hibernate缓存
一级缓存
u 为什么需要缓存?
看一个案例:->原理图

从上图看出: 当我们去查询对象的时候,首先到一级缓存去取数据,如果有,则不到数据库中取,如果没有则到数据库中取,同时在一级缓存中放入对象.
二级缓存
u 为什么需要二级缓存?
因为一级缓存有限(生命周期短),所以我们需要二级缓存(SessionFactory缓存)来弥补这个问题
1.需要配置
2.二级缓存是交给第三方去处理,常见的Hashtable , OSCache , EHCache
3.二级缓存的原理
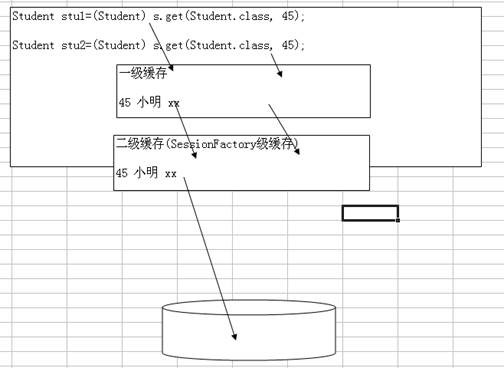
4.二级缓存的对象可能放在内存,也可能放在磁盘.
u 快速入门案例
使用OsCache来演示二级缓存的使用.
1.配置二级缓存
对配置说明:
<property name="hbm2ddl.auto">update</property>
<!-- 启动二级缓存 -->
<property name="cache.use_second_level_cache">true</property>
<!-- 指定使用哪种二级缓存 -->
<property name="cache.provider_class">org.hibernate.cache.OSCacheProvider</property>
<mapping resource="com/hsp/domain/Department.hbm.xml" />
<mapping resource="com/hsp/domain/Student.hbm.xml" />
<!-- 指定哪个domain启用二级缓存
特别说明二级缓存策略:
1. read-only
2. read-write
3. nonstrict-read-write
4. transcational
-->
<class-cache class="com.hsp.domain.Student" usage="read-write"/>
2. 可以![]() 文件放在 src目录下,这样你可以指定放入二级缓存的对象capacity 大小. 默认1000
文件放在 src目录下,这样你可以指定放入二级缓存的对象capacity 大小. 默认1000
u 为什么需要二级缓存?
因为一级缓存有限(生命周期短),所以我们需要二级缓存(SessionFactory缓存)来弥补这个问题
1.需要配置
2.二级缓存是交给第三方去处理,常见的Hashtable , OSCache , EHCache
3.二级缓存的原理
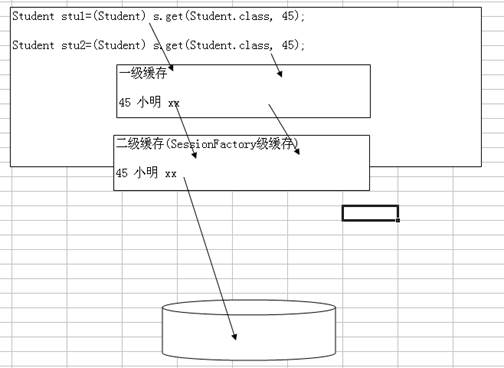
4.二级缓存的对象可能放在内存,也可能放在磁盘.
u 快速入门案例
使用OsCache来演示二级缓存的使用.
1.配置二级缓存
对配置说明:
<property name="hbm2ddl.auto">update</property>
<!-- 启动二级缓存 -->
<property name="cache.use_second_level_cache">true</property>
<!-- 指定使用哪种二级缓存 -->
<property name="cache.provider_class">org.hibernate.cache.OSCacheProvider</property>
<mapping resource="com/hsp/domain/Department.hbm.xml" />
<mapping resource="com/hsp/domain/Student.hbm.xml" />
<!-- 指定哪个domain启用二级缓存
特别说明二级缓存策略:
1. read-only
2. read-write
3. nonstrict-read-write
4. transcational
-->
<class-cache class="com.hsp.domain.Student" usage="read-write"/>
2. 可以![]() 文件放在 src目录下,这样你可以指定放入二级缓存的对象capacity 大小. 默认1000
文件放在 src目录下,这样你可以指定放入二级缓存的对象capacity 大小. 默认1000
u 主键增长策略
①increment
自增,每次增长1, 适用于所有数据库. 但是不要使用在多进程,主键类型是数值型
select max(id) from Student
② identity
自增,每次增长1, 适用于支持identity的数据(mysql,sql
server), 主键类型是数值
③ sequence
④ native
会根据数据类型来选择,使用identity,sequence ,hilo
select
hibernate_sequence.nextval from dual
主键类型是数值long , short ,int
<id name="id"
type="java.lang.Integer">
<generator
class="native"/>
</id>
⑤
hilo标识符生成器由Hibernate按照一种high/low算法生成标识符
用法:
<id name=”id” type=”java.lang.Integer” column=”ID”>
<generator
class=”
<param
name=”table”>my_hi_value</param>
<param name=”column”>next_value</param>
</generator>
</id>
⑥ uuid
会根据uuid算法,生成128-bit的字串
主键属性类型不能是数值型,而是字串型
⑦ assigned
用户自己设置主键值,所以主键属性类型可以是数值,字串
⑧ 映射复合主键
⑨ foreign
在one-to-one的关系中,有另一张表的主键(Person) 来决定 自己主键/外键( IdCard)
给出一个简单原则:
针对oracle [主键是int/long/short 建议使用 sequence] 主键是String 使用uuid或者assinged
针对 mysql [主键是 int/long/short 建议使用increment/assigend
,如果是字串 UUId/assigned]
针对 sql server [主键是 int/long/short 建议使用
identity/native/assinged ,如果主键是字串,使用uuid/assigned ]
one-to-one 又是基于主键的则使用foreign
u hibernate最佳实践(在什么项目中使用最好)
对于数据量大,性能要求高系统,不太使用使用hiberante.
主要用于事务操作比较多的项目(oa/某个行业软件[石油、税务、crm, 财务系统.]
olap->hibernate用的比较少oltp->hibernate