注:面向数据编程文章已更新成markdown形式,并添加修改了一些内容,而本文则作为旧文不再更新维护。
最新版博文如下:
【游戏设计模式——面向数据编程(新)】 https://www.cnblogs.com/KillerAery/p/11746639.html
前言:随着软件需求的日益复杂发展,远古时期面的向过程编程思想才渐渐萌生了面向对象编程思想。
当人们发现面向对象在应对高层软件的种种好处时,越来越沉醉于面向对象,热衷于研究如何更加优雅地抽象出对象。
然而现代开发中渐渐发现面向对象编程层层抽象造成臃肿,导致运行效率降低,而这是性能要求高的游戏编程领域不想看到的。
于是现代游戏编程中,面向数据编程的思想越来越被接受(例如Unity2018更新的ECS框架就是一种面向数据思想的框架)。
面向数据编程是什么?
先来一个简单的比较:
- 面向过程思想:考虑解决问题所需的各个步骤(函数)。
- 面向对象思想:考虑解决问题所需的各个模型(类)。
- 面向数据思想:考虑数据的存取及布局为核心思想(数据)。
那么所谓的考虑数据存储/布局是什么意思呢?
先引入一个有关CPU处理数据的概念:CPU多级缓存。
CPU多级缓存(CPU cache)
什么是CPU缓存:
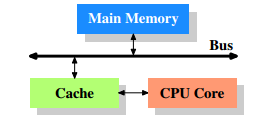
- 更详细来说,结构应该是:CPU<---->寄存器<---->CPU缓存<---->内存
- 可以看到CPU缓存是介于内存和寄存器之间的一个存储区域,此外它存储空间比内存小,比寄存器大。
为什么需要CPU多级缓存:
- CPU的运行频率太快了,而CPU访问内存的速度很慢,这样在处理器时钟周期内,CPU常常需要等待寄存器读取内存,浪费时间。
- 而CPU访问CPU缓存则速度快很多。为了缓解CPU和内存之间速度的不匹配问题,CPU缓存则预先存储好潜在可能会访问的内存数据。
CPU多级缓存预先存的是什么:
- 时间局部性:如果某个数据被访问,那么在不久的将来它很可能再次被访问。
- 空间局部性:如果某个数据被访问,那么与它相邻的数据很快也能被访问。
- CPU多级缓存根据这两个特点,一般存储的是访问过的数据+访问数据的相邻数据。
CPU缓存命中/未命中:
- CPU把待处理的数据或已处理的数据存入缓存指定的地址中,如果即将要处理的数据已经存在此地址了,就叫作CPU缓存命中。
- 如果CPU缓存未命中,就转到内存地址访问。
提高CPU缓存命中率
要尽可能提高CPU缓存命中率,就是要尽量让使用的数据连续在一起。
由于面向数据编程技巧很多,本文篇幅有限,只介绍部分。
使用连续数组存储要批处理的对象
1,传统的组件模式,往往让游戏对象持有一个或多个组件的引用数据(指针数据)。
(一个典型的游戏对象类,包含了2种组件的指针)
class GameObject {
//....GameObject的属性
Component1* m_component1;
Component2* m_component2;
};
下面一幅图显示了这种传统模式的结构:
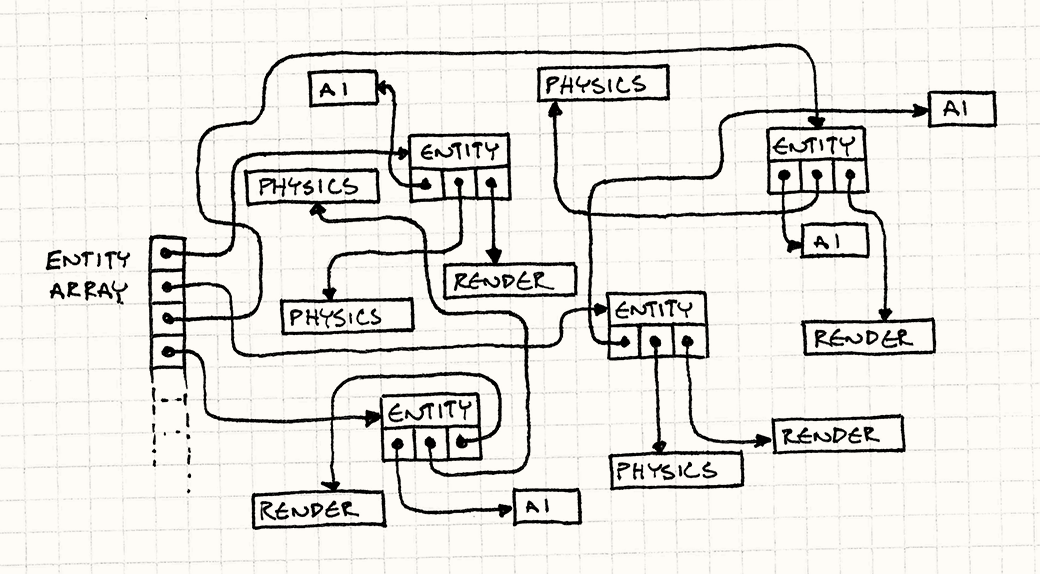
游戏对象/组件往往是批处理操作较多(每帧更新/渲染/或其他操作)的对象。
这个传统结构相应的每帧更新代码:
GameObject g[MAX_GAMEOBJECT_NUM]; for(int i = 0; i < GameObjectsNum; ++i) { g[i].update(); if(g[i].componet1 != nullptr)g[i].componet1->update(); if(g[i].componet2 != nullptr)g[i].componet2->update(); }
而根据图中可以看到,这种指来指去的结构对CPU缓存极其不友好:为了访问组件总是跳转到不相邻的内存。
倘若游戏对象和组件的更新顺序不影响游戏逻辑,则一个可行的办法是将他们都以连续数组形式存在。
注意是对象数组,而不是指针数组。如果是指针数组的话,这对CPU缓存命中没有意义(因为要通过指针跳转到不相邻的内存)。
GameObject g[MAX_GAMEOBJECT_NUM];
Component1 a[MAX_COMPONENT_NUM];
Component2 b[MAX_COMPONENT_NUM];
(连续数组存储能让下面的批处理中CPU缓存命中率较高)
for (int i = 0; i < GameObjectsNum; ++i) { g[i].update(); } for (int i = 0; i < Componet1Num; ++i) { a[i].update(); } for (int i = 0; i < Componet2Num; ++i) { b[i].update(); }
2,这是一个简单的粒子系统:
