condition='治愈';

explain select * from s_patient where sex='男' and cur_condition='治愈' and hometown='西安';
#只要字段全,顺序可以互换

(2)最左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列。
explain select * from s_patient where sex='男';
#符合法则

explain select * from s_patient where hometown='上海' and cur_condition='治愈';
#违背最左前缀法则,索引失效

explain select * from s_patient where sex='男' and cur_condition='治愈';
#符合最左,但是跳过中间列,则只有最左列索引生效

(3)范围查询
包含范围查询时,范围查询列右边的列不走索引;与上面一样,左右都是指建立索引时的左右顺序,不是表序,也不是查询后where接的字段序。下面的结果中只有性别一列走了索引(通过key_len可以看出)。
explain select * from s_patient where hometown>'1' and sex='男';

(4)索引列不加运算
如果在索引列上进行运算操作, 列右边开始索引将失效;如果字符类别不加' '也算运算,底层会作类型转换相当于运算。下面的查询只有hospital_id走索引。
create index find_patient2 on s_patient(hospital_id,username,hometown); explain select * from s_patient where hospital_id=1 and substring(username,1,0)='张三';

(5)使用覆盖索引
尽量使用覆盖索引,避免select *,即只访问索引包含的列,这样可以免去回表查。下图中第一条没有满足覆盖索引,Extra中的信息为Using index condition,表示用到了索引但是需要回表查询,此效率低于Using where; Using index;而系统中对这条SQL也只需要返回其中的username,所以可作此优化。
explain select * from s_patient where username='张三' and hospital_id=1 and hometown='北京'; explain select username from s_patient where username='张三' and hospital_id=1 and hometown='北京';

(6)or连接
用or分割开的条件, 如果or条件连接的列中有没有索引的,则整体索引失效。下面查询中,手机号列没有索引,导致整体查询索引为NULL。
explain select * from s_patient where sex='男' or mobile='123';

(7)like模糊匹配
如果仅仅是xxx%结尾的尾部模糊匹配,索引不会失效,多列索引也可以生效。如果包含%开头的头部模糊匹配,索引失效。
explain select * from s_patient where username like '%张%';
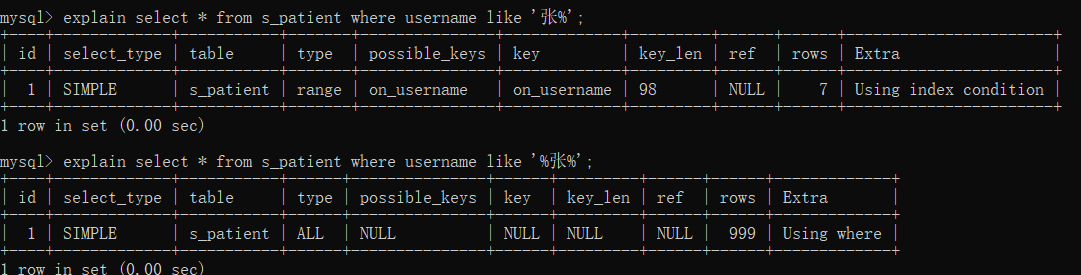
解决方式:覆盖索引

