
Shell编程之linux四剑客命令案列分析
在我们日常的Shell编程中我们会用到很多的一些语句,有的语句,如果用好了,可以让我们的脚本更上一层楼,让我们的功能更容易满足企业的需求。
一.Sed命令
动作说明:
-
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
-
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
-
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
-
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
-
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
-
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
sed命令的选项(option):
-n :只打印模式匹配的行
-e :直接在命令行模式上进行sed动作编辑,此为默认选项
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
-r :支持扩展表达式
-i :直接修改文件内容
作用:文件外命令对文件内容进行操作
vi test.txt
# name info
My name is kongdesheng
This is my first scripts!
192.168.1.11
192.168
:%s/169/168/g #文件中把全部169改成168
列1: 把文件中内容为'192'的字符串特换为10
sed 's/192/10/g' test.txt //缓存修改,实际文件内容未变 sed -i 's/192/10/g' test.txt //文件内容真正被修改
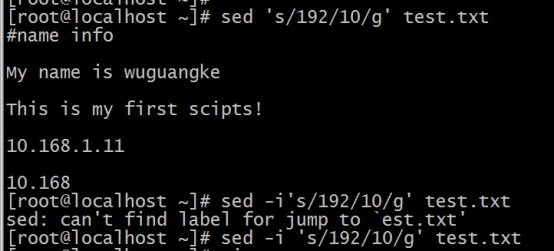
列2:在文件内容的行首添加一个空格
#在文件内容的行首添加一个空格,‘^’:代表开始 sed 's/^/& /g' test.txt #在文件内容的行首添加一个id空格,在实际工作中用for循环把id替换成1,2,这种行号一行一行的加入行号 sed 's/^/&id /g' test.txt
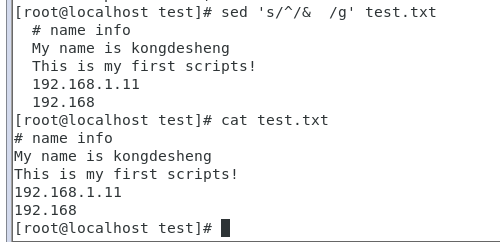
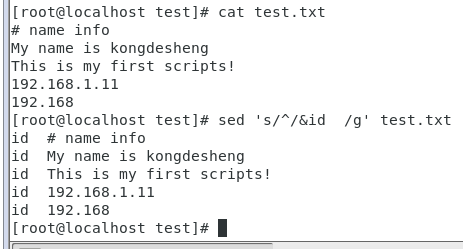
列3:在文件内容的行尾添加一个'id'
#在文件内容的行尾添加一个空格id,‘$’:代表开始 sed 's/$/& id/g' test.txt

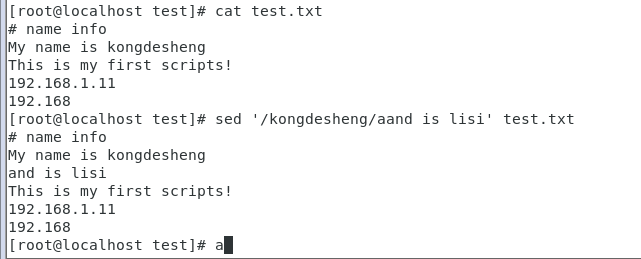
列4:在文件内容“kongdesheng”的后面插入一行内容
#'a':下一行新增 sed '/kongdesheng/a and is lisi' test.txt
列5:在文件内容“kongdesheng”的前面插入一行内容
#'i':前一行新增 sed '/kongdesheng/i and is lisi' test.txt

列6:打印文件内容“kongdesheng”的一行内容
#'-n' :只打印模式匹配的行 sed -n '/kongdesheng/p' test.txt

列7:打印第指定行的内容
sed -n '1p' test.txt #打印第一行 sed -n '3p' test.txt #打印第三行 sed -n '1,5p' test.txt #打印1至5行

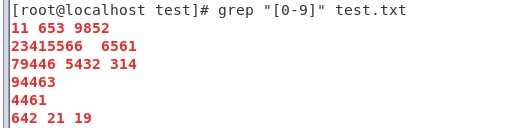
列8:一个文件中,有一堆数据,大小不一,行号不定,找出出文件中最大最小的一个数
vi test.txt
11 653 9852
23415566 6561
79446 5432 314
94463
4461
642 21 19
命令:
#sed's/ / /g' 把空格换行,把每个数字为一行 #grep -v "^$" grep:分组过滤筛选数据,-v:剔除匹配后面结果的行,这里作用是去除空行 #sort -nr 排序(-nr:降序, -n:升序) -r将数字当做字符进行排序,-nr 按照整个数字来排序 #sed -n '1p' 打印第一行 #sed -n '1p;$p' $代表最后一个,这里$p代表最后一行 cat test.txt |sed 's/ / /g'|grep -v "^$"|sort -nr|sed -n '1p;$p'
二.Awk命令
作用:常用于对列的筛选
选项参数说明:
-
-F fs or --field-separator fs指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-
-v var=value or --asign var=value赋值一个用户定义变量。
-
-f scripfile or --file scriptfile从脚本文件中读取awk命令。
-
-mf nnn and -mr nnn对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-
-W compact or --compat, -W traditional or --traditional在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-
-W copyleft or --copyleft, -W copyright or --copyright打印简短的版权信息。
-
-W help or --help, -W usage or --usage打印全部awk选项和每个选项的简短说明。
-
-W lint or --lint打印不能向传统unix平台移植的结构的警告。
-
-W lint-old or --lint-old打印关于不能向传统unix平台移植的结构的警告。
-
-W posix打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替^和^=;fflush无效。
-
-W re-interval or --re-inerval允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-
-W source program-text or --source program-text使用program-text作为源代码,可与-f命令混用。
-
-W version or --version打印bug报告信息的版本。
列1:文件test.txt,内容如下一行,请打印出第四列的值
vi test.txt
My name is kongdesheng
#$4:打印第四列 awk '{print $4}' test.txt #或者 cat test.txt |awk '{print $4}' #$nf:打印全部 awk '{print $nf}' test.txt #$NF:打印最后一列 awk '{print $NF}' test.txt

列2:打印/etc/passwd文件中的第一列(用户)
#-F:以':'为分隔划分列(默认是空格划分列) cat /etc/passwd |awk -F: '{print $1}' #或者如下 #sed 's/:/ /g':把冒号换成空格 cat /etc/passwd |sed 's/:/ /g' |awk '{print $1}'

列3:从ifconfig命令集得到ip地址
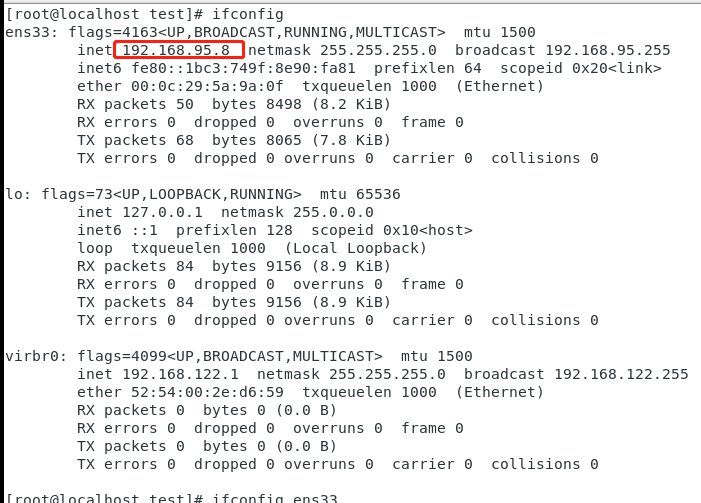
#grep 'netmask' :查找包含'netmask'的行 #awk '{print$2}':第二列 ifconfig ens33 |grep 'netmask'|awk '{print$2}'

列4:df -h 检查linux服务器的文件系统的磁盘空间占用情况,返回占用率
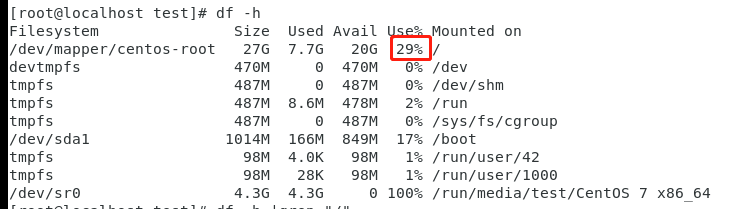
#grep "/$" :以'/'结尾的行 #awk '{print$5}' :第五列 df -h |grep "/$" |awk '{print$5}' # sed 's/%//g' :去除'%'号 df -h |grep "/$" |awk '{print$5}'| sed 's/%//g'


列4: 在内容前面加属性

#'^' 开始 #'$' 末尾 awk '{print$NF}' test.txt |sed 's/^/Name:/g' 或者 awk '{print"Name:"$NF}' test.txt

三.Find命令
语法:
find path -option [ -print ] [ -exec -ok command ] {} ;
参数说明 :
find 根据下列规则判断 path 和 expression,在命令列上第一个 - ( ) , ! 之前的部份为 path,之后的是 expression。如果 path 是空字串则使用目前路径,如果 expression 是空字串则使用 -print 为预设 expression。
expression 中可使用的选项有二三十个之多,在此只介绍最常用的部份。
-mount, -xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
-amin n : 在过去 n 分钟内被读取过
-anewer file : 比文件 file 更晚被读取过的文件
-atime n : 在过去n天内被读取过的文件
-cmin n : 在过去 n 分钟内被修改过
-cnewer file :比文件 file 更新的文件
-ctime n : 在过去n天内被修改过的文件
-empty : 空的文件-gid n or -group name : gid 是 n 或是 group 名称是 name
-ipath p, -path p : 路径名称符合 p 的文件,ipath 会忽略大小写
-name name, -iname name : 文件名称符合 name 的文件。iname 会忽略大小写
-size n : 文件大小 是 n 单位,b 代表 512 位元组的区块,c 表示字元数,k 表示 kilo bytes,w 是二个位元组。
-exec :承接
|xargs : 承接作用,使用时有局限,
-type c : 文件类型是 c 的文件,type可以是以下的值
d: 目录
c: 字型装置文件
b: 区块装置文件
p: 具名贮列
f: 一般文件
l: 符号连结
s: socket
列1:根目录下查找test.txt文件
# / 根目录 find / -name 'test.txt'

列2:当前目录下查找test.txt文件
# . 当前目录 find . -name 'test.txt'

列3:当前目录的第一级目录查找查找test.txt文件
# -maxdepth 1 第一级目录 find . -maxdepth 1 -name 'test.txt'

列4:当前目录下的第一级目录查找.txt结尾的文件
#-type f 文件 find . -maxdepth 1 -type f -name '*.txt'
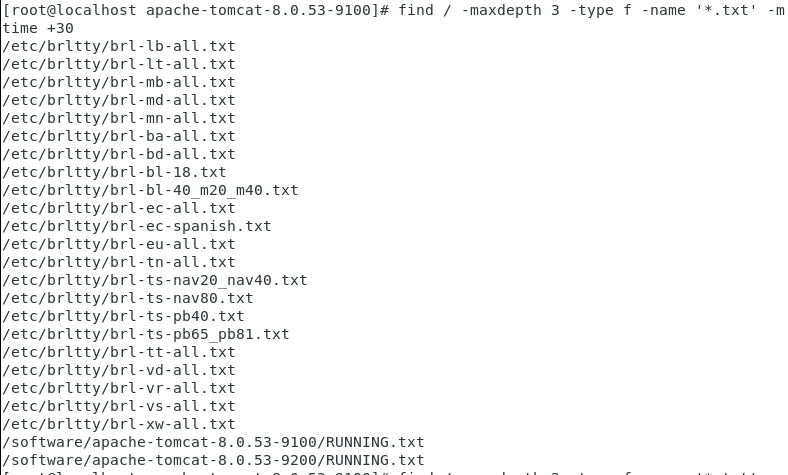
列5:查找30天以前修改过的的文件
# / 根目录 # -maxdepth 3 根目录三级以内的目录 # -type f 文件 # -mtime +30 三十天以前修改的文件 find / -maxdepth 3 -type f -name '*.txt' -mtime +30
列6:查找1天以内修改过的文件
# . 当前目录 # -maxdepth 3 当前目录三级以内的目录 # -type f 文件 # -mtime -1 1天以内修改的文件 find . -maxdepth 3 -type f -name '*.txt' -mtime -1

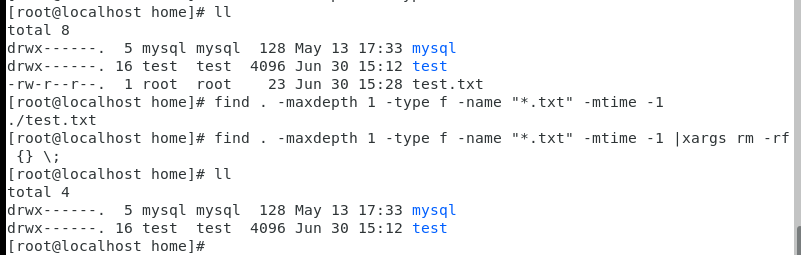
列7:当前目录下查找一天以内修改的文件 删除
# . 当前目录 # -maxdepth 1 一天以内的目录 # -name "*.text" 结尾为.text # -type f 文件 # -mtime -1 1天以内修改的文件 # -exec rm -rf {} 把前面的结果承接引入到大括号位置 # ; 固定的格式
find . -maxdepth 1 -type f -name "*.text" -mtime -1 -exec rm -rf {} ; #或者 find . -maxdepth 1 -type f -name "*.txt" -mtime -1 |xargs rm -rf {} ;
列8:当前目录下查找一天以内修改的文件,复制到tmp文件夹下
# . 当前目录 # -maxdepth 1 一天以内的目录 # -name "*.txt" 结尾为.txt # -type f 文件 # -mtime -1 1天以内修改的文件 # --exec cp {} /home/ 把前面的结果承接引入到大括号位置 # ; 固定的格式 find . -maxdepth 1 -type f -name "*.txt" -mtime -1 -exec cp {} /home/ ;

列9: 查找内存大于 20M的文件
find . -size +20M

列10:从根目录三级目录内查找100M以内的文件
find / -maxdepth 3 -size +100M -type f

列11:删除当前目录下30天以前的文件
find . mtime +30 -exec rm -rf {} ;
四.Grep命令
作用:对内容进行过滤
参数:
-
-a 或 --text : 不要忽略二进制的数据。
-
-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-
-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-
-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-
-c 或 --count : 计算符合样式的列数。
-
-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-
-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-
-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
-
-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
-
-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-
-F 或 --fixed-regexp : 将样式视为固定字符串的列表。
-
-G 或 --basic-regexp : 将样式视为普通的表示法来使用。
-
-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-
-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-
-i 或 --ignore-case : 忽略字符大小写的差别。
-
-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
-
-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
-
-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-
-o 或 --only-matching : 只显示匹配PATTERN 部分。
-
-q 或 --quiet或--silent : 不显示任何信息。
-
-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
-
-s 或 --no-messages : 不显示错误信息。
-
-v 或 --revert-match : 显示不包含匹配文本的所有行。
-
-V 或 --version : 显示版本信息。
-
-w 或 --word-regexp : 只显示全字符合的列。
-
-x --line-regexp : 只显示全列符合的列。
-
-y : 此参数的效果和指定"-i"参数相同。
列1: 匹配以11开始的文件行
grep "^11" test.txt

列2: 匹配以61结尾的文件行
grep "61$" test.txt

列3: 匹配包含有0至9的文件行
grep "[0-9]" test.txt
列4: 匹配包含有a至z的文件行
grep "[a-z]" test.txt #匹配大写A-Z开始的行 grep "^[A-Z]" test.txt


列5: 默认匹配为模糊匹配(包含关系)
grep "168" test.txt

列6: 绝对匹配(相等关系)
grep "^192.168$" test.txt

列7: 匹配ip
#-E:将样式为延伸的正则表达式来使用 #[0-9]:匹配的参数 #{1,3}:出现的次数 grep -E "([0-9]{1,3}.){3}[0-9]{1,3}" test.txt #或者如下语句,作用是一样的 cat test.txt |grep -E "([0-9]{1,3}.){3}[0-9]{1,3}"

列8: 多级匹配
grep -E 等于egrep
#'||':全部打印,标红匹配内容 #'|' :打印匹配的行内容 # -n 打印行号 egrep -n "11|kongdesheng" test.txt #或者 grep -E "11|kongdesheng" test.txt
