一、基本介绍
SHA (Security Hash Algorithm) 是美国的 NIST 和 NSA 设计的一种标准的 Hash 算法,SHA 用于数字签名的标准算法的 DSS 中,也是安全性很高的一种 Hash 算法。
SHA-1 是第一代 SHA 算法标准,后来的 SHA-224、SHA-256、SHA-384 和 SHA-512 被统称为 SHA-2。
二、实现原理
有关 SHA1 算法详情请参见 RFC 3174 http://www.ietf.org/rfc/rfc3174.txt。
RFC 3174 是SHA1算法的官方文档,(建议了解SHA1算法前,先了解下MD4 md4算法实现原理深剖 )其实现原理共分为5步:
第1步:字节填充(Append Padding Bytes)
数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数。
第2步:追加长度信息(Append Length)
数据比特位的数据长度追加到最后8字节中。【注意字节顺序与MD4不同 大小端之分】
第3步:初始化MD Buffer(Initialize MD Buffer)
这一步最简单了,定义ABCD四个4字节数组,分别赋初值即可。【注意相对于MD4 添加了H4】
uint32_t H0 = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t H1 = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t H2 = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t H3 = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t H4 = 0xC3D2E1F0; // 0xF0, 0xE1, 0xD2, 0xC3
第4步:处理消息块(Process Message in 16-Byte Blocks)
这个是SHA1算法最核心的部分了,对第2步组装数据进行分块依次处理。
/* Process each 16-word block. */ For i = 0 to N/16-1 do /* Copy block i into X. */ For j = 0 to 15 do Set X[j] to M[i*16+j]. end /* of loop on j */ a. Divide M(i) into 16 words W(0), W(1), ... , W(15), where W(0) is the left-most word. b. For t = 16 to 79 let W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)). c. Let A = H0, B = H1, C = H2, D = H3, E = H4. d. For t = 0 to 79 do TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t); E = D; D = C; C = S^30(B); B = A; A = TEMP; e. Let H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E. end /* of loop on i */
第5步:输出(Output)
这一步也非常简单,只需要将计算后的H0、H1、H2、H3、H4进行拼接输出即可。
三、示例讲解
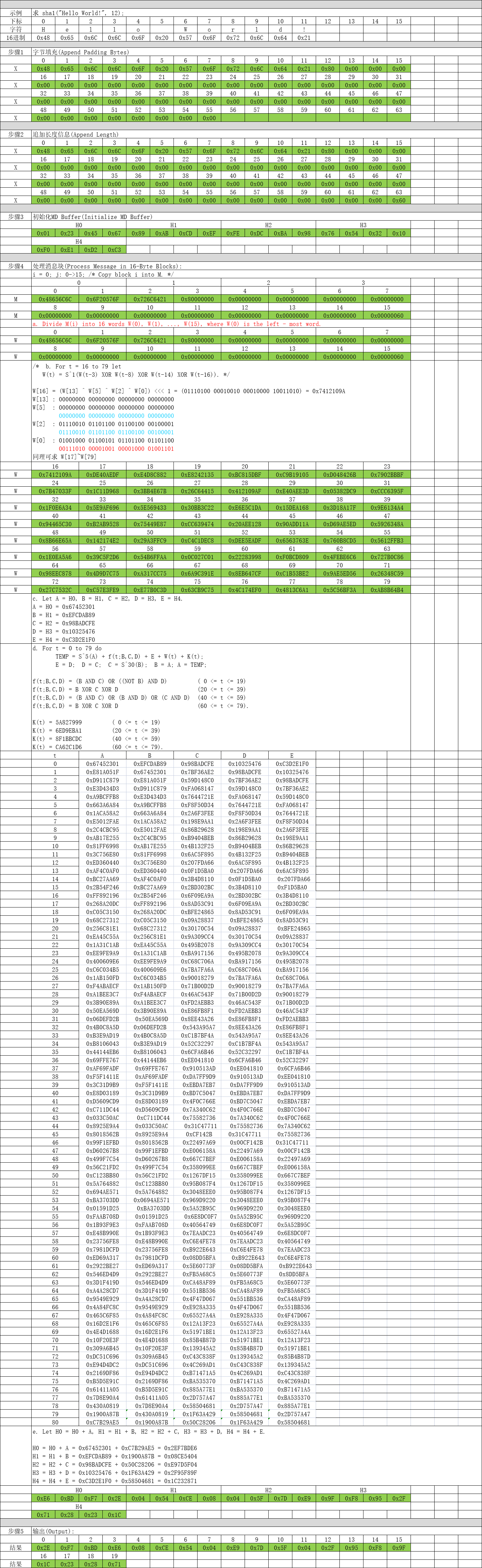
四、代码实现
以下为C/C++代码实现:
#include <string.h>
#include <stdio.h>
#define HASH_BLOCK_SIZE 64 /* 512 bits = 64 bytes */
#define HASH_LEN_SIZE 8 /* 64 bits = 8 bytes */
#define HASH_LEN_OFFSET 56 /* 64 bytes - 8 bytes */
#define HASH_DIGEST_SIZE 16 /* 128 bits = 16 bytes */
#define HASH_ROUND_NUM 80
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long long uint64_t;
/* Swap bytes in 32 bit value. 0x01234567 -> 0x67452301 */
#define __bswap_32(x) \
((((x) & 0xff000000) >> 24) \
| (((x) & 0x00ff0000) >> 8) \
| (((x) & 0x0000ff00) << 8) \
| (((x) & 0x000000ff) << 24))
/* SHA1 Constants */
static uint32_t K[4] =
{
0x5A827999, /* [0, 19] */
0x6ED9EBA1, /* [20, 39] */
0x8F1BBCDC, /* [40, 59] */
0xCA62C1D6 /* [60, 79] */
};
/* f(X, Y, Z) */
/* [0, 19] */
static uint32_t Ch(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ ((~X) & Z);
}
/* [20, 39] */ /* [60, 79] */
static uint32_t Parity(uint32_t X, uint32_t Y, uint32_t Z)
{
return X ^ Y ^ Z;
}
/* [40, 59] */
static uint32_t Maj(uint32_t X, uint32_t Y, uint32_t Z)
{
return (X & Y) ^ (X & Z) ^ (Y & Z);
}
/* 循环向左移动offset个比特位 */
static uint32_t MoveLeft(uint32_t X, uint8_t offset)
{
uint32_t res = (X << offset) | (X >> (32 - offset));
return res;
}
#define ASSERT_RETURN_INT(x, d) if(!(x)) { return d; }
int sha1(unsigned char *out, const unsigned char* in, const int inlen)
{
ASSERT_RETURN_INT(out && in && (inlen >= 0), 1);
int i = 0, j = 0, t = 0;
// step 1: 字节填充(Append Padding Bytes)
// 数据先补上1个1比特,再补上k个0比特,使得补位后的数据比特数(n+1+k)满足(n+1+k) mod 512 = 448,k取最小正整数
int iX = inlen / HASH_BLOCK_SIZE;
int iY = inlen % HASH_BLOCK_SIZE;
iX = (iY < HASH_LEN_OFFSET) ? iX : (iX + 1);
int iLen = (iX + 1) * HASH_BLOCK_SIZE;
unsigned char* X = malloc(iLen);
memcpy(X, in, inlen);
// 先补上1个1比特+7个0比特
X[inlen] = 0x80;
// 再补上(k-7)个0比特
for (i = inlen + 1; i < (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET); i++)
{
X[i] = 0;
}
// step 2: 追加长度信息(Append Length)
uint8_t *pLen = (uint64_t*)(X + (iX * HASH_BLOCK_SIZE + HASH_LEN_OFFSET));
uint64_t iTempLen = inlen << 3;
uint8_t *pTempLen = &iTempLen;
pLen[0] = pTempLen[7]; pLen[1] = pTempLen[6]; pLen[2] = pTempLen[5]; pLen[3] = pTempLen[4];
pLen[4] = pTempLen[3]; pLen[5] = pTempLen[2]; pLen[6] = pTempLen[1]; pLen[7] = pTempLen[0];
// Step 3. 初始化MD Buffer(Initialize MD Buffer)
uint32_t H0 = 0x67452301; // 0x01, 0x23, 0x45, 0x67
uint32_t H1 = 0xEFCDAB89; // 0x89, 0xAB, 0xCD, 0xEF
uint32_t H2 = 0x98BADCFE; // 0xFE, 0xDC, 0xBA, 0x98
uint32_t H3 = 0x10325476; // 0x76, 0x54, 0x32, 0x10
uint32_t H4 = 0xC3D2E1F0; // 0xF0, 0xE1, 0xD2, 0xC3
uint32_t M[HASH_BLOCK_SIZE / 4] = { 0 };
uint32_t W[HASH_ROUND_NUM] = { 0 };
// step 4: 处理消息块(Process Message in 64-Byte Blocks)
for (i = 0; i < iLen / HASH_BLOCK_SIZE; i++)
{
/* Copy block i into X. */
for (j = 0; j < HASH_BLOCK_SIZE; j = j + 4)
{
uint64_t k = i * HASH_BLOCK_SIZE + j;
M[j / 4] = (X[k] << 24) | (X[k + 1] << 16) | (X[k + 2] << 8) | X[k + 3];
}
/* a. Divide M(i) into 16 words W(0), W(1), ..., W(15), where W(0) is the left - most word. */
for (t = 0; t <= 15; t++)
{
W[t] = M[t];
}
/* b. For t = 16 to 79 let
W(t) = S^1(W(t-3) XOR W(t-8) XOR W(t-14) XOR W(t-16)). */
for (t = 16; t <= 79; t++)
{
W[t] = MoveLeft(W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16], 1);
}
/* c. Let A = H0, B = H1, C = H2, D = H3, E = H4. */
uint32_t A = H0;
uint32_t B = H1;
uint32_t C = H2;
uint32_t D = H3;
uint32_t E = H4;
/* d. For t = 0 to 79 do
TEMP = S^5(A) + f(t;B,C,D) + E + W(t) + K(t);
E = D; D = C; C = S^30(B); B = A; A = TEMP; */
for (t = 0; t <= 19; t++)
{
uint32_t temp = MoveLeft(A, 5) + Ch(B, C, D) + E + W[t] + K[0];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 20; t <= 39; t++)
{
uint32_t temp = MoveLeft(A, 5) + Parity(B, C, D) + E + W[t] + K[1];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 40; t <= 59; t++)
{
uint32_t temp = MoveLeft(A, 5) + Maj(B, C, D) + E + W[t] + K[2];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
for (t = 60; t <= 79; t++)
{
uint32_t temp = MoveLeft(A, 5) + Parity(B, C, D) + E + W[t] + K[3];
E = D;
D = C;
C = MoveLeft(B, 30);
B = A;
A = temp;
}
/* e. Let H0 = H0 + A, H1 = H1 + B, H2 = H2 + C, H3 = H3 + D, H4 = H4 + E. */
H0 = H0 + A;
H1 = H1 + B;
H2 = H2 + C;
H3 = H3 + D;
H4 = H4 + E;
}
// step 5: 输出ABCD
uint32_t* pOut = (uint8_t*)out;
pOut[0] = __bswap_32(H0);
pOut[1] = __bswap_32(H1);
pOut[2] = __bswap_32(H2);
pOut[3] = __bswap_32(H3);
pOut[4] = __bswap_32(H4);
free(X);
return 0;
}
int main()
{
unsigned char digest[20] = { 0 };
sha1(digest, "Hello World!", strlen("Hello World!"));
return 0;
}