由于遗传算法是由进化论和遗传学机理而产生的搜索算法,所以在这个算法中会用到很多生物遗传学知识,下面是我们将会用来的一些术语说明:
一、染色体(Chronmosome)
染色体又可以叫做基因型个体(individuals),一定数量的个体组成了群体(population),群体中个体的数量叫做群体大小。
二、基因(Gene)
基因是串中的元素,基因用于表示个体的特征。例如有一个串S=1011,则其中的1,0,1,1这4个元素分别称为基因。它们的值称为等位基因(Alletes)。
三、基因地点(Locus)
基因地点在算法中表示一个基因在串中的位置称为基因位置(Gene Position),有时也简称基因位。基因位置由串的左向右计算,例如在串 S=1101 中,0的基因位置是3。
四、基因特征值(Gene Feature)
在用串表示整数时,基因的特征值与二进制数的权一致;例如在串 S=1011 中,基因位置3中的1,它的基因特征值为8;基因位置1中的1,它的基因特征值为2。
五、适应度(Fitness)
各个个体对环境的适应程度叫做适应度(fitness)。为了体现染色体的适应能力,引入了对问题中的每一个染色体都能进行度量的函数,叫适应度函数. 这个函数是计算个体在群体中被使用的概率。
霍兰德(Holland)教授最初提出的算法也叫简单遗传算法,简单遗传算法的遗传操作主要有三种:选择(selection)、交叉(crossover)、变异(mutation)这也是遗传算法中最常用的三种算法:
1.选择(selection)
选择操作也叫复制操作,从群体中按个体的适应度函数值选择出较适应环境的个体。一般地说,选择将使适应度高的个体繁殖下一代的数目较多,而适应度较小的个体,繁殖下一代的数目较少,甚至被淘汰。最通常的实现方法是轮盘赌(roulette wheel)模型。令Σfi表示群体的适应度值之总和,fi表示种群中第i个染色体的适应度值,它被选择的概率正好为其适应度值所占份额fi/Σfi。
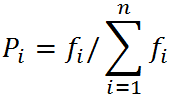
如果适应度值存在负数,我的方法是采用以下公式:
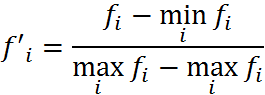
再计算概率和累计概率。
设想群体全部个体的适当性分数由一张饼图来代表 (见图)。
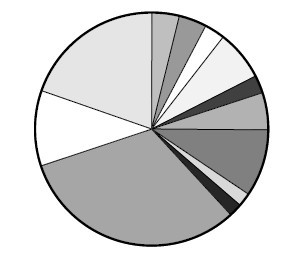
群体中每一染色体指定饼图中一个小块。块的大小与染色体的适应性分数成比例,适应性分数愈高,它在饼图中对应的小块所占面积也愈大。为了选取一个染色体,要做的就是旋转这个轮子,直到轮盘停止时,看指针停止在哪一块上,就选中与它对应的那个染色体。
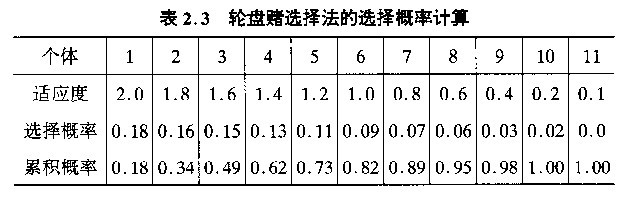
若产生随机数为0.81,则6号个体被选中。
2.交叉(Crossover)
交叉算子将被选中的两个个体的基因链按一定概率pc进行交叉,从而生成两个新的个体,交叉位置pc是随机的。其中Pc是一个系统参数。根据问题的不同,交叉又为了单点交叉算子(Single Point Crossover)、双点交叉算子(Two Point Crossover)、均匀交叉算子 (Uniform Crossover),在此我们只讨论单点交叉的情况。
单点交叉操作的简单方式是将被选择出的两个个体S1和S2作为父母个体,将两者的部分基因码值进行交换。假设如下两个8位的个体:
S1:1000 1111
S2:1110 1100
产生一个在1到7之间的随机数c,假如现在产生的是2,将S1和S2的低二位交换,后代P1为1100 1111,P2为10101100。在这里高二位与低二位是按从左到右的顺序还是从右到左的顺序,自我感觉效果是一样的,不过也没具体证明,网上是按从右到左的顺序,在这篇文章中的定义都是从左到右的。
3.变异(Mutation)
这是在选中的个体中,将新个体的基因链的各位按概率pm进行异向转化,最简单方式是改变串上某个位置数值。对二进制编码来说将0与1互换:0变异为1,1变异为0。
如下8位二进制编码:
1 1 1 0 1 1 0 0
随机产生一个1至8之间的数i,假如现在k=6,对从左往右的第6位进行变异操作,将原来的1变为0,得到如下串:
1 1 1 0 1 0 0 0
4.精英主义 (Elitism)
仅仅从产生的子代中选择基因去构造新的种群可能会丢失掉上一代种群中的很多信息。也就是说当利用交叉和变异产生新的一代时,我们有很大的可能把在某个中间步骤中得到的最优解丢失。在此我们使用精英主义(Elitism)方法,在每一次产生新的一代时,我们首先把当前最优解原封不动的复制到新的一代中,其他步骤不变。这样任何时刻产生的一个最优解都可以存活到遗传算法结束。不过这篇文章的代码中并没实现这点,以后有机会有时间再贴上代码。
说简单点遗传算法就是遍历搜索空间或连接池,从中找出最优的解。搜索空间中全部都是个体,而群体为搜索空间的一个子集。并不是所有被选择了的染色体都要进行交叉操作和变异操作,而是以一定的概率进行,一般在程序设计中交叉发生的概率要比变异发生的概率选取得大若干个数量级。大部分遗传算法的步骤都很类似,常使用如下参数:
Fitness函数:在这篇文章中为:
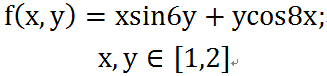
Fitnessthreshold(适应度阈值):适合度中的设定的阀值,当最优个体的适应度达到给定的阀值,或者最优个体的适应度和群体适应度不再上升时(变化率为零),则算法的迭代过程收敛、算法结束。否则,用经过选择、交叉、变异所得到的新一代群体取代上一代群体,并返回到选择操作处继续循环执行。这篇文章中没使用这个阈值。
P:种群的染色体总数叫种群规模,它对算法的效率有明显的影响,其长度等于它包含的个体数量。太小时难以求出最优解,太大则增长收敛时间导致程序运行时间长。对不同的问题可能有各自适合的种群规模,通常种群规模为 30 至 160。这篇文章中使用的群体规模为20。
pc:在循环中进行交叉操作所用到的概率。交叉概率(Pc)一般取0.6至0.95之间的值,Pc太小时难以向前搜索,太大则容易破坏高适应值的结构。这篇文章中的交叉概率为0.65。
Pm:变异概率,从个体群中产生变异的概率,变异概率一般取0.01至0.03之间的值变异概率Pm太小时难以产生新的基因结构,太大使遗传算法成了单纯的随机搜索。这篇文章中的编译概率为0.01。
另一个系统参数是个体的长度,有定长和变长两种。它对算法的性能也有影响。由于GA是一个概率过程,所以每次迭代的情况是不一样的,系统参数不同,迭代情况也不同。这篇文章中并没用到这个。
了解了上面的基本参数,下面我们来看看遗传算法的基本步骤。
基本过程为:
- 对待解决问题进行编码,我们将问题结构变换为位串形式编码表示的过程叫编码;而相反将位串形式编码表示变换为原问题结构的过程叫译码。
- 随机初始化群体P(0):=(p1, p2, … pn);
- 计算群体上每个个体的适应度值(Fitness)
- 评估适应度,对当前群体P(t)中每个个体Pi计算其适应度F(Pi),适应度表示了该个体的性能好坏
- 按由个体适应度值所决定的某个规则应用选择算子产生中间代Pr(t)
- 依照Pc选择个体进行交叉操作
- 仿照Pm对繁殖个体进行变异操作
- 没有满足某种停止条件,则转第3步,否则进入9
- 输出种群中适应度值最优的个体
程序的停止条件最简单的有如下二种:完成了预先给定的进化代数则停止;种群中的最优个体在连续若干代没有改进或平均适应度在连续若干代基本没有改进时停止。
代码实现
#include <iostream> #include <time.h> #include <stdlib.h> #include <cmath> using namespace std; const int M = 8; //染色体的数目,群体的大小 const int T = 7; //终止代数 const double pc = 0.6; //交叉概率 const double pm = 0.01; //变异概率 struct Population { int g[20]; //将x,y的取值区间分为(2^10-1)份,用20位二进制位表示份数 double x,y; double fit; //适应函数值 double nfit; double sumfit; //适应值总和 }; class gaModel{ public: int rand01() const; //随机生成01 double randab(double,double) const; //随即生成[a,b)的一个数 void initial(Population *); // 初始化函数 void evalueFitness(Population *); // 计算适应度 void select(Population *); // 选择复制函数 void crossover(Population *); // 交叉函数 void mutation(Population *); // 变异函数 void decoding(Population *); // 解码函数 void print(Population *); // 显示函数 Population p[M]; };
#include "GaModel.h" int gaModel::rand01() const{ int r = 0; double q = 0.0; q = rand()/(RAND_MAX + 0.0); if(q < 0.5) r = 0; else r = 1; return r; } double gaModel::randab(double a,double b) const{ double c,r; c = b - a; r = a + c * rand()/(RAND_MAX+1.0); return r; } void gaModel::initial(Population *t){ Population *po; srand(time(0)); for(po = t; po < t + M; po++) //初始化群体 for(int j = 0; j < 20; j++) (*po).g[j] = rand01(); } void gaModel::evalueFitness(Population *t){ double f,xx,yy,temp = 0.0; Population *po1,*po2; double fmax = 0,fmin = 9999999999; for(po1 = t; po1 < t + M; po1++){ //计算适应值 xx = (*po1).x; yy = (*po1).y; f = xx * sin(6 * yy) + yy * cos(8 * xx);//优化函数 (*po1).fit = f; //cout << (*po1).fit << "测试" << endl; } for(po1 = t; po1 < t + M; po1++){ if((*po1).fit > fmax) fmax = (*po1).fit; if((*po1).fit < fmin) fmin = (*po1).fit; } for(po1 = t; po1 < t + M; po1++){ (*po1).nfit = ((*po1).fit - fmin) / (fmax - fmin + 1); } for(po1 = t; po1 < t + M; po1++){ //计算累计适应值,为的是之后的轮盘赌模型 for(po2 = t; po2 <= po1; po2++) temp = temp + (*po2).nfit; (*po1).sumfit = temp; temp = 0.0; } } void gaModel::select(Population *t){ //轮盘赌选择 int i = 0; Population pt[M],*po; double s; srand(time(0)); while(i < M){ s = randab((*t).sumfit,(*(t + M - 1)).sumfit); for(po = t; po < t + M; po++){ if((*po).sumfit >= s){ pt[i] = (*po); break; } else continue; } i++; } for(i = 0; i < M; i++) for(int j = 0; j < 20; j++) t[i].g[j] = pt[i].g[j]; } void gaModel::crossover(Population *t){ //交叉函数 Population *po; double q; //存放一个0到1的随机数,判定是否交叉 int d,e,tem[20]; //d存放一个从1到19的一个随机整数,用来确定交叉的位置 int k = 0,rpo[5] = {99,99,99,99,99};//e存放从0到M的一个随机且与当前t[i]中i不同的整数,用来确定交叉的对象 bool tf = true; //rpo存放每次的e,确保所有的染色体都会交叉 srand(time(0)); for(po = t; po < t + M/2; po++){ q = rand() / (RAND_MAX + 0.0); while(true){ //避免自己与自己交叉和交叉过的染色体继续交叉 tf = true; e = rand() % M; for(int j = 0; j < M; j++){ if(e == rpo[j]) tf = false; } if(t + e != po && tf) break; } if(q < pc){ d = 1 + rand() % 19; //确定交叉位置 for(int i = d; i < 20; i++){ tem[i] = (*po).g[i]; (*po).g[i] = (*(t+e)).g[i]; (*(t+e)).g[i] = tem[i]; } } rpo[k] = e; k++; } } void gaModel::mutation(Population *t){ //变异函数 double q; Population *po; srand(time(0)); for(po = t; po < t + M; po++){ int i = 0; while(i < 20){ q = rand() / (RAND_MAX + 0.0); if(q < pm) (*po).g[i] = 1 - (*po).g[i]; i++; } } } void gaModel::decoding(Population *t){ //解码函数 Population *po; int temp,s1 = 0, s2 = 0; float m,n,dit; n = ldexp(1.0,10); dit = (2 - 1) / (n - 1); for(po = t; po < t + M; po++){ for(int i = 0; i < 10; i++){ temp = ldexp((*po).g[i]*1.0,i); s1 = s1 + temp; } m = 1 + s1 * dit; (*po).x = m; s1 = 0; for(int j = 10; j < 20; j++){ temp = ldexp((*po).g[j]*1.0,j-10); s2 = s2 + temp; } m = 1 + s2 * dit; (*po).y = m; s2 = 0; } } void gaModel::print(Population *t){ //显示函数 Population *po; for(po = t; po < t + M; po++){ for(int j = 0; j < 20; j++){ cout << (*po).g[j]; if((j+1)%5 == 0) cout << ' '; } cout << endl; cout << "x=" << (*po).x << ' ' << "y=" << (*po).y << ' ' << "fit=" << (*po).fit << ' ' << "nfit=" << (*po).nfit << ' ' << "sumfit=" << (*po).sumfit << endl; } }
#include "GaModel.h" int main(){ int kkk = 0; gaModel g1; int gen = 0; g1.initial(&(g1.p[0])); g1.print(&(g1.p[0])); cout << endl; g1.decoding(&(g1.p[0])); g1.print(&(g1.p[0])); cout << endl; g1.evalueFitness(&(g1.p[0])); g1.print(&(g1.p[0])); while(gen < T){ cout << "gen=" << gen + 1 << endl; g1.select(&(g1.p[0])); g1.decoding(&(g1.p[0])); g1.evalueFitness(&(g1.p[0])); cout << "selected!" << endl; g1.print(&(g1.p[0])); g1.crossover(&(g1.p[0])); g1.decoding(&(g1.p[0])); g1.evalueFitness(&(g1.p[0])); cout << "crossovered!" << endl; g1.print(&(g1.p[0])); g1.mutation(&(g1.p[0])); g1.decoding(&(g1.p[0])); g1.evalueFitness(&(g1.p[0])); cout << "mutated" << endl; g1.print(&(g1.p[0])); gen++; } cin >> kkk; }
结果显示
BUG已经修改。
参考:
1.http://www.madio.net/thread-170773-1-1.html
2.http://hi.baidu.com/wangxiaoliblog/item/562dfddd98d34e57d73aaee9
3.http://www.cppblog.com/twzheng/articles/21339.html