1、定义模板创建索引:
首先定义好一个模板的例子
{
"order":14,
"template":"ids-1",
"state":"open",
"settings":{
"number_of_shards":1
},
"mappings":{
"warnning":{
"properties":{
"name":{
"type":"keyword"
},
"createtime":{
"type":"date",
"format":"strict_date_optional_time||epoch_millis"
},
"category":{
"type":"keyword"
},
"srcip":{
"type":"keyword"
},
"dstip":{
"type":"keyword"
}
}
}
}
}
然后使用PUT方法,发送给Elasticsearch。可以使用下图插件:
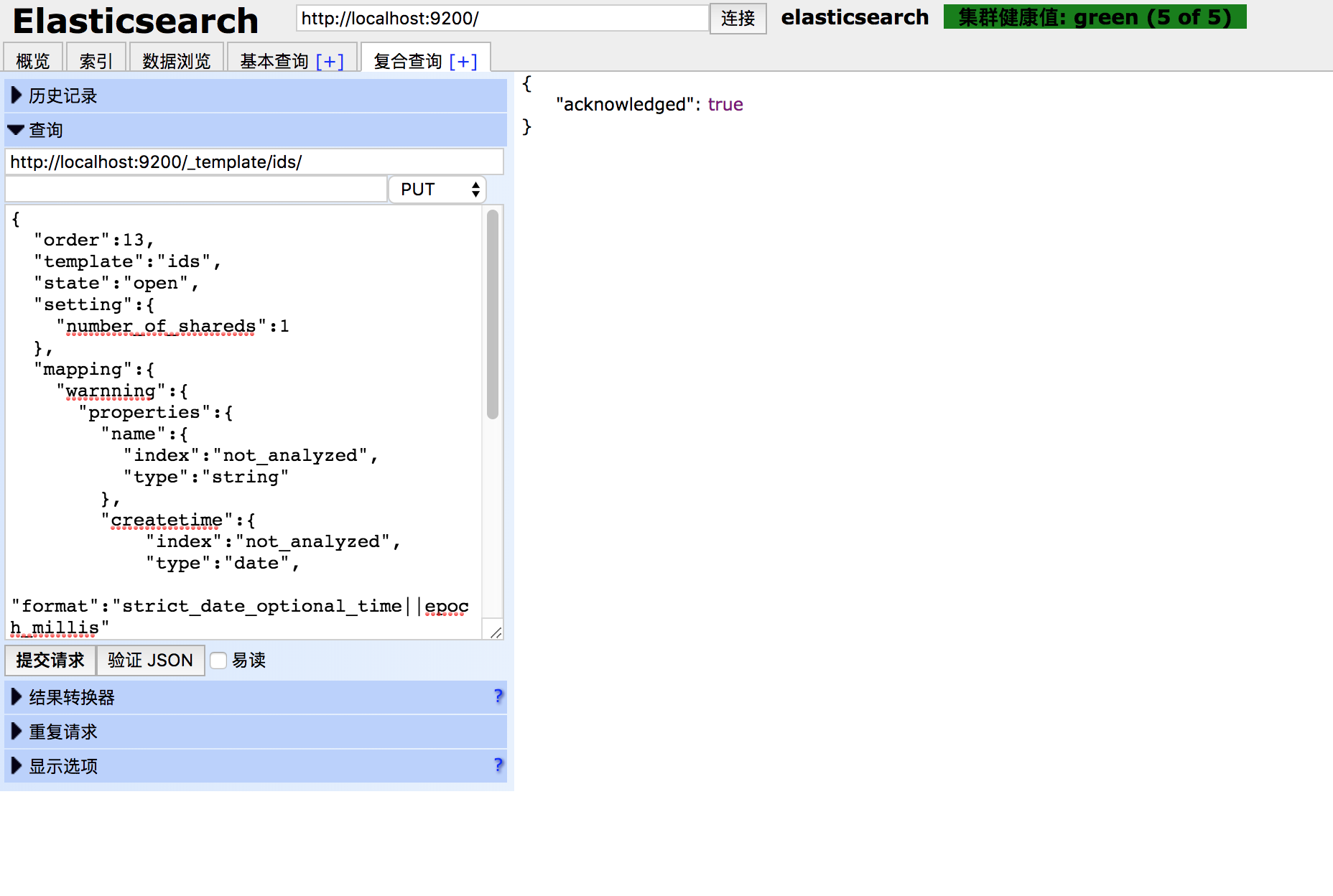
然后查看一下,模板是否上传成功:

#1、新版本的elasticsearch中,模板的index只能有true何false两个选择,与是否分词无关;不分词请把类型(type)设置成keyword。
#2、新版本中不在保留string类型,取而代之的是text类型和keyword类型,text类型可分词,keyword类型不分词。
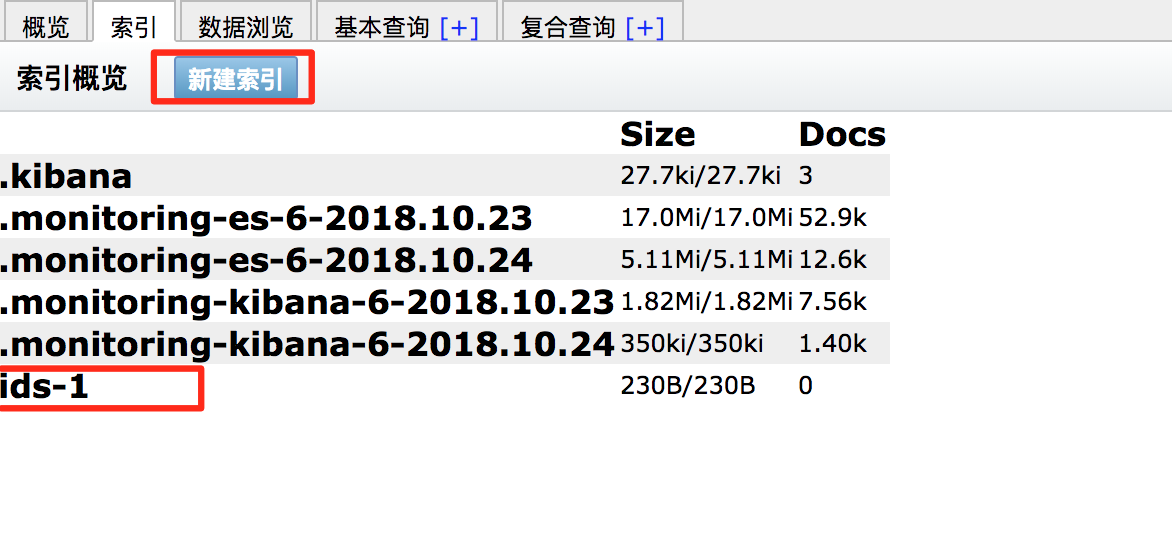
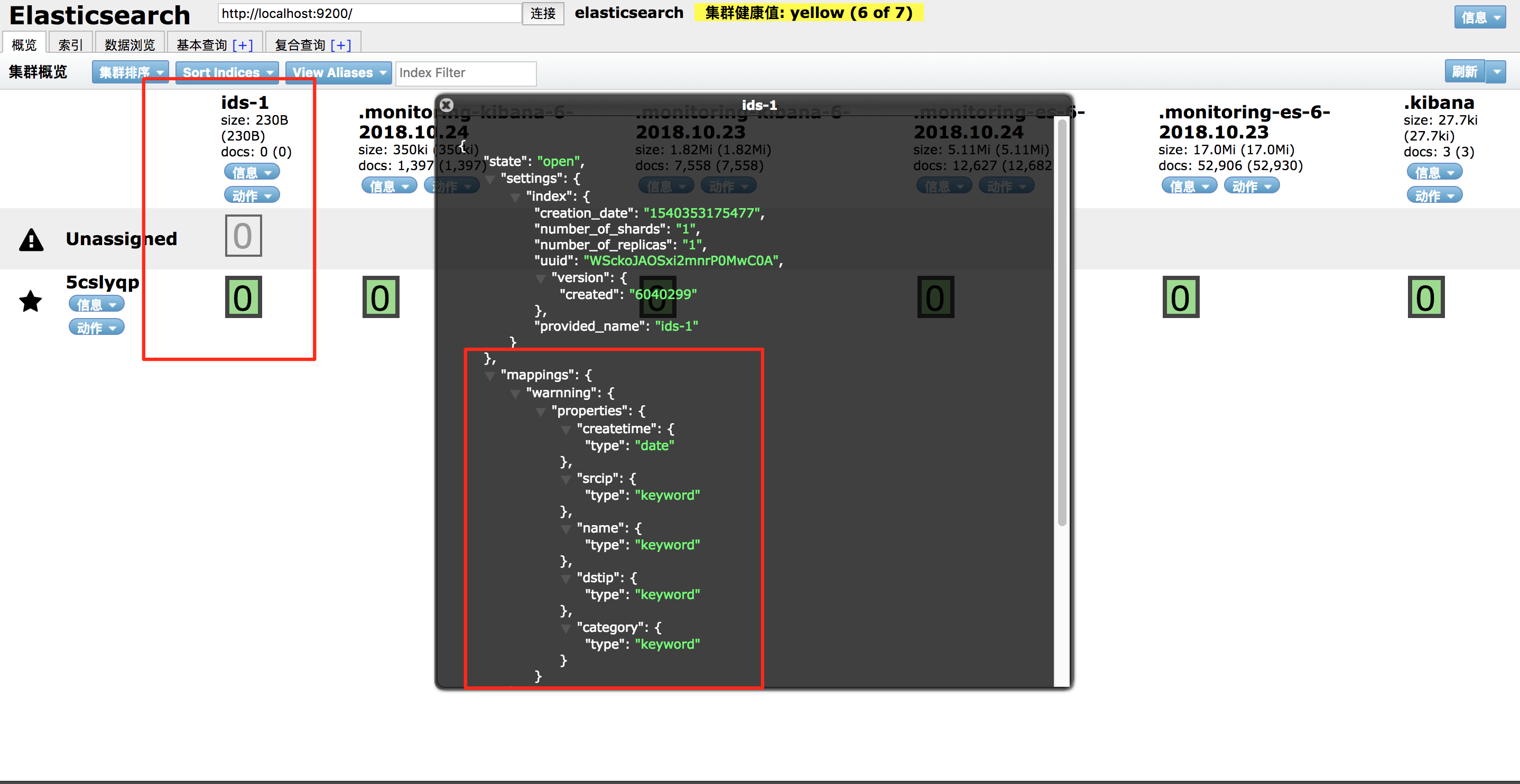
2、创建索引操作:
3、传入数据
restful api接口,见我写的前面的文章《ELK基础学习》
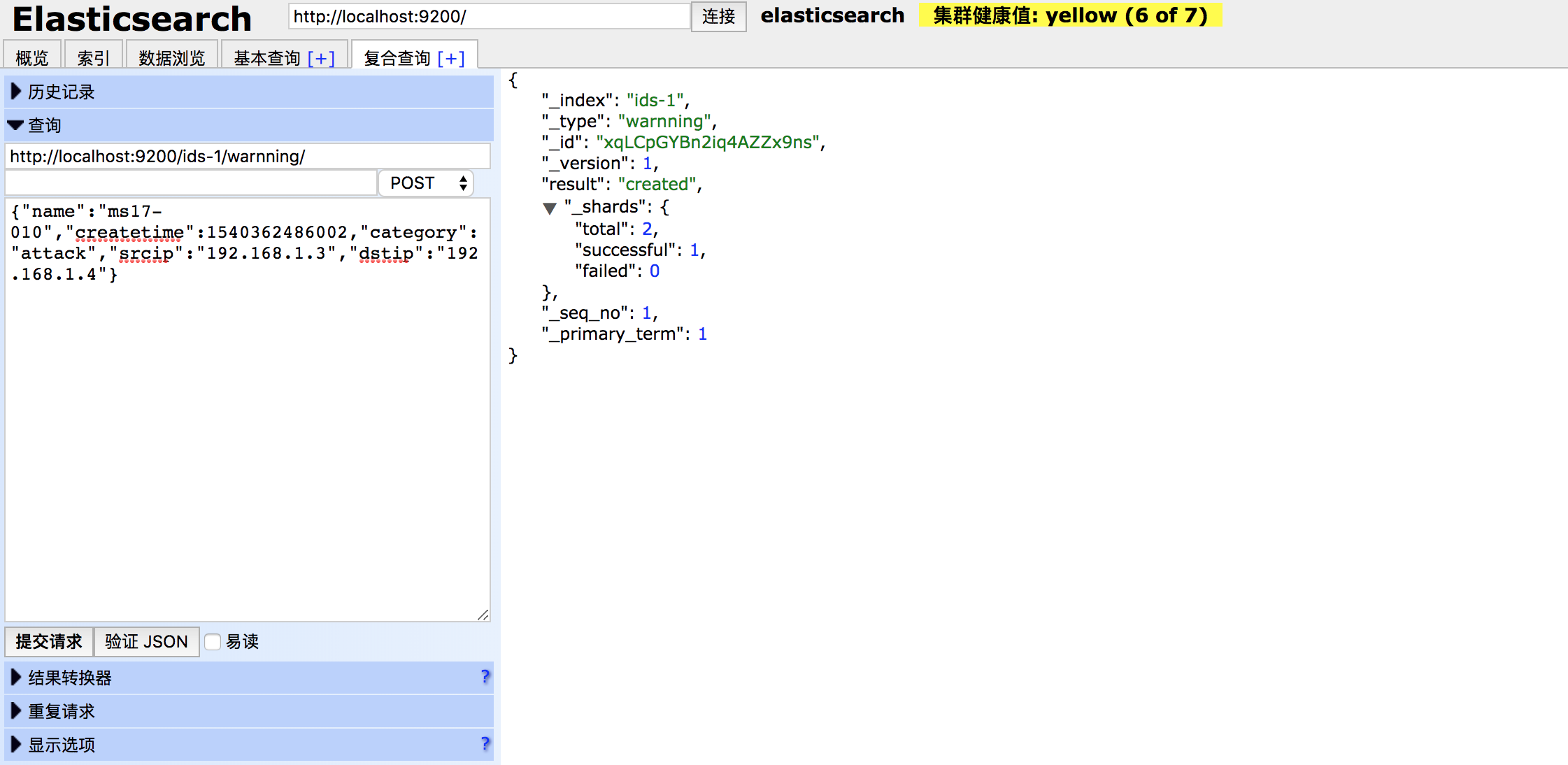
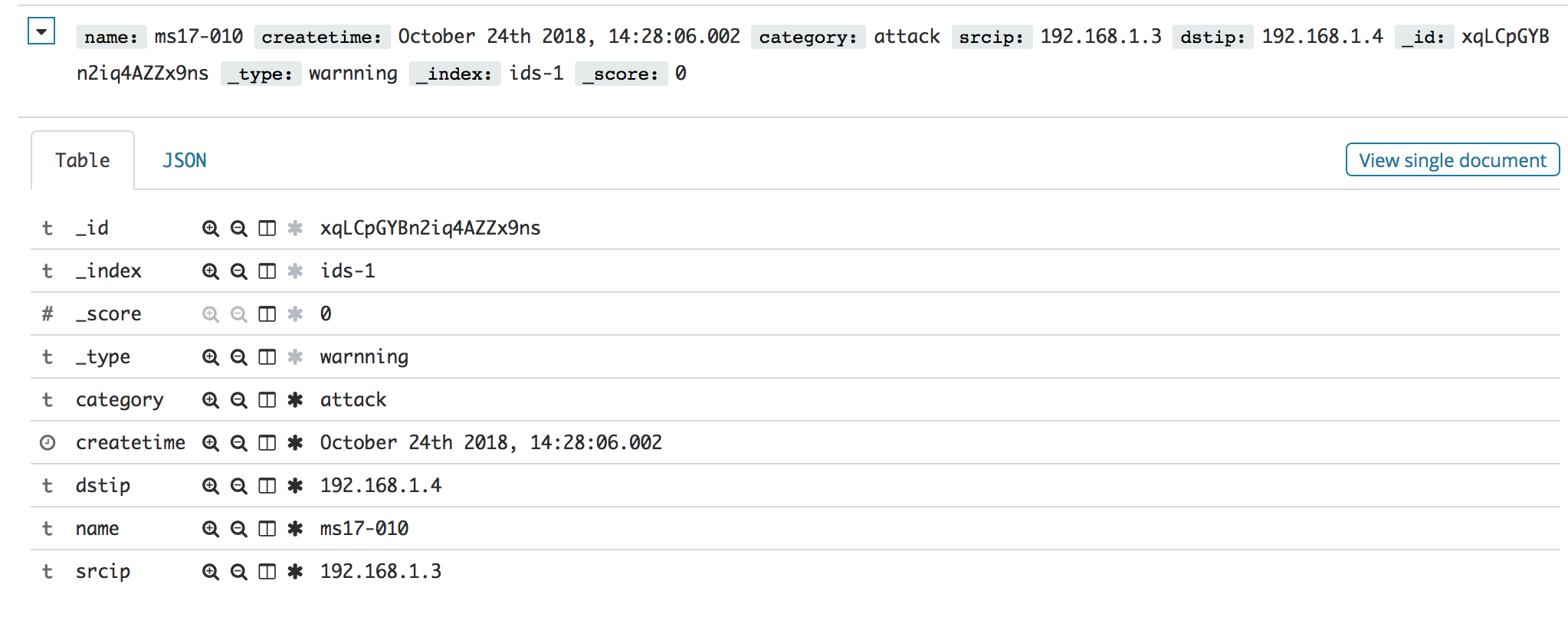
数据如下:
{
"name": "ms17-010",
"createtime": 1540362486002,
"category": "attack",
"srcip": "192.168.1.3",
"dstip": "192.168.1.4"
}
效果如图:
4、Elasticsearch的配置文件简介
这里介绍的是elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
#cluster.name: my-application #集群名
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
#node.name: node-1 #节点名
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data #数据文件路径
#
# Path to log files:
#
#path.logs: /path/to/logs #日志文件路径
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1 #绑定的IP地址
#
# Set a custom port for HTTP:
#
#http.port: 9200 #服务端口
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"] # 允许访问的地址列表
#
#discovery.zen.ping.unicast.hosts: ["host1", "host2"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
#discovery.zen.minimum_master_nodes:
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
# 以下是为了避免X-PACK插件与head冲突导致elasticsearch-head无法正常连接elasticsearch而配置的。
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
5、Elasticsearch批量插入数据
python 有 Elasticsearch 库,可以使用python Elasticsearch库中的helpers中的bulk来解决批量导入的问题,对于数据量大的时候的插入效率会好的多。但缺点也有,批量插入不会获取每一条插入具体成功与否的信息。Python伪代码如下:
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
es = Elasticsearch()
_list = []
_object_json = {
#...
}
for x in x:
_list.append(_object_json)
if len(_list) >= 5000:
bulk(es, _list)
if len(_list) > 0:
bulk(es, _list)