统计某手机数据库的每个手机号的上行数据包数量和下行数据包数量
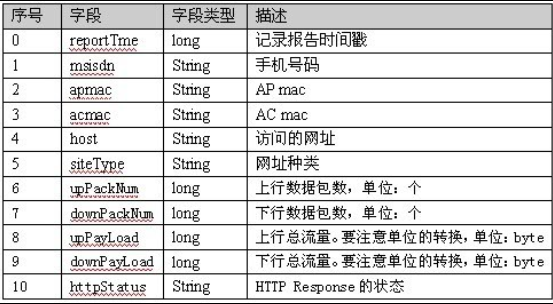
数据库类型如下:
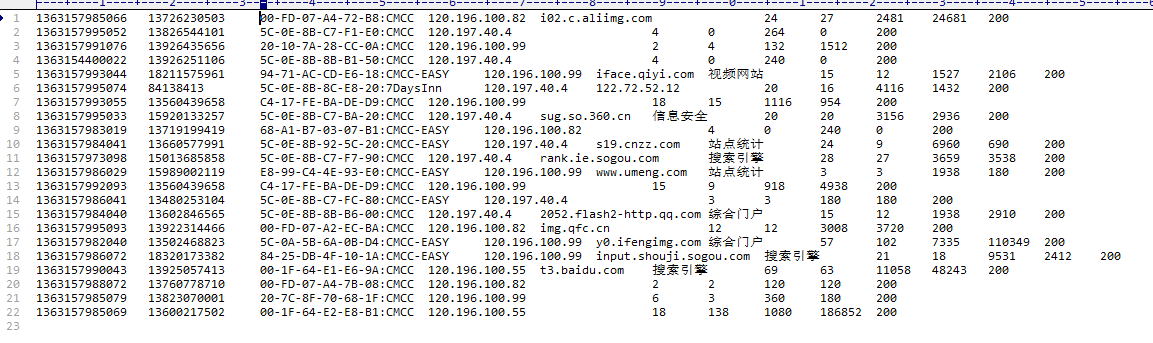
数据库内容如下:
下面自定义类型SimLines,类似于平时编写的model
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.Writable; 6 7 public class SimLines implements Writable { 8 9 long upPackNum, downPackNum; 10 11 public SimLines(){ 12 super(); 13 } 14 15 public SimLines(String upPackNum, String downPackNum) { 16 super(); 17 this.upPackNum = Long.parseLong(upPackNum); 18 this.downPackNum = Long.parseLong(downPackNum); 19 } 20 21 //反序列化 22 @Override 23 public void readFields(DataInput in) throws IOException { 24 this.upPackNum = in.readLong(); 25 this.downPackNum = in.readLong(); 26 } 27 28 //序列化 29 @Override 30 public void write(DataOutput out) throws IOException { 31 out.writeLong(upPackNum); 32 out.writeLong(downPackNum); 33 } 34 35 public String toString(){ 36 return upPackNum + " " + downPackNum; 37 } 38 }
注意:write方法中的顺序和readFields中的顺序要相同
其中的空构造方法一定要写,不然会报错或者反序列化步骤不执行。还有toString方法也必须定义,不然最后输的东西会很头疼的,不信你可以试试。
下面是hadoop的功能代码
1 import java.io.File; 2 import java.io.IOException; 3 import java.net.URI; 4 import java.net.URISyntaxException; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.Mapper; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 public class WordCount { 18 19 static final String INPUT_PATH = "F:/Tutorial/Hadoop/TestData/data/HTTP_20130313143750.dat"; 20 static final String OUTPUT_PATH = "hdfs://masters:9000/user/hadoop/output/TestPhone"; 21 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { 22 23 //添加以下的代码,就可以联通,不知道咋回事 24 String path = new File(".").getCanonicalPath(); 25 System.getProperties().put("hadoop.home.dir", path); 26 new File("./bin").mkdirs(); 27 new File("./bin/winutils.exe").createNewFile(); 28 29 Configuration conf = new Configuration(); 30 Path outpath = new Path(OUTPUT_PATH); 31 32 //检测输出路径是否存在,如果存在就删除,否则会报错 33 FileSystem fileSystem = FileSystem.get(new URI(OUTPUT_PATH), conf); 34 if(fileSystem.exists(outpath)){ 35 fileSystem.delete(outpath, true); 36 } 37 38 Job job = new Job(conf, "SimLines"); 39 40 FileInputFormat.setInputPaths(job, INPUT_PATH); 41 FileOutputFormat.setOutputPath(job, outpath); 42 43 job.setMapperClass(MyMapper.class); 44 job.setReducerClass(MyReducer.class); 45 job.setOutputKeyClass(Text.class); 46 job.setOutputValueClass(SimLines.class); 47 job.waitForCompletion(true); 48 } 49 50 //输入,map,即拆分过程 51 static class MyMapper extends Mapper<LongWritable, Text, Text, SimLines>{ 52 53 protected void map(LongWritable k1, Text v1, Context context)throws IOException, InterruptedException{ 54 String[] splits = v1.toString().split(" ");//按照空格拆分 55 Text k2 = new Text(splits[1]); 56 SimLines simLines = new SimLines(splits[6], splits[7]); 57 context.write(k2, simLines); 58 } 59 } 60 61 //输出,reduce,汇总过程 62 static class MyReducer extends Reducer<Text, SimLines, Text, SimLines>{ 63 protected void reduce( 64 Text k2, //输出的内容,即value 65 Iterable<SimLines> v2s, //是一个longwritable类型的数组,所以用了Iterable这个迭代器,且元素为v2s 66 org.apache.hadoop.mapreduce.Reducer<Text, SimLines, Text, SimLines>.Context context) 67 //这里一定设置好,不然输出会变成单个单词,从而没有统计数量 68 throws IOException, InterruptedException { 69 //列表求和 初始为0 70 long upPackNum = 0L, downPackNum = 0L; 71 for(SimLines simLines:v2s){ 72 upPackNum += simLines.upPackNum; 73 downPackNum += simLines.downPackNum; 74 } 75 SimLines v3 = new SimLines(upPackNum + "", downPackNum + ""); 76 context.write(k2, v3); 77 } 78 } 79 }
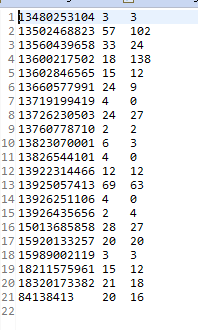
这样就ok了,结果如下: