[BUAA软工]结对作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 北航软工 |
| 这个作业的要求在哪里 | 2019年软件工程基础-结对项目作业 |
| 我在这个课程的目标是 | 学习如何以团队的形式开发软件,提升个人软件开发能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 了解结对开发的流程,并亲自体验学习 |
| 项目地址 | https://github.com/sephyli/wordlist_BUAA |
| 项目作者信息 | 16231030 焦云鹏 、16231031 李天羽 |
运用Information Hiding, Interface Design, Loose Coupling方法设计接口
Information Hiding
In computer science, information hiding is the principle of segregation of the design decisions in a computer program that are most likely to change, thus protecting other parts of the program from extensive modification if the design decision is changed. The protection involves providing a stable interface which protects the remainder of the program from the implementation (the details that are most likely to change).
Written another way, information hiding is the ability to prevent certain aspects of a class or software component from being accessible to its clients, using either programming language features (like private variables) or an explicit exporting policy. --- Wikipedia
具体在程序中的体现是,我们使用面向对象的编程思想,通过调用类的Public成员函数的方式,执行程序的核心逻辑。在这个过程中,我们通过将一些不应该被外部更改的成员属性(如一个单词的具体信息),设计为私有成员,并设计Public成员函数,作为访问的接口(无写权限),从而达到了Information Hiding思想中的对于信息保护的需求。
Interface Design
User interface design (UI) or user interface engineering is the design of user interfaces for machines and software, such as computers, home appliances, mobile devices, and other electronic devices, with the focus on maximizing usability and the user experience. The goal of user interface design is to make the user's interaction as simple and efficient as possible, in terms of accomplishing user goals (user-centered design). --- Wikipedia
具体在程序中的体现是,我们通过封装核心逻辑为Core类,再通过Core类生成相应的dll,从而将int gen_chain_word(char* words[], int len, char* result[], char head, char tail, bool enable_loop),与int gen_chain_char(char* words[], int len, char* result[], char head, char tail, bool enable_loop)等核心功能函数设计为接口。这样的话,新的项目只需要设置相关路径,让Core.dll与Core.h的位置能被探测到,并设置Core.lib为工程的链接库。这样的话,就可以提供相关接口给别的程序使用。
Loose coupling
In computing and systems design a loosely coupled system is one in which each of its components has, or makes use of, little or no knowledge of the definitions of other separate components. Subareas include the coupling of classes, interfaces, data, and services.[1] Loose coupling is the opposite of tight coupling. --- Wikipedia