(8)数据特征
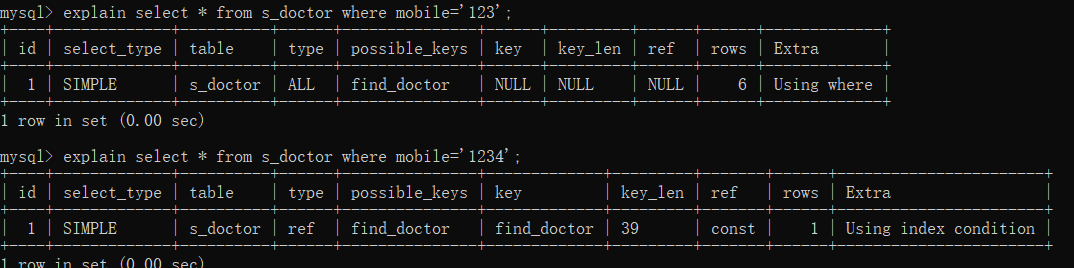
如果MySQL评估使用索引比全表更慢,则不使用索引。这种情况出现的原因是数据特征不显著,比如下面的查询,表中只有一条数据的mobile是'1234',其余的都是'123',这种情况下按='1234'查是走索引的,而如果按='123'查,MySQL会发现走索引不如遍历整表更快,则索引失效。is NULL和is NOT NULL原理相同,数据在表中太不显著,则不走索引。
create index find_doctor on s_doctor(mobile); explain select * from s_doctor where mobile='123'; explain select * from s_doctor where mobile='1234';
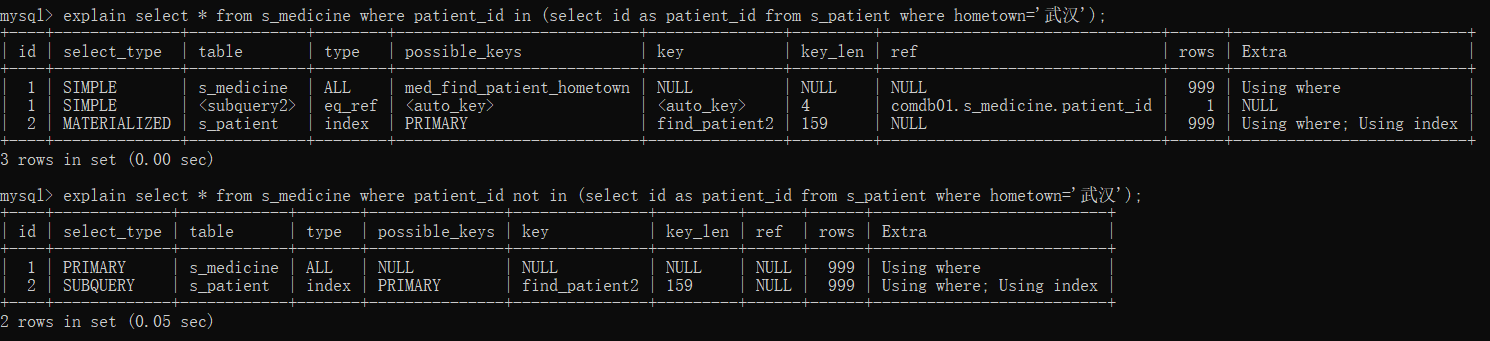
(9)in走索引,not in不走索引
下面的查询是系统中比较复杂的SQL之一,利用了子查询,如果是not in则表示找出非武汉地区患者的用药情况。
create index med_find_patient_hometown on s_medicine(patient_id); explain select * from s_medicine where patient_id in (select id as patient_id from s_patient where hometown='武汉'); explain select * from s_medicine where patient_id not in (select id as patient_id from s_patient where hometown='武汉');
(10)单列索引与复合索引
能使用复合索引的情况下,尽量使用复合索引而少使用单列索引。下面的例子回到最开始建的索引上。
复合索引:
create index find_patient on s_patient(sex,hometown,cur_condition); -- 相当于创建了三个索引: -- sex -- sex + hometown -- sex + hometown + cur_condition
单列索引:
create index find_patient_sex on s_patient(sex); create index find_patient_hometown on s_patient(hometown); create index find_patient_condition on s_patient(cur_condition); -- 数据库会使用一个最优的索引(辨识度最高的索引),而不会全使用
以上就是使用索引时的一些规则,最后补充一个查看索引使用情况:
show status like 'handler_read%';
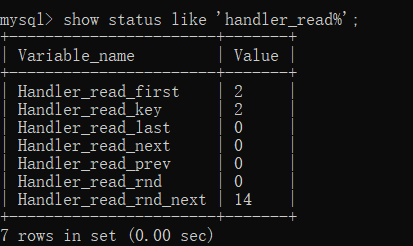
-- Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(这个值越低 -- 越好)。 -- Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的 -- 性能改善不高,因为索引不经常使用(这个值越高越好)。 -- Handler_read_next :按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列, -- 该值增加。 -- Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化ORDER BY ... DESC。 -- Handler_read_rnd :根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。 -- 你可能使用了大量需要MySQL扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应 -- 该建立索引来补救。 -- Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说 -- 明你的表索引不正确或写入的查询没有利用索引。