一、MySQL查询
1、全表查询
一般开发会发送SQL脚本解压文件包,测试需要导入sql脚本到数据库中
先解压文件,在控制台打开,复制放置的路径,输入root密码
2、inner join 交集
又叫内连接的部分,主要是获取两个表中字段匹配关系的表。查询关联字段共同拥有的数据
person.name,person.age,work.copany,educate.schoolname:想要获得的内容的字段;
inner json:表示内关联,即所有表中共有的数据;
work on person.code=work.code:表示person和work两个表通过code关联;
on:表示通过什么进行关联;
where person.code=1001:表示提取code为1001的这条数据中的内容。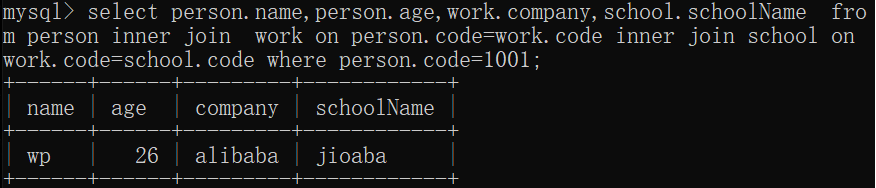
3、limit 数字,查询表的前几行数据
命令:select * from 文件名 linit 数字(*代表所有的字段)
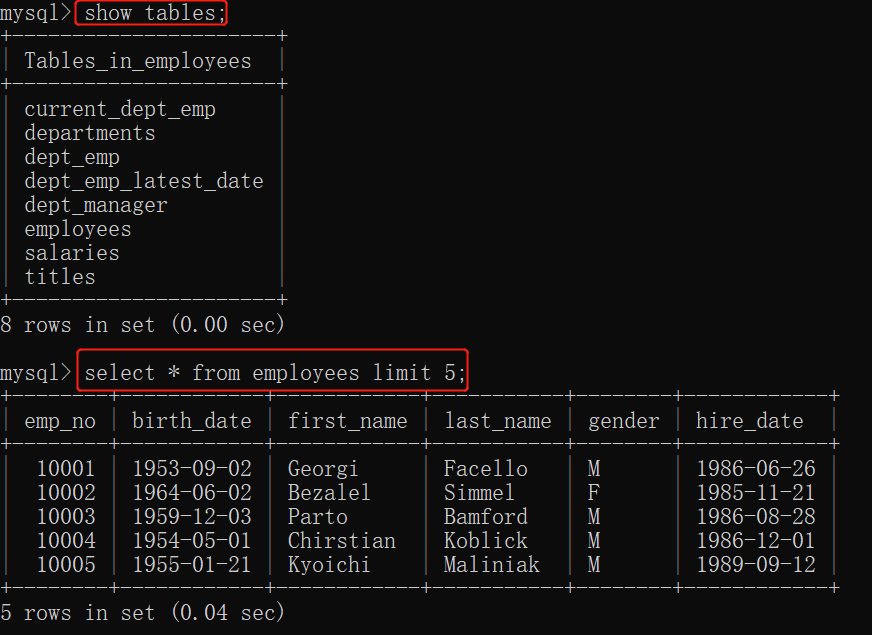
4、查询表的时候字段较多时,可以自定义选择字段(如:开始和结束的5个字段)
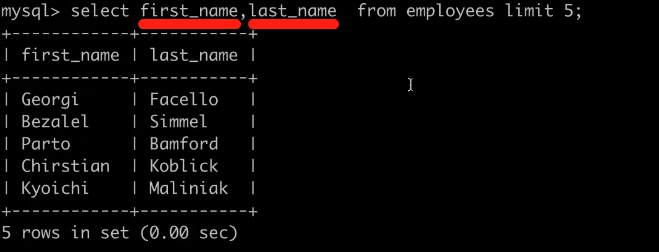
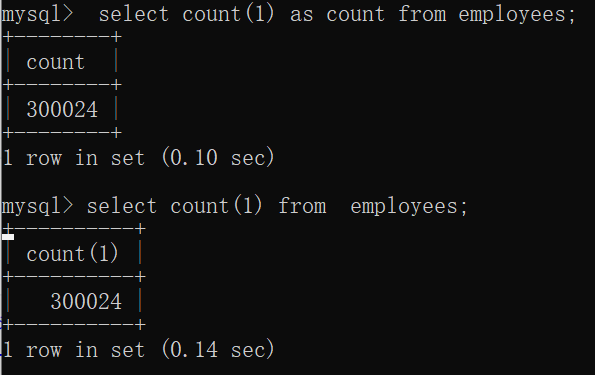
5、count计数
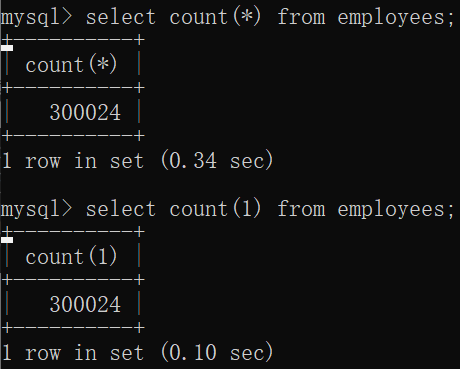
查询表中所有的数据信息有两种方式:
select count(*) from 文件名;
select count(1) from 文件名;
6、条件过滤
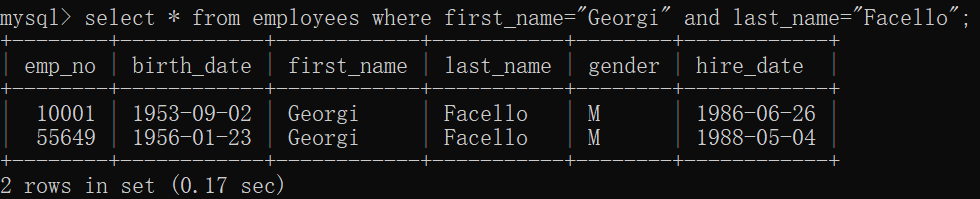
1.1 and 并且关系
必须同时满足一个以上的需求同时查询的结果,where是定位词,表示查询的数据在那个位置
1.2 or 或者关系
查询的信息只用满足其中一个就行
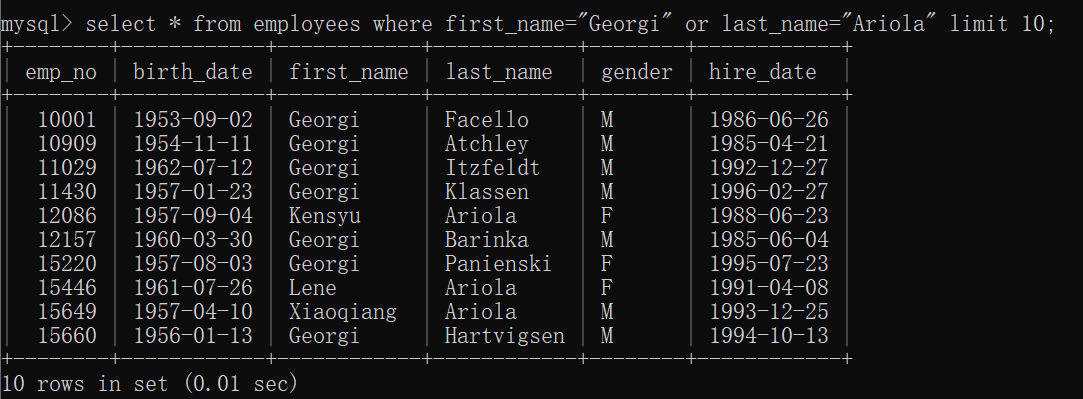
1.3 in 包含关系
只要查询出现的内容都会显示出来
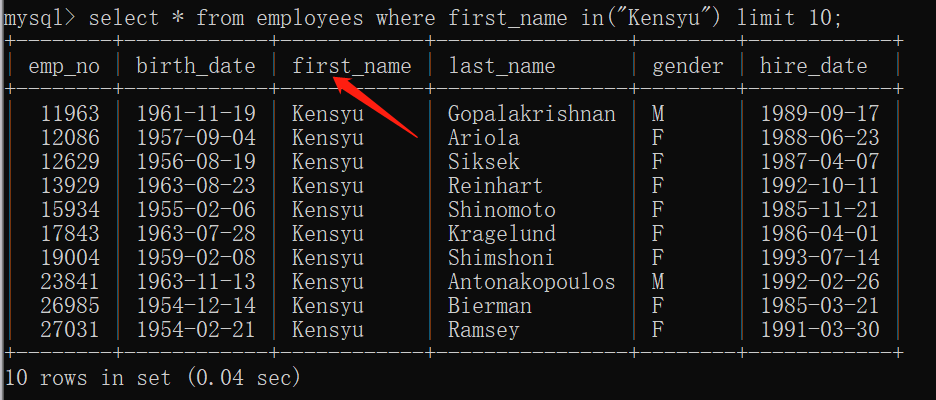
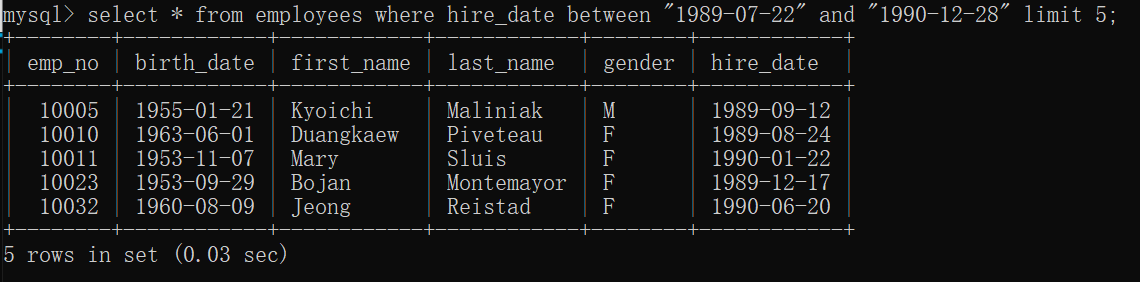
1.4 between and 范围检查
一般可以查询时间或者分数之类的范围
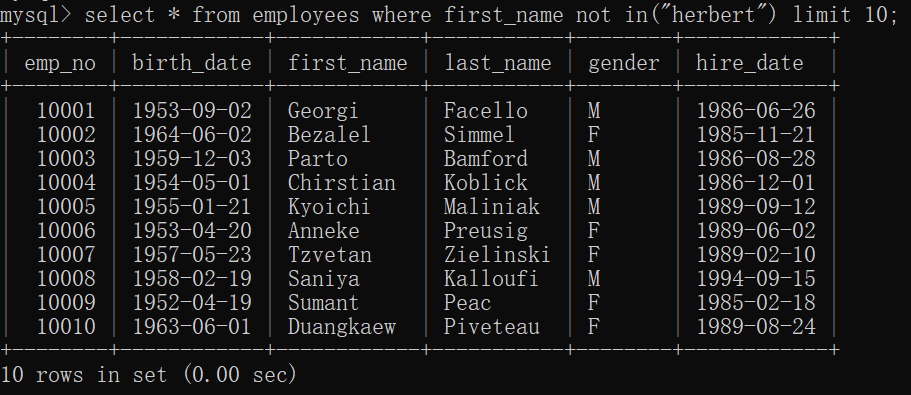
1.5 not in 否定结果
查询的信息中不需要包含这类内容或者是范围
1.6 % 针对只记得部分数据查询
可以选择搜索的方式有"%re"、"re%"、"%re%"
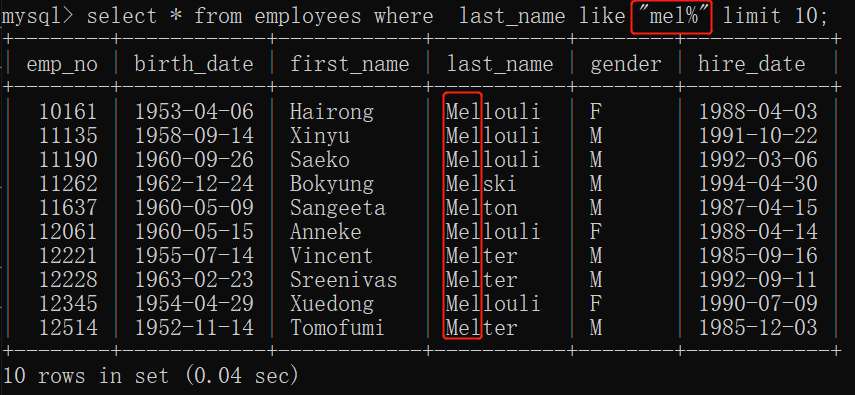
1.7 下划线_
搜索时,字母前有几个下划线,就表示几个字符串缺失

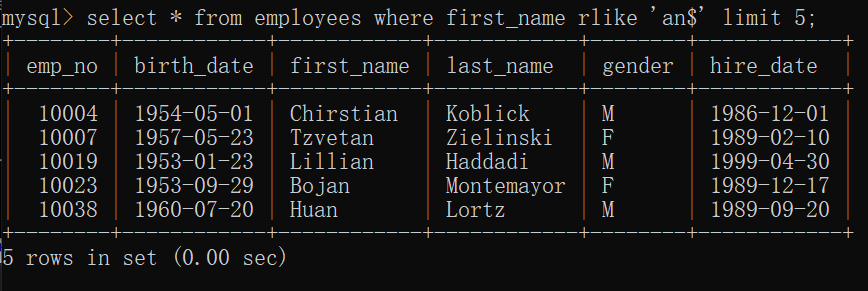
1.8 以什么开头^(shift+6)

1.9 以什么结束$
1.10 as 别名
选择计数(1)作为员工的计数;
从员工中选择计数(1);
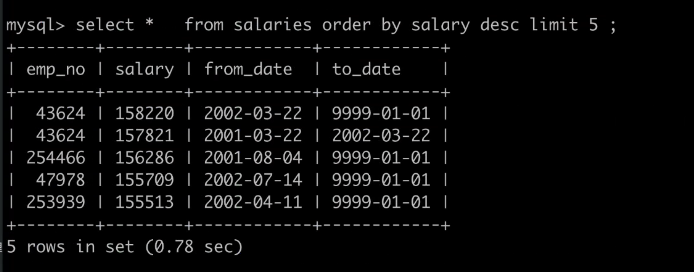
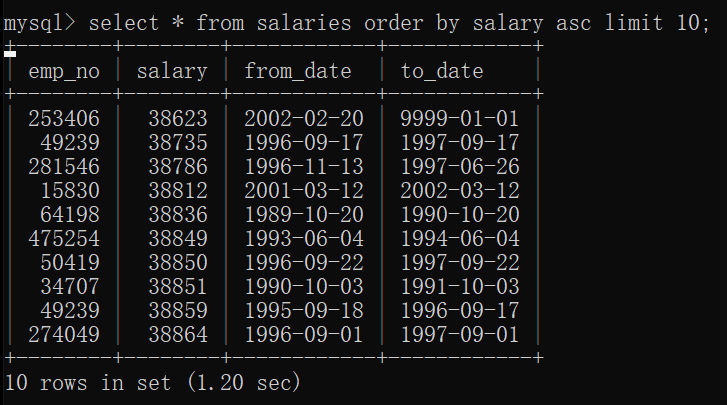
7、倒叙和正序
order by(排序方式),desc是 正序 asc是倒叙
三、聚合函数
1、总和:sum 最大:max 最小:min 平均:avg
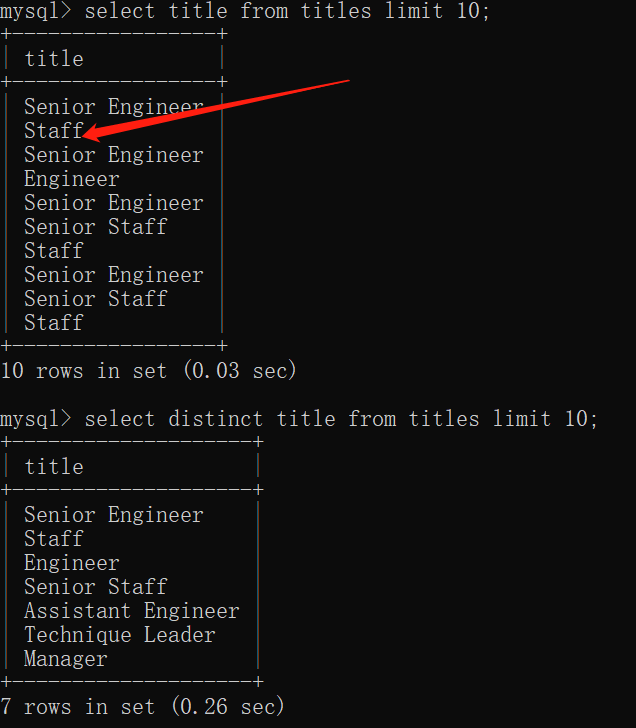
2、distinct 去重
查询时重复的信息全部删除
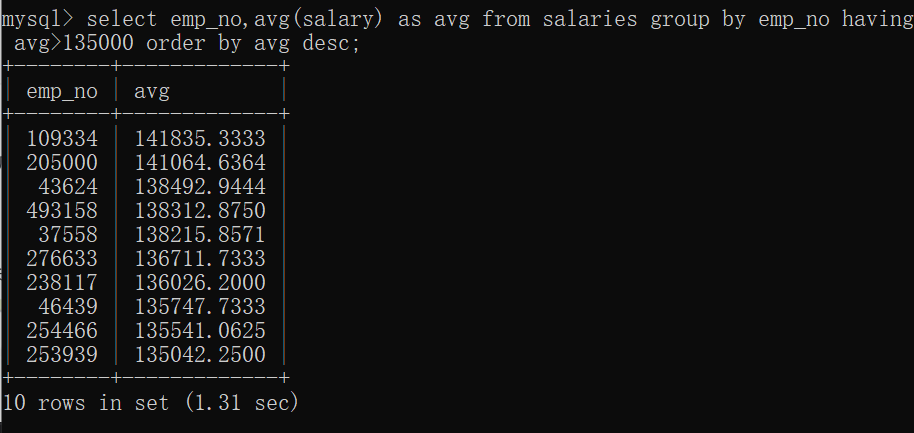
3、having 过滤
四、安装MySQL客户端
1、安装步骤
1.1 下载文件夹,安装在D盘,点击Navicat 16 for mysql
1.2 点击下一步,按照要求选择是否共享,点击开始后的页面
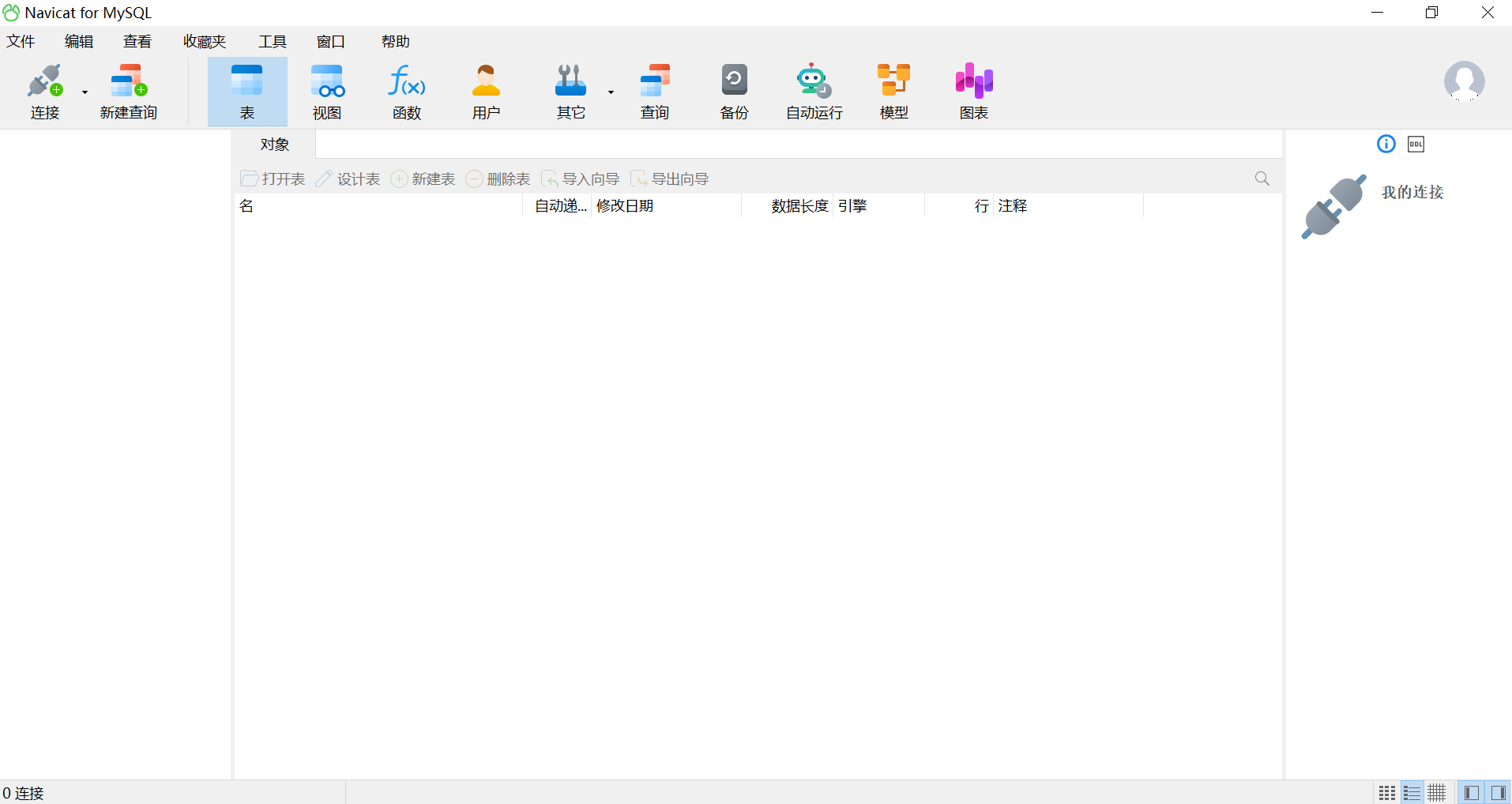
1.3 有多种数据库可以连接
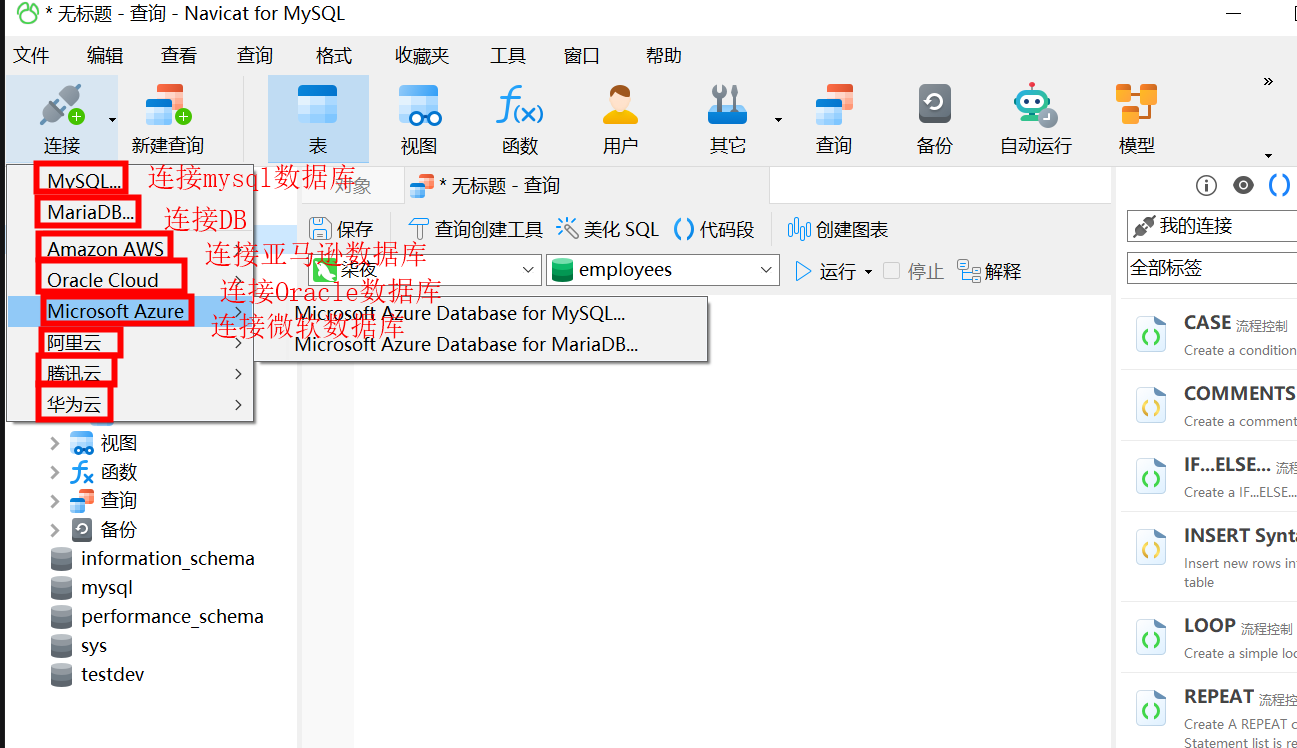
1.4 新建连接输入信息,连接名可随意,密码为root,点击链接测试,出现连接成功确定就可以
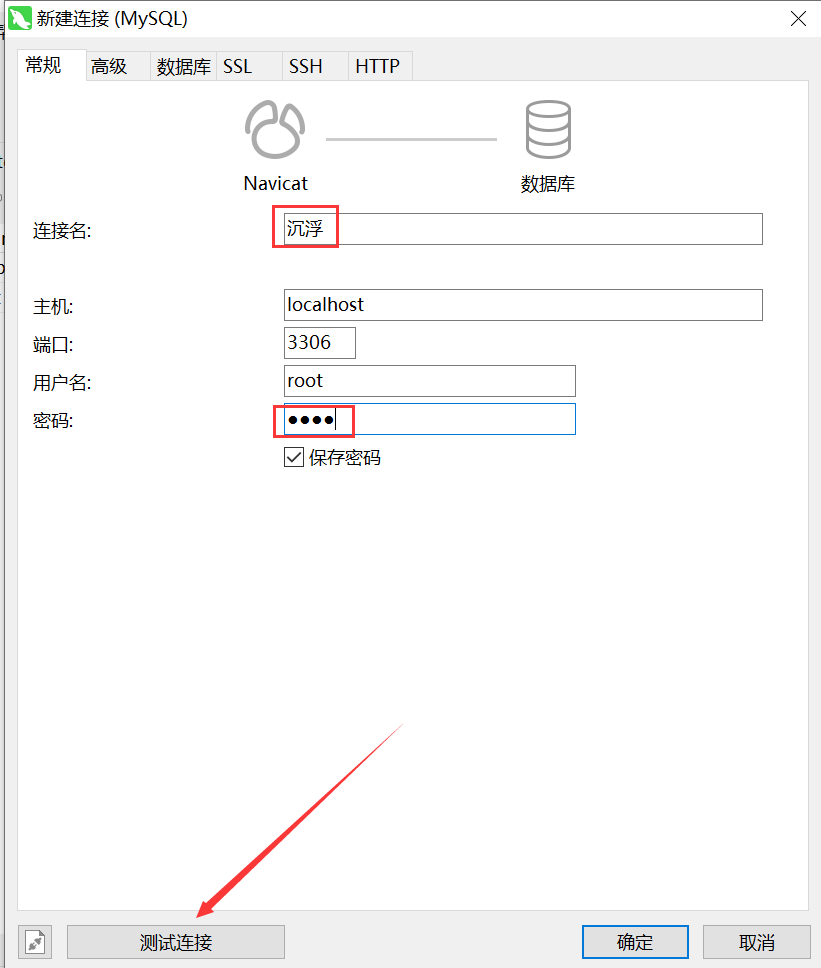
2、新建表格信息
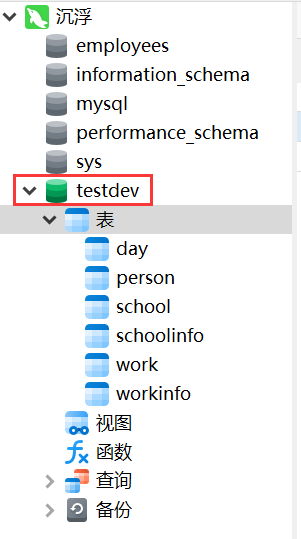
2.1 双击输入的连接名就可以查询名下的表,选择需要的表进行编辑
2.2 输入需要的表格结构和相对应的内容,右键选择新建表
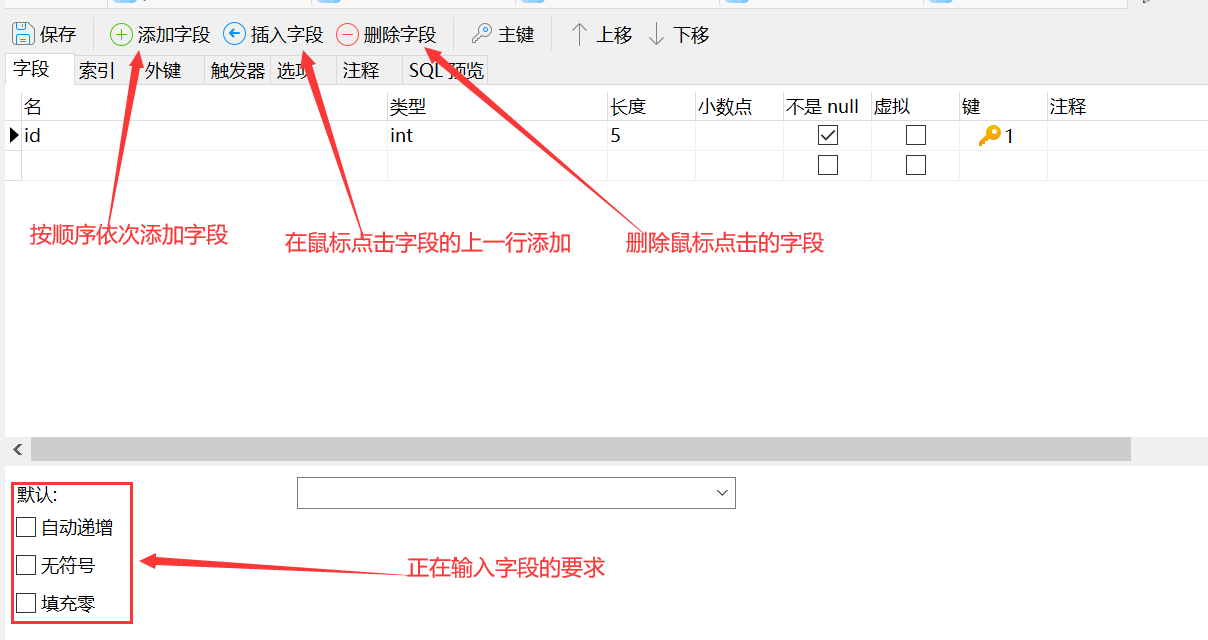
2.3 依次输入需要的内容

2.4 最后确认
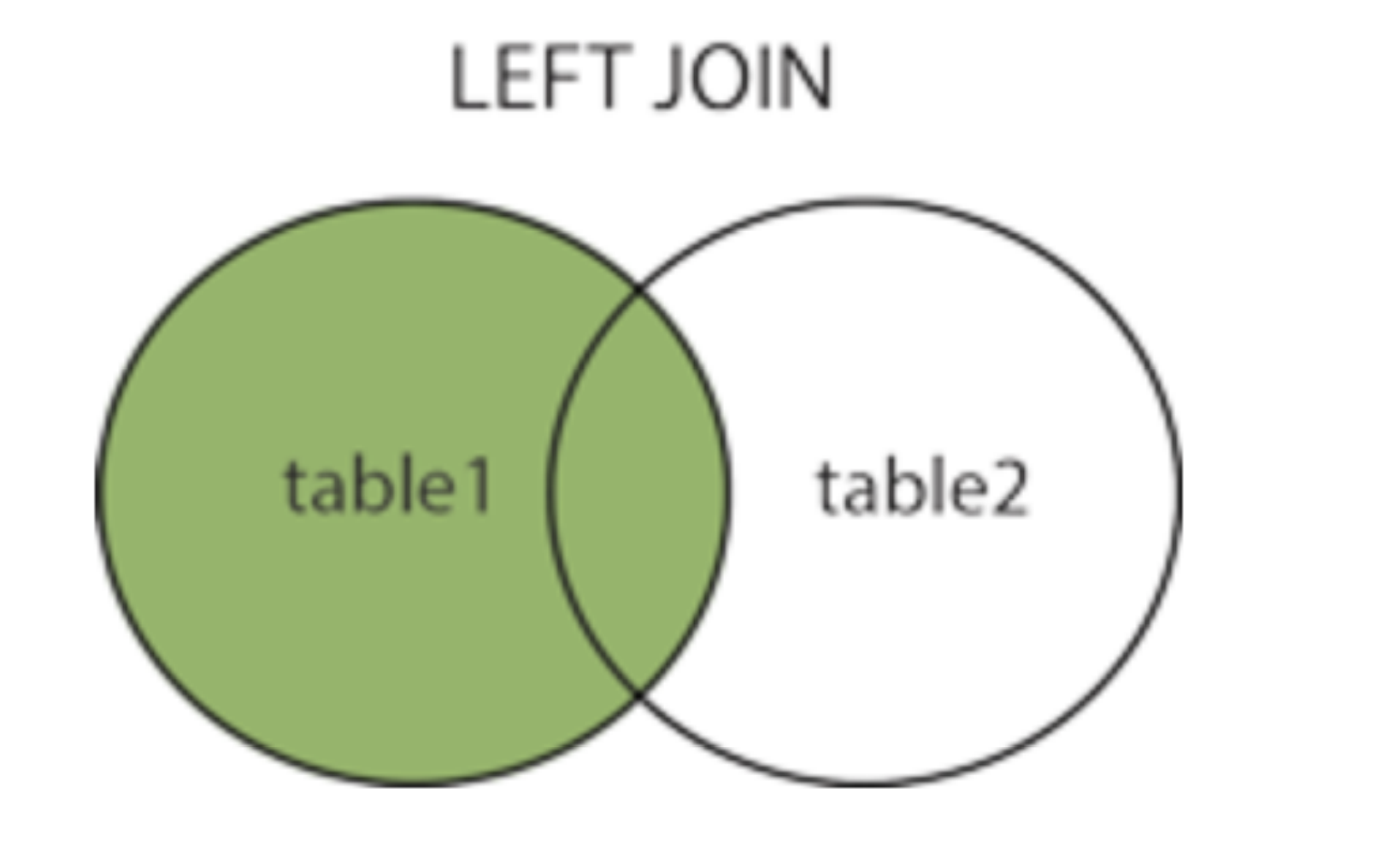
五、左连接 left join
获取左表所有记录,获取左边数据表所有符合要求的字段数据信息
内链接:inner join
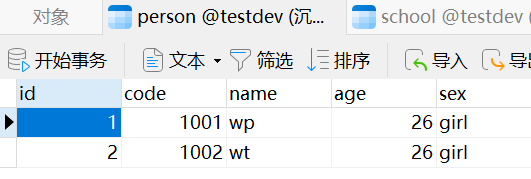
实战:首先建立相关信息表
1、当每个表中有至少一个信息是共同拥有时,就可以通过这个信息来确认
例如当下面两个表中都有code信息


2、建立左连接
select p.name,p.age,w.company,w.salary from person as p left join work as w on p.code=w.code
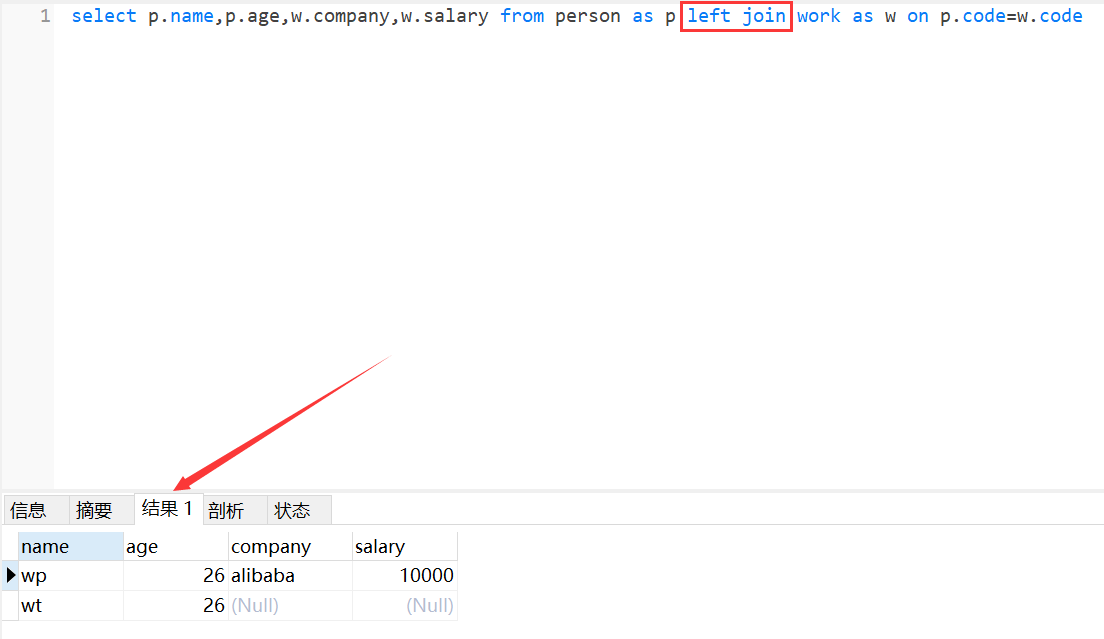
3、也可以多个表连接,因为最开始与最后输入的信息无法直接通过信息连接,就需要多个表格连接得到最后的结果,因person的信息比较多,右边没有的会显示为空
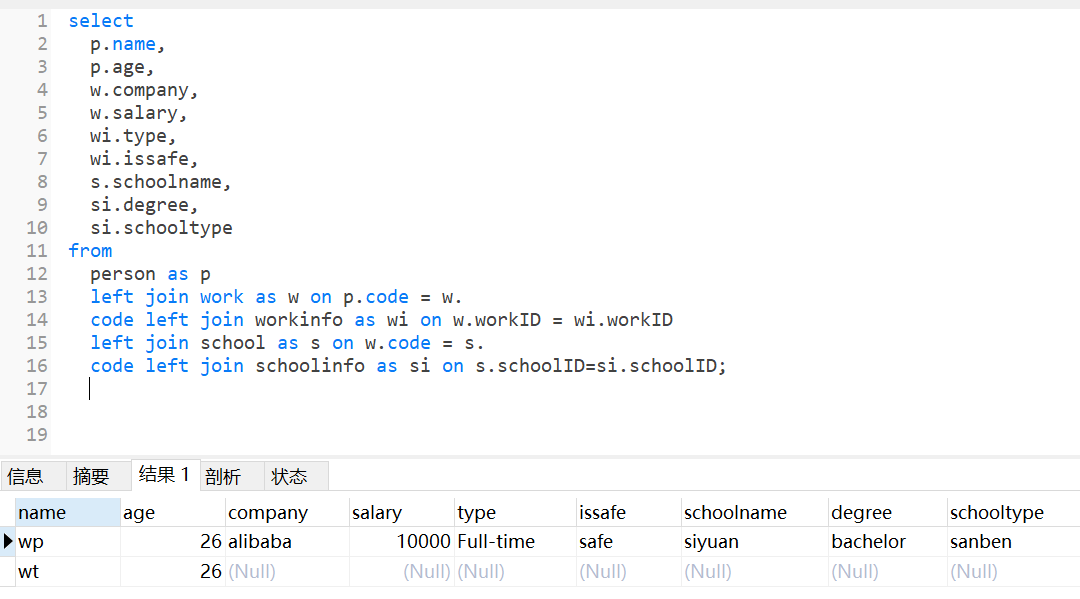
六、
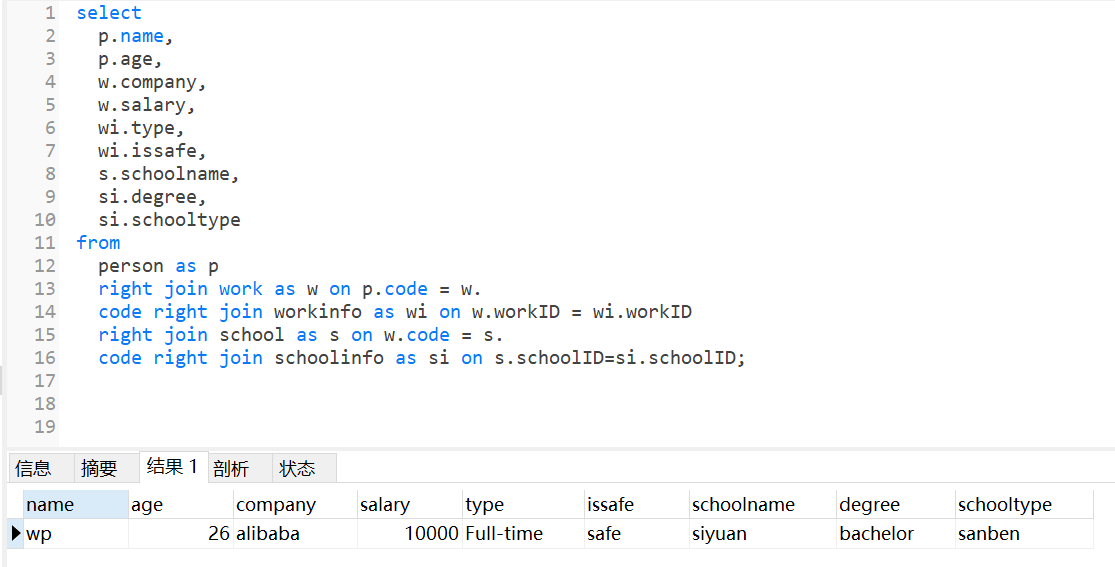
与之前的基础表格一样,换成右连接后因最后的表格信息只有一个,所以显示的内容是完整的
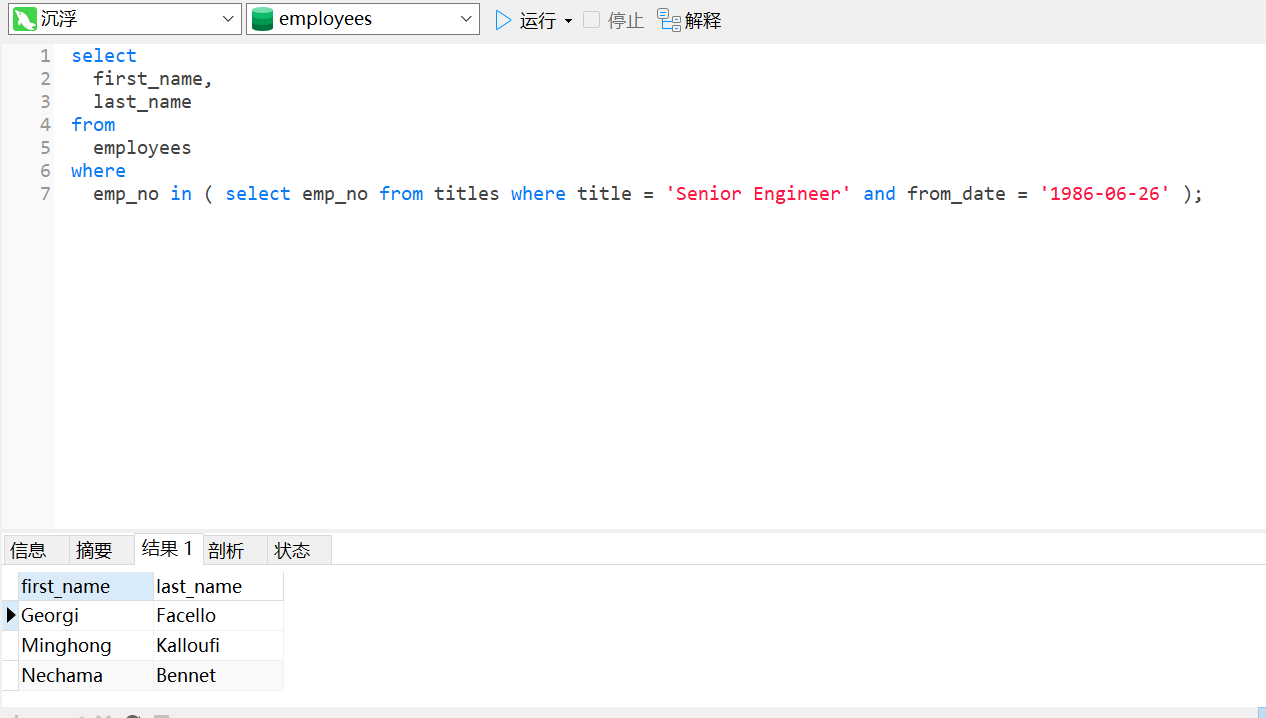
查询出从1986-06-26开始担任Senior Engineer员⼯的姓名,那么就需要使用子查询,涉及到的SQL为:select first_name,last_name from employees where emp_no in
(select emp_no from titles where title='Senior Engineer' and from_date='1986-06-
26');
八、MySQL索引
在MySQL中,创建MySQL的索引主要是为了提⾼MySQL查询的效率。但是添加太多的索引也是会降低更新表的速度的,

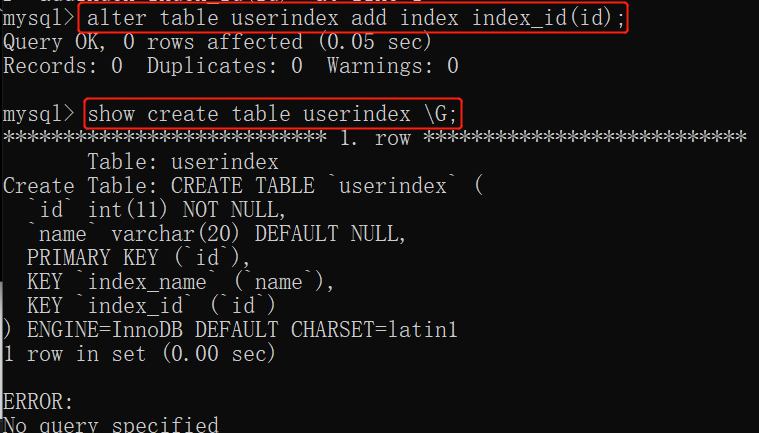
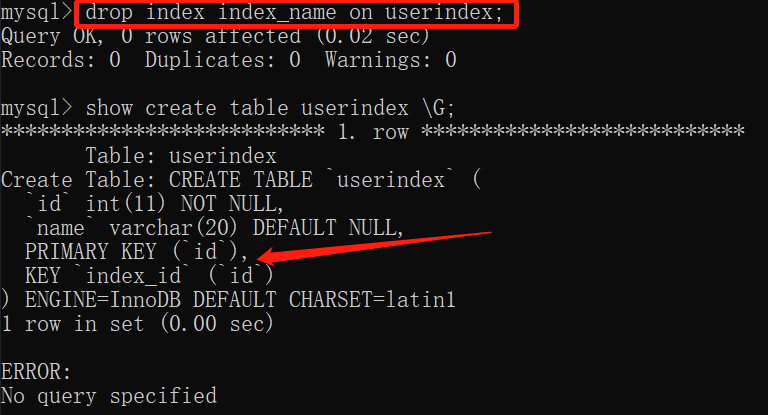
删除索引信息
drop index index_name on userindex;