原文
https://blog.csdn.net/maokelong95/article/details/81362837?utm_source=blogxgwz5
[NVM Programming] A Brief Guidance: How to Issue CLFLUSH, CLFLUSHOPT,CLWB, NTSTORE, LFENCE, MFENCE, SFENCE .etc via compilers’ intrinsic functions
日志:
- 2019-04-15: 新增指令顺序约束表;
- 2019-01-12: 更新指令支持现状;
- 2018-08-02: 提交了第一版;
1. 案例速览
1.1. 以使用 CLFLUSH 为例
- 编码(文件名为
clflush_demo.c)#include <x86intrin.h> // GCC 内置函数集(针对 x86 平台)int main(int argc, char const *argv[]) {
int data = 5;
_mm_clflush(&data); // GCC 内置的 clflush
return 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 编译
gcc clflush_demo.c -msse2 # 如何确定 -m* 请参阅第二章- 1
- 运行
1.2. 以使用 CLFLUSHOPT 为例
- 编码(文件名为
clflushopt_demo.c)#include <x86intrin.h> // GCC 内置函数集(针对 x86 平台)int main(int argc, char const *argv[]) {
int data = 5;
_mm_clflushopt(&data); // GCC 内置的 clflushopt
return 0;
} - 编译
gcc clflushopt_demo.c -mclflushopt # 如何确定 -m* 请参阅第二章 - 运行
2. 你可能想问的问题
-
如果不使用
x86intrin.h头文件会有什么影响?
将提醒函数未声明,如:warning: implicit declaration of function ‘_mm_clflushopt’ [-Wimplicit-function-declaration]; -
如果在编译时不使用 -m* 会有什么影响?
该选项告诉编译器当前使用了哪些处理器扩展指令,如果不指定将无法通过编译,如:error: inlining failed in call to always_inline ‘_mm_clflushopt’: target specific option mismatch -
如何确定 -m* 中的 * ?
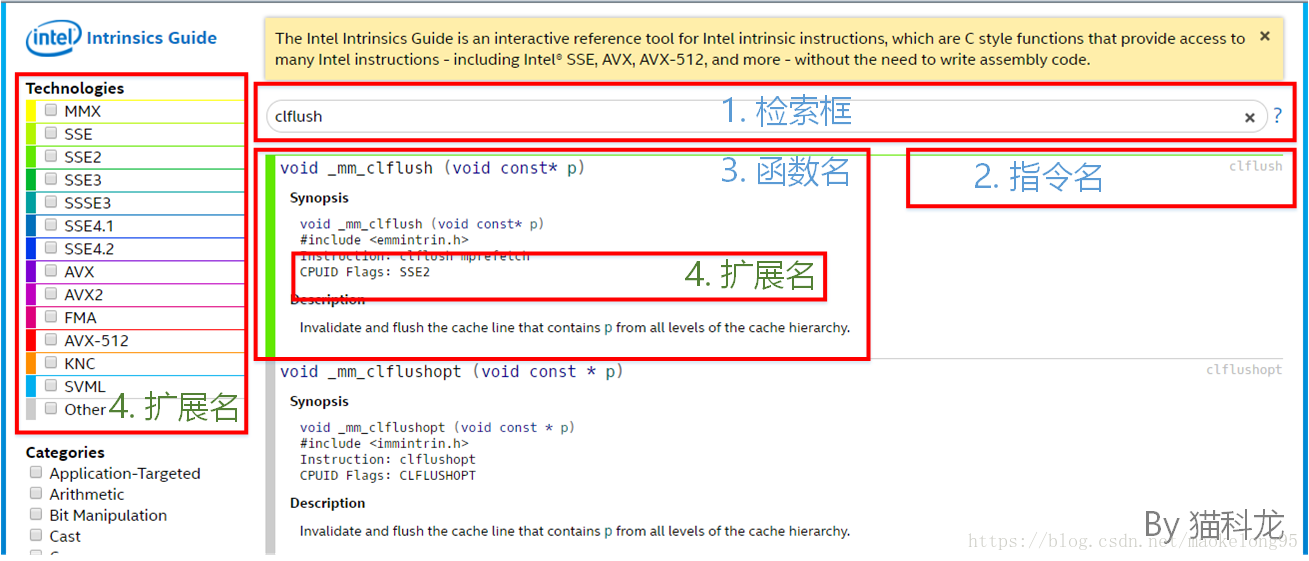
总结流程如下:- 打开 Intel Intrinsic Guide,并检索目标指令;如,检索 CLFLUSH;
- 找到指令对应的函数;如,CLFLUSH 对应函数名为
_mm_clflush; - 确定指令对应指令集扩展,可通过条目详情页的 “CPUID FLAGs” 或通过颜色比对;如 CLFLUSH 隶属 “SSE2”,而 CLFLUSHOPT 这种放在 Other 里的就是自己的指令名了;
- * 即指令集扩展名;
-
编译时报错,说,error: unrecognized command line option “-mclflushopt”,是为什么?
可能是因为编译器版本太低,我试过 5.4 和 7.3 版的 GCC,编译均通过; -
运行时出错,说,Illegal instruction (core dumped),是为什么?
你的处理器架构不支持该指令。
3. 常用非易失内存编程指令介绍
Note:
- 支持现状的格式为 Processor Generation Introduction. (Supported in Microarchitecture);数据获取自 Intel® Architecture Instruction Set Extensions and Future Features Programming Reference。
- TBD = To Be Discussed,未固定。
-
CLFLUSH。CLFLUSH(Cache Line Flush,缓存行刷回)能够把指定缓存行(Cache Line)从所有级缓存中淘汰,若该缓存行中的数据被修改过,则将该数据写入主存;支持现状:目前主流处理器均支持该指令。
-
CLFLUSHOPT。CLFLUSHOPT(Optimized CLFLUSH,优化的缓存行刷回)作用与 CLFLUSH 相似,但其之间的指令级并行度更高,比如在访问不同 CacheLine 时,CLFLUHOPT 可以乱序执行。支持现状:
- Intel® Xeon® Processor Scalable Family. (Skylake Server and later)
- 6th Generation Intel® Core™ processor family. (Skylake and later)
- Intel® Atom™ processor. (Goldmont and later)
-
CLWB。CLWB(Cache Line Write Back,缓存行写回)作用与 CLFLUSHOPT 相似,但在将缓存行中的数据写回之后,该缓存行仍将呈现为未被修改过的状态;支持现状:
- Intel® Xeon® Processor Scalable Family. (Skylake Server and later)
- TBD. (Ice Lake and later)
- TBD. (Future Tremont and later)
-
NT STORES。NT STORES(NonTemporal stores) 是一系列用于存储不同字长数据的指令,其包括 MOVNTDQ 等。NT Stores 指令在传输数据时能够绕过缓存,而直接将数据写入主存。
-
PCOMMIT。已经弃用。该指令用于将已经通过前述指令刷到内存控制器的数据提交到主存,该指令现因强制要求所有平台实现 ADR 特性而不再具有使用价值,从而被废弃。所谓 ADR(Asynchronous DRAM Refresh,异步 DRAM 刷新)特性原本为 DRAM-based NVDIMM 设计,其通过大电容和特定时序来确保掉电后内存控制器及部分缓存中的数据顺利写入非易失内存。
-
FENCE。FENCE 指令,也称内存屏障(Memory Barrier),起着约束其前后访存指令之间相对顺序的作用。其包括 LFENCE(约束 Load 指令), MFENCE(约束 L/S 指令), SFENCE(约束 Store 指令)。希望从更深层次去理解这个指令的意义,可以翻翻我之前的博客:内存模型系列(上)- 内存一致性模型(Memory Consistency),其对应 Safety Net 部分。
注:以上指令均为 X86 指令,arm 处理器的指令集我未调研过,因此此处不作介绍。
3. 常用非易失内存编程指令顺序约束表
我们知道,Out-of-Order 处理器可能会乱序执行指令以尽可能增大地处理器的指令吞吐率。但这种 Re-order 可能并不是我们所期望的。我们唯有充分了解这些非易失编程指令的顺序约束,才能做到完全把控处理器的访存行为。
为了清晰地将指令间的顺序约束表现出来,这里草拟了一张介绍指令顺序约束的表格。其中每行表示一个是否与之排序的项目,而每列表示一条非易失编程指令。
| 序项指令 | CLFLUSH | CLFLUSHOPT | CLWB | MOVNT1 |
|---|---|---|---|---|
| CLFLUSH | Y | N | N | ? |
| CLFLUSHOPT | N | N | N | ? |
| CLWB | ? | ? | N | ? |
| MOVNT | ? | ? | ? | N |
| writes | Y | N | N | N |
| Locked RMW | Y | Y | Y | Y |
| fence | Y | Y | Y | Y |
注意:
- 对同一 cacheline 操作时仍将排序,但 MOVNT 未见相关描述;
- ? 部分表示已有资料中未见相关描述;
- 上面的 fence 指的是 store-fencing operations,包括 SFENCE 及 MFENCE;
- 上面的 Locked RMW 包括 XCHG 及 LOCK-prefixed instructions,详见 内存模型系列(上)- 内存一致性模型(Memory Consistency)。
Intel® 64 and IA-32 Architectures Optimization Reference Manual. 7.4.1 The Non-temporal Store Instructions. ↩︎
</div>