In [1]:
name = 'admin'
print("name=", name)
name1 = name
print("name1=", name1)
In [2]:
name2 = 'admin'
print("name2=", name2)
In [3]:
print(id(name), name)
print(id(name1), name1)
print(id(name2), name2)

In [4]:
name2 = name
print(name == name2)
print(id(name) == id(name2))
In [5]:
name2 = "admin1"
print(id(name), name)
print(id(name2), name2)
print(name == name2)
print(id(name) == id(name2))
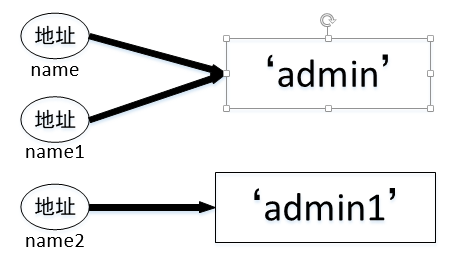
上面两块代码验证了在python系统中,变量会共用相同的值的内存。
1.当name2的值与name的值为“admin”时,name2与name对象的内存地址相同。
2.当name2的值改变为“admin1”时,name2对象的内存地址将会改变了¶
Python的内存管理主要有三种机制:引入计数机制、垃圾回收机制和内存池机制。
引入技术机制:在python内部,通过引入技术来保持追踪内存中的对象,python内部记录对象有多少个引用,即引用计数,当对象被创建使就创建一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它将被垃圾回收。
垃圾回收机制:当内存中不再使用该内存部分时,垃圾收集器就会把它们清理掉。它会去检查引用计数为0的对象,然后清除其所在的内存的空间。
内存池机制:在Python中,许多时候申请的内存都是小块的内存,这些小块内存在申请后,很快又会被释放,由于这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制。这就意味着Python在运行期间会大量地执行malloc和free的操作,频繁地在用户态和核心态之间进行切换,这将严重影响Python的执行效率。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。内存池的概念就是预先在内存中申请一定数量的,大小相等的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给这个需求,不够了之后再申请新的内存。这样做最显著的优势就是能够减少内存碎片,提升效率。内存池的实现方式有很多,性能和适用范围也不一样。
下面通过三个步骤分析内存管理和释放的过程:
In [6]:
name2 = 'admin1'
In [7]:
name1 = name2
print(id(name1), name1)
print(id(name2), name2)
print(id(name), name)
In [8]:
name = 'admin1'
print(id(name1), name1)
print(id(name2), name2)
print(id(name),name)
In [9]:
name = 'admin'
print(id(name1), name1)
print(id(name2), name2)
print(id(name),name)