const int MAX_PARTICLE_NUM = 3000; //粒子类 class Particle { private: bool active; Vec3 position; Vec3 velocity; //....其它粒子所需方法 }; Particle particles[MAX_PARTICLE_NUM]; int particleNum;
它使用了典型的lazy策略,当要删除一个粒子时,只需改变active标记,无需移动内存。
然后利用标记判断,每帧更新的时候可以略过删除掉的粒子。
当需要创建新粒子时,只需要找到第一个被删除掉的粒子,更改其属性即可。
for (int i = 0; i < particleNum; ++i) { if (particles[i].isActive()) { particles[i].update(); } }
表面上看这很科学,实际上这样做CPU缓存命中率不高:每次批处理CPU缓存都加载过很多不会用到的粒子数据(标记被删除的粒子)。
一个可行的方法是:当要删除粒子时,将队列尾的粒子内存复制到该粒子的位置,并记录减少后的粒子数量。
(移动内存(复制内存)操作是程序员最不想看到的,但是实际执行批处理带来的速度提升相比删除的开销多的非常多,除非你移动的内存对象大小实在大到令人发指)
particles[i] = particles[particleNum];
particleNum--;
这样我们就可以保证在这个粒子批量更新操作中,CPU缓存总是能以高命中率击中。
for (int i = 0; i < particleNum; ++i) { particles[i].update(); }
冷数据/热数据分割
有人可能认为这样能最大程度利用CPU缓存:把一个对象所有要用的数据(包括组件数据)都塞进一个类里,而没有任何用指针或引用的形式间接存储数据。
实际上这个想法是错误的,我们不能忽视一个问题:CPU缓存的存储空间是有限的
于是我们希望CPU缓存存储的是经常使用的数据,而不是那些少用的数据。这就引入了冷数据/热数据分割的概念了。
热数据:经常要操作使用的数据,我们一般可以直接作为可直接访问的成员变量。
冷数据:比较少用的数据,我们一般以引用/指针来间接访问(即存储的是指针或者引用)。
一个栗子:对于人类来说,生命值位置速度都是经常需要操作的变量,是热数据;
而掉落物对象只有人类死亡的时候才需要用到,所以是冷数据;
class Human { private: float health; float power; Vec3 position; Vec3 velocity; LootDrop* drop; //.... }; class LootDrop{ Item[2] itemsToDrop; float chance; //.... };
频繁调用的函数尽可能不要做成虚函数
C++的虚函数机制,简单来说是两次地址跳转的函数调用,这对CPU缓存十分不友好,往往命中失败。
实际上虚函数可以优雅解决很多面向对象的问题,然而在游戏程序如果有很多虚函数都要频繁调用(例如每帧调用),很容易引发性能问题。
解决方法是,把这些频繁调用的虚函数尽可能去除virtual特性(即做成普通成员函数),并避免调用基类对象的成员函数,代价是这样一改得改很多与之牵连代码。
所以最好一开始设计程序时,需要先想好哪些最好不要写成virtual函数。
这实际上就是在优雅与性能之间寻求一个平衡。
更多小细节(不常用)
面向数据编程还有更多小细节,但是这些都不常用,就只作为一种思考面向数据编程的另类角度。
对多维数组的遍历:int a[100][100];
for(int x=0;x<100;++x) for(int y=0;y<100;++y) a[x][y]; for(int y=0;y<100;++y) for(int x=0;x<100;++x) a[x][y];
内循环应该是对x递增还是对y递增比较快?答案是:对y递增比较快。
因为对 y 的递增,结果是一个int大小的跳转,也就是说容易访问到相邻的内存,即容易击中CPU缓存。
而对 x 的递增,结果是100个int大小的跳转,不容易击中CPU。
而内循环如果是y的话,那么就能内外循环总共递增100*100次y。
但内循环如果是x的话,那么就内外循环总共只能递增100次y,相比上者,CPU击中比较少。
额外
该更新一下我对面向对象和面向数据的看法:
先说结论:应该兼有。因为游戏程序是一个既需要高性能又复杂的工程。
使用面向对象的游戏程序新手,常常就有一个问题:过度设计/过度抽象,什么都想用设计模式封装一下抽象一下。
这就很容易导致一些过度设计/过度抽象导致游戏性能太差。
博主现在的项目风格都比较偏向面向数据思想,尽量减少虚函数的使用,多利用数据组合成对象,而不是重写各种基类虚函数。
对于一些数据结构的考量,也尽量偏多使用连续存储的结构(例如数组)。
如何兼有两种思想,这种玄学的问题可能得靠自己去感悟,多尝试和测试性能差别。
游戏设计模式系列-其他文章: