一、引入
数据结构一直都是让人头疼但是又重要的东西,合理的使用数据结构可以优化你的程序,而且一般优化都相当显著,各种树形数据结构就可以让时间复杂度从 n 下降到 logn 。数据结构大体上分为线性数据结构、树形数据结构和图。很多新手会把并查集当成一种数据结构,将数据结构分为四种包括我最开始学的时候,但是当对于数据结构的理解加深以后,会发现其实并查集就是树形数据结构。从本质上来讲,数据结构又可以分为一对一数据结构(线性)、一对多数据结构(树形数据结构)和多对多数据结构(图)。在深一步讲,这些其实都是逻辑划分,在内存中只有线性数据结构,甚至只有一维数组。内存本身就可以看作一个一维数组,内存空间其实就按照地址的大小一字排开。所以任何数据结构结构只有两种组织方式——数组和链表。当然这些都等以后再讲,本文主要讲线性数据机构。
二、链表
上面已经提到,数据结构只有两种组织方式,数组想必大家都会了,这个在学语法的时候就已经教了。所以我主要介绍一下链表。首先,什么是链表,链表就是像链子一样将零散的内存单元串起来,使他们在逻辑上排列成一维数组的样子。那么怎么串起来呢,答案是用指针。那么链表的节点定义就是一个二元组,数据和指向自身这种类型的指针,定义如下。
struct node { int data; node *next; };
链表在逻辑上就长这样(数字代表仅仅节点顺序):

因为链表是一个一个串起来的,所以对于一个链表你只需要保存他的头指针,就能找到整个链表(数组其实也是这样)。看到这里,小伙伴们可能会想知道怎么创建一个链表呢。别着急,我现在就要讲了,链表的创建方式有两种一个是头插法,一个是尾插法。
咱们先讲头插法,头插法故名思意就是指新节点是在头部插入的。
如图:
首先创建新节点(1号结点是新创建的,实际上他是第四个被创建的,但现在他是排第一的节点了):
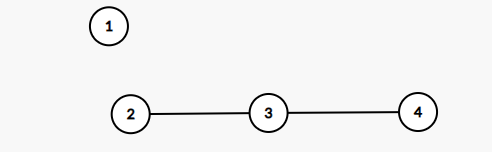
然后插入:

现在一号节点是新的头节点了。
代码实现:
node* t = new node();//c:t = (node*)malloc(sizeof(node)); t -> data = data;//第二句和第三句也可以写成构造函数 t -> next = head; head = t;
接下来讲尾插法,尾插法顾名思义也就是从新节点尾部插入。
如图:
同样先创建节点(5是新创建的节点,他也是第五个创建的节点):
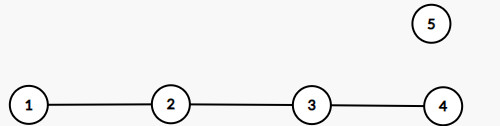
插入:

5现在成了新的尾节点。
代码实现:
/*链表插入需要考虑一种特殊情况,即链表为空的情况,为了判断这种情况我们一般会先给 head(头指针) 和 tail(尾指针)赋上一个 NULL,这是一个常量,其值为 0。 *用来表示空指针,链表的最后一个节点的 next 也要赋值为 NULL 用来标志其后没有节点了。所以合法的链表操作不会“越界”,但是要注意操作空指针会造成程序 RE。 */ if(head == NULL) { head = new node(); head -> data = data; head -> next = NULL; tail = head; } else { tail -> next = new node(); tail = tail -> next; tail -> data = data; tail -> next = NULL; }
这就是链表的两种插入方法了,他们并不是两种可以让你随便选择的方法,他们各自有各自的作用,这个等下放到后面讲。
注意!!!链表一定要记得删除,在 c/c++ 中用new 和 malloc 来分配的内存一定要 delete 或者 free 掉,否则会一直占用内存空间,造成内存泄漏。
销毁链表操作一般都是从头节点开始一个一个删除。
销毁链表代码:
while(head != NULL) { node *p = head; delete p;//c: free(p); head = head -> next; }
链表的其他操作如插入(指插在中间)、排序(因为链表的特性所以链表使用插入法居多)和删除单个节点如果你已经理解了链表的概念,能够想象或者画出一个链表,是非常简单的。所以这个留给读者自己去思考。
那么和数组相比链表有什么特点优缺点呢?
1、数组
支持随机访问。
插入速度慢(大量移位操作)。
存储密度大(不需要多余空间来存储指针)。
不可动态大小。
2、链表
不支持随机访问。
插入速度快(直接断开然后插入)。
存储密度小(需要多余空间来存储指针)。
可动态控制大小。
三、线性数据结构
好了前置知识就讲到这里接下来让我们进入正题——线性数据结构,线性数据结构主要是两种,队列和栈。
1、队列
这个队列和现实生活中的队列是差不多的,也就是先排队的人先达到目的(大家可以想象一下超市排队付款),那么用代码来表示就是这样:
int q[23333],head,tail;//q数组就是队列,head代表队头,tail代表队尾,最开始的时候队首和队尾重叠都为 0 来代表现在还没有人排队。
那么现在我们来了一个人要结账。
q[tail] = data;//排在队尾 tail++;//对尾位置已经发生改变所以+1。当然这两行还可以压成一行
排第一的人付完钱走了。
head++;//队头位置发生改变
收营员现在想知道排第一的是谁。
q[head];//head 就是队首
那可能很多小伙伴就想问拿为什么不做整体移位呢?答案是因为速度太慢了,谁也不想等待是不是,来使用这个程序的人也是不想等的。
那很多小伙伴又会问了一直这样后移那这 tail 要是越界了怎么办,这个问题,计算机大师们早就想到了,那就是使用循环队列,如果 tail 越界,那就移到 0 来,这样子,你的数组大小只需要保证队列最长的时候能够装下就行了,在计算机上这种越界称为假溢,那就是空间没用完,但是因为队列一直在整体后移而导致越界。
那当然如果用前面提到的链表来实现就没有这种问题了,思路是一样的,读者自己试试会理解的更透彻,还能顺带熟悉链表操作(在队列中插入一个节点对应尾插法)。
队列这种数据结构一般和广搜来组合使用,当然也有其他单独出现的情况。
2、栈
栈这种数据结构可以当作一个坑或者桶,那也就是最先进去埋得最深,也就越后出来。(读者可以想象一下排队被无限插队),栈的定义如下。
int s[23333],top;//s数组就是栈,top表示栈顶
取栈顶
s[top];
压栈
s[top] = data;
top++;
弹栈
top--;
函数递归调用和返回的过程就刚好对应压栈和弹栈。
同样栈也可以用链表组织。插入节点的过程就对应头插法。
四、后记
再写这篇文章的时候,笔者正在被各种树折磨。感觉陷入了瓶颈中。简单的题目对我没意义,更难的我暂时又学不会。有些数据结构是我学过的,可是他需要支持的操作我却看的一脸懵逼,让我有点怀疑自己到底学会了吗?对自己的能力产生了怀疑,索性整理复习之前所学习的内容。笔者会不定期更新线性数据结构的之后的内容——各种树, 之前的写的堆的博客姑且先归到这个系列
希望各位读者不会遇到我所遇到的困惑吧。