具体在程序中的体现是,我们在使用面向对象的思想设计程序的时候,将从属于一个类的成员方法与成员属性均放在这个类自己这里,而不要放在别的地方。这样的好处就是可以防止因为一个对象成员的改动,而导致很多不想管的类也要做调整,从而伤害程序的可维护性。
计算模块接口的设计与实现过程
类关键信息
- Word类
- 属性
- char head : 头字母
- char tail :尾字母
- int length :单词长度
- std::string s :单词
- bool use :标志是否被使用
- 方法
- Word(const char* s, int length) :构造函数
- 属性
- WordSet类
- 属性
- std::vector
set[26][26] :单词组
- std::vector
- 方法
- void append(Word w) :添加单词
- 属性
- Mode类
- 属性
- bool recurMode :单词成环模式
- bool headMode:头字母指定模式
- bool tailMode:尾字母指定模式
- bool wordNumMaxMode:单词数量最大模式
- bool charNumMaxMode:单词字母最多模式
- char head:指定的头字母
- char tail:指定的尾字母
- 方法
- void append(Word w) :添加单词
- 属性
- Searcher类
- 属性
- Data data :数据信息
- Mode mode :模式信息
- std::vector
maxWordList :历史max单词list - std::vector
tmpWordList :当前max单词list
- 方法
- bool exe() :执行函数
- 属性
程序分析
我们在拿到题目后,第一反应是直接使用暴力深搜解决问题。但是看到程序正确性要求中的300s运行时间限制(尽管我们现在也没能弄明白是针对-w模式,-c模式,还是两者兼有),我们意识到纯粹使用深搜是不合理的。在对算法进行一定的分析之后,我们意识到,不遍历所有满足条件的单词链,是不可能找出其中满足要求的最长/最多单词链的。也就是说,深度优先搜索,将会是我们必须要使用的算法。
完成这部分分析之后,我们将优化的视角投向了数据结构部分。我们注意到,程序要求单词链满足如下条件。
单词链的定义为:由至少2个单词组成,前一单词的尾字母为后一单词的首字母,且不存在重复单词
这就意味着,我们在从文件中读取单词的时候就该避免重复单词的读入。不仅如此,我们还设计了独到的数据结构来放置单词,从而实现了访查效率的最大化。
举例来说,我们在WordSet类中,设置了26*26的二位vector来放置头字母相同、尾字母相同的单词,并在vector中按照单词的长度来排列,这样的话,不管对于-w模式还是-c模式,都可以采取同一套访查算法。不仅如此,如此组织数据结构,可以让我们的核心搜索函数(深搜函数)快速通过找到以目标字母开头的单词,相比传统的深度优先搜索,我们在这一步的复杂度从O(N) 降到了O(1)。考虑到深搜核心函数的调用次数是一个随着单词链长度增长而成阶乘级增长的,我们的优化方法,应该来说也是有一定作用的。
类关系UML图

计算模块接口部分的性能改进
在构造数据结构时,我将问题的思维模式转变为一种带权重的有向图。如hello,即结点h到结点o的有向边,若-w模式,权重为1,-c则为5。那么我存下了每个节点到另一个节点的边的信息并以节点号进行索引,构造出了vector<Word> WordSet[26][26]这样的结构,每个vector内用权重进行排序。
由此问题便转变为了不允许重复节点和路径的最长路径问题。考虑过DP,但无法构造高效的子问题,及子问题合并时需要判断重复的路径和节点,猜测并不会提升效率。由此使用了深度优先搜索,在非-r模式,的复杂度约为26!这个数量级,因此构造出了最复杂的样例后,是绝无可能在300s之内完成计算的。由此放弃了在总体算法层次上的优化,仅仅追求最短的搜索路径和较小的访存开销。
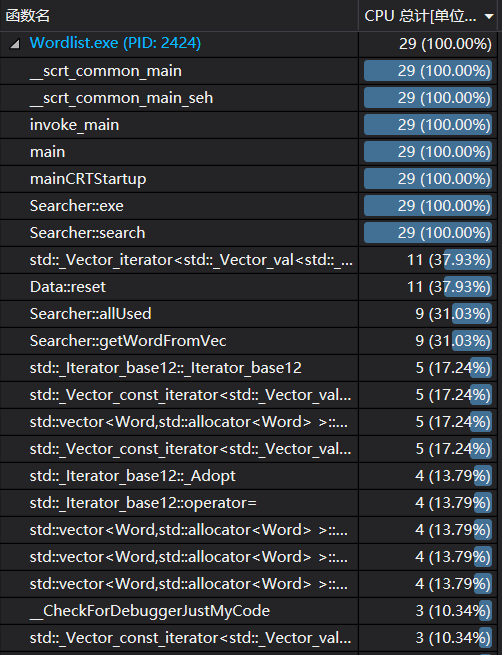
结果: 算法在-r模式下的100个词中,可以在20ms内完成单词链搜索。
性能统计图如下所示:
Design by Contract, Code Contract
Design by contract (DbC), also known as contract programming, programming by contract and design-by-contract programming, is an approach for designing software. It prescribes that software designers should define formal, precise and verifiable interface specifications for software components, which extend the ordinary definition of abstract data types with preconditions, postconditions and invariants. These specifications are referred to as "contracts", in accordance with a conceptual metaphor with the conditions and obligations of business contracts.
The DbC approach assumes all client components that invoke an operation on a server component will meet the preconditions specified as required for that operation. Where this assumption is considered too risky (as in multi-channel client-server or distributed computing) the opposite "defensive design" approach is taken, meaning that a server component tests (before or while processing a client's request) that all relevant preconditions hold true, and replies with a suitable error message if not. --- Wikipedia
这个概念与我在面向对象程序设计中所学到过的设计契约思想比较相似,都是要求调用它的客户模块都保证一定的进入条件,保证退出时给出特定的属性,即满足一定的先验条件与后验条件。
具体来看,在程序设计的时候,我们就遵循了这样的规范。例如,在进行Mode类设计的时候,对于set方法(即命令行信息赋值函数),程序就要求传入的参数是有意义的。这就是对于先验条件的实现。
程序在进行getWordFromVec函数实现的时候,需要返回一个满足条件的Word对象。但是,如果没有找到这样的Word对象,程序也不能什么都不做,而是应该通过调用Word的默认构造函数,返回一个空的Word。这样的话,就保证了getWordFromVec函数所约定的后验条件。
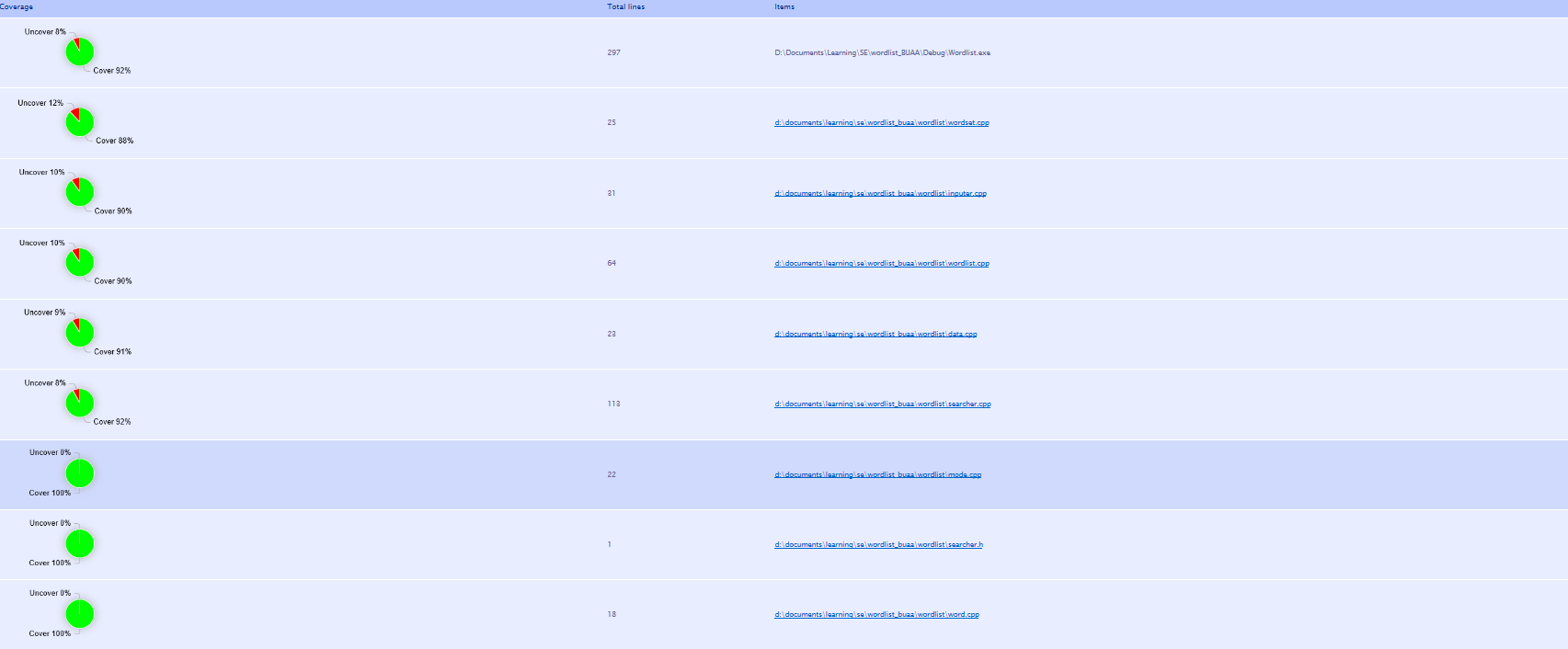
计算模块部分单元测试展示
使用工具为OpenCppCoverage。经过merge过后的结果展示:
单元测试部分代码:
TEST_METHOD(TestRecur)
{
FILE *fin;
fopen_s(&fin, "../test/recurtest1.txt", "r");
char *words[105], *result[105];
Inputer *inputer = new Inputer();
int wordNum = inputer->getWord(fin, words);
for (int i = 0; i < 105; i++) {
result[i] = new char(105);
}
int len = 0;
len = Core::gen_chain_char(words, wordNum, result, 0, 0, true);
Assert::AreEqual(len, 60);
}
在这个例子中,程序测试了Core::gen_chain_char接口,通过对文件·../test/recurtest1.txt内容测试,检查了在指定字母数最多,无头尾字母指定,允许单词环存在的情况下,得到的单词链长度的测试。
计算模块部分异常处理说明
单词超长
- 用途:检测输入文本中含有超过长度限制的单词的情况。
- 预期结果:通过try-catch的方法,捕获命令行报错信息。其中,
./test/testfile.txt文件中包含一个连续长度超过100的字母串。 - 单元测试如下:
TEST_METHOD(TestTooLongWord)
{
FILE *fin;
fopen_s(&fin, "../test/testfile.txt", "r");
char *words[10000], *result[105];
Inputer *inputer = new Inputer();
int wordNum = inputer->getWord(fin, words);
for (int i = 0; i < 105; i++) {
result[i] = new char(100);
}
int len = 0;
len = Core::gen_chain_word(words, wordNum, result, 0, 0, false);
}
隐含单词环
- 用途:检测输入文本中隐含单词环的情况。
- 预期结果:通过try-catch的方法,捕获命令行报错信息。其中,
./test/testfile.txt文件中包含若干个可以构成单词环的单词。 - 单元测试如下:
TEST_METHOD(TestNonRecureFalse)
{
FILE *fin;
fopen_s(&fin, "../test/testfile.txt", "r");
char *words[10000], *result[105];
Inputer *inputer = new Inputer();
int wordNum = inputer->getWord(fin, words);
for (int i = 0; i < 105; i++) {
result[i] = new char(100);
}
int len = 0;
len = Core::gen_chain_word(words, wordNum, result, 0, 0, false);
}
隐含单词环
- 用途:检测输入文本中隐含单词环的情况。
- 预期结果:通过try-catch的方法,捕获命令行报错信息。其中,
./test/testfile.txt文件中包含若干个可以构成单词环的单词。 - 单元测试如下:
TEST_METHOD(TestNonRecureFalse)
{
FILE *fin;
fopen_s(&fin, "../test/testfile.txt", "r");
char *words[10000], *result[105];
Inputer *inputer = new Inputer();
int wordNum = inputer->getWord(fin, words);
for (int i = 0; i < 105; i++) {
result[i] = new char(100);
}
int len = 0;
len = Core::gen_chain_word(words, wordNum, result, 0, 0, false);
}
单词链长度过短
- 用途:检测无法找到长度超过1的单词链的情况。
- 预期结果:通过try-catch的方法,捕获命令行报错信息。其中,
./test/testfile.txt文件中仅包含一个单词,或所包含的单词无法形成长度超过1的单词链。 - 单元测试如下:
TEST_METHOD(TestNonRecureFalse)
{
FILE *fin;
fopen_s(&fin, "../test/testfile.txt", "r");
char *words[10000], *result[105];
Inputer *inputer = new Inputer();
int wordNum = inputer->getWord(fin, words);
for (int i = 0; i < 105; i++) {
result[i] = new char(100);
}
int len = 0;
len = Core::gen_chain_word(words, wordNum, result, 0, 0, false);
}
命令行参数无法正确解析
- 用途:检测命令行参数无法正确解析的情况。
- 预期结果:通过try-catch的方法,捕获命令行报错信息。
文件读取错误
- 用途:检测无法找到文件的情况。
- 预期结果:通过try-catch的方法,捕获命令行报错信息。其中,
./test/testfile.txt文件不存在。 - 单元测试如下:
TEST_METHOD(TestNonRecureFalse)
{
FILE *fin;
fopen_s(&fin, "../test/testfile.txt", "r");
char *words[10000], *result[105];
Inputer *inputer = new Inputer();
int wordNum = inputer->getWord(fin, words);
for (int i = 0; i < 105; i++) {
result[i] = new char(100);
}
int len = 0;
len = Core::gen_chain_word(words, wordNum, result, 0, 0, false);
}
命令行模块描述
参数约定
程序支持通过命令行的方式输入参数以及文件位置信息。参数及其约定如下。
| 参数名字 | 参数意义 | 范围限制 | 用法示例 |
|---|---|---|---|
-w |
需要求出单词数量最多的单词链 | 绝对或相对路径 | 示例:Wordlist.exe -w input.txt [表示从input.txt中读取单词文本,计算单词数量最多的单词链] |
-c |
需要求出字母数量最多的单词链 | 绝对或相对路径 | 示例:Wordlist.exe -c input.txt [表示从input.txt中读取单词文本,计算字母数量最多的单词链] |
-h |
指定单词链首字母 | a-z,A-Z |
示例:Wordlist.exe -h a -w input.txt [表示从input.txt中读取单词文本,计算满足首字母为a的、单词数量最多的单词链] |
-t |
指定单词链尾字母 | a-z,A-Z |
示例:Wordlist.exe -t a -c input.txt [表示从input.txt中读取单词文本,计算满足尾字母为a的、字母数量最多的单词链] |
-r |
允许单词文本中隐含单词环 | NONE |
示例:Wordlist.exe -r -w input.txt [表示从input.txt中读取单词文本,计算单词数量最多的单词链,即使单词文本中隐含单词环也需要求解] |
实现过程
程序将命令行参数的提取部分放在了main函数中,通过引用int main(int agrc, char* agrv[])函数的方式,将命令行参数的数量读取在agrc中,分词读取在agrv[]中。
通过判断分词是否为-开头,来判断该词是否代表着命令行参数,在通过该词的第二个字母,判断具体属于哪个命令行参数(支持大小写)或者报错。同时通过判断第三个字母是否为�来判断参数是否过长。如果为参数有后续的范围限制,如-h 、-t 后需要指定开头、结尾的字母,则继续判断字母是否符合要求(个数为一个且在有意义)。
全部判断完成后,将判断的结果传入构造的Mode对象中,为后续程序所使用。
具体来看,程序声明了如下变量,在对不同参数做解析的时候,就针对不同情况对变量进行赋值,这样就收集全部的命令行参数信息。
bool rMode = false;
bool hMode = false;
bool tMode = false;
bool wMaxMode = false;
bool cMaxMode = false;
char h = 0;
char t = 0;
char filePath[1000] = "�";
再通过对Mode对象的赋值,从而实现了命令行模式的判断。
Mode *mode = new Mode();
mode->Set(rMode, hMode, tMode, wMaxMode, cMaxMode, h, t);
结对编程的优缺点
在结对编程模式下,一对程序员肩并肩地、平等地、互补地进行开发工作。两个程序员并排坐在一台电脑前,面对同一个显示器,使用同一个键盘,同一个鼠标一起工作。他们一起分析,一起设计,一起写测试用例,一起编码,一起单元测试,一起集成测试,一起写文档等。
关于结对编程是否是一种高效的编程手段,这我不好评说,我就来分享一下我和我的小伙伴在结对编程时的一些体会。
在第一周中,因为我的小伙伴白天要去公司实习,而我则要在白天做实验室的项目,所以程序开发的大部分环节其实没有遵循结对编程的要求。大多数情况下,我在白天实现我们在前一天晚上所共同设计的部分,在下午或晚上则由他来审查我的代码,做一些单元测试。到了我们都有时间的晚上,才能共同坐在同一个电脑前,像结对编程要求的那样,针对我们所实现的不同部分,做协调,并构思第二天的工作。
而到了第二周,情况有些变化,我们发现有一些东西需要我们共同探索,例如如何生成dll模块,以及如何对程序进行全覆盖的单元测试。这时候,我们拿出了统一的时间,坐在了电脑前,完成了结对编程。
与各自分开编程所不同的是,我们代码的错误率有了明显的下降,单元测试的通过率变高了。不仅如此,在实现的过程之中,由于有了“领航员”的存在,我们在进行类的实现的时候更加高效了,我们思考的更加全面,类方法与属性的设置能更好地满足低耦合、高内聚的要求,整体返工的次数也没有了。在“驾驶员”感到疲惫的时候,我们可以从容地进行角色互换,从而更持久的完成程序的实现。唯一美中不足的是,我们用于结对编程的时间不是很多,如果在第一周就能这样做的话,我们第二周的工作无疑会轻松很对:)
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| · Estimate | · 估计这个任务需要多少时间 | 5 | 0 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 80 | 60 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 0 |
| · Design | · 具体设计 | 90 | 60 |
| · Coding | · 具体编码 | 180 | 120 |
| · Code Review | · 代码复审 | 120 | 180 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 60 | 20 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 0 | 0 |
| 合计 | 665 | 620 |
结对编程照片
