文档对象模型(DOM)是表示文档(比如HTML和XML)和访问、操作构成文档的各种元素的应用程序接口(API)。一般的,支持Javascript的所有浏览器都支持DOM。本文所涉及的DOM,是指W3C定义的标准的文档对象模型,它以树形结构表示HTML和XML文档,定义了遍历这个树和检查、修改树的节点的方法和属性。
7.4.1、DOM眼中的HTML文档:树
在DOM眼中,HTML跟XML一样是一种树形结构的文档,<html>是根(root)节点,<head>、<title>、<body>是<html>的子(children)节点,互相之间是兄弟(sibling)节点;<body>下面才是子节点<table>、<span>、<p>等等。如下图:
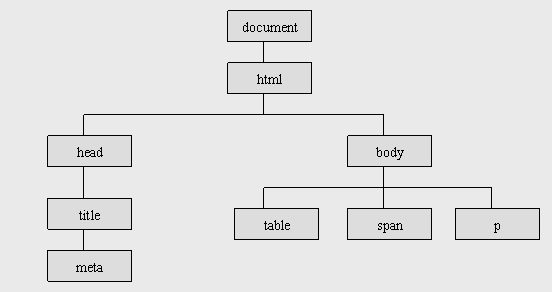
这个是不是跟XML的结构有点相似呢。不同的是,HTML文档的树形主要包含表示元素、
7.4.2、HTML文档的节点
DOM下,HTML文档各个节点被视为各种类型的Node对象。每个Node对象都有自己的属性和方法,利用这些属性和方法可以遍历整个文档树。由于HTML文档的复杂性,DOM定义了nodeType来表示节点的类型。这里列出Node常用的几种节点类型:
| 接口 | nodeType常量 | nodeType值 | 备注 |
| Element | Node.ELEMENT_NODE | 1 | 元素节点 |
| Text | Node.TEXT_NODE | 3 | 文本节点 |
| Document | Node.DOCUMENT_NODE | 9 | document |
| Comment | Node.COMMENT_NODE | 8 | 注释的文本 |
| DocumentFragment | Node.DOCUMENT_FRAGMENT_NODE | 11 | document片断 |
| Attr | Node.ATTRIBUTE_NODE | 2 | 节点属性 |
DOM树的根节点是个Document对象,该对象的documentElement属性引用表示文档根元素的Element对象(对于HTML文档,这个就是<html>标记)。Javascript操作HTML文档的时候,document即指向整个文档,<body>、<table>等节点类型即为Element。Comment类型的节点则是指文档的注释。具体节点类型的含义,请参考《Javascript权威指南》,在此不赘述。
Document定义的方法大多数是生产型方法,主要用于创建可以插入文档中的各种类型的节点。常用的Document方法有:
| 方法 | 描述 |
| createAttribute() | 用指定的名字创建新的Attr节点。 |
| createComment() | 用指定的字符串创建新的Comment节点。 |
| createElement() | 用指定的标记名创建新的Element节点。 |
| createTextNode() | 用指定的文本创建新的TextNode节点。 |
| getElementById() | 返回文档中具有指定id属性的Element节点。 |
| getElementsByTagName() | 返回文档中具有指定标记名的所有Element节点。 |
对于Element节点,可以通过调用getAttribute()、setAttribute()、removeAttribute()方法来查询、设置或者删除一个Element节点的性质,比如<table>标记的border属性。下面列出Element常用的属性:
| 属性 | 描述 |
| tagName | 元素的标记名称,比如<p>元素为P。HTML文档返回的tabName均为大写。 |
Element常用的方法:
| 方法 | 描述 |
| getAttribute() | 以字符串形式返回指定属性的值。 |
| getAttributeNode() | 以Attr节点的形式返回指定属性的值。 |
| getElementsByTabName() | 返回一个Node数组,包含具有指定标记名的所有Element节点的子孙节点,其顺序为在文档中出现的顺序。 |
| hasAttribute() | 如果该元素具有指定名字的属性,则返回true。 |
| removeAttribute() | 从元素中删除指定的属性。 |
| removeAttributeNode() | 从元素的属性列表中删除指定的Attr节点。 |
| setAttribute() | 把指定的属性设置为指定的字符串值,如果该属性不存在则添加一个新属性。 |
| setAttributeNode() | 把指定的Attr节点添加到该元素的属性列表中。 |
Attr对象代表文档元素的属性,有name、value等属性,可以通过Node接口的attributes属性或者调用Element接口的getAttributeNode()方法来获取。不过,在大多数情况下,使用Element元素属性的最简单方法是getAttribute()和setAttribute()两个方法,而不是Attr对象。
7.4.3、使用DOM操作HTML文档
Node对象定义了一系列属性和方法,来方便遍历整个文档。用parentNode属性和childNodes[]数组可以在文档树中上下移动;通过遍历childNodes[]数组或者使用firstChild和nextSibling属性进行循环操作,也可以使用lastChild和previousSibling进行逆向循环操作,也可以枚举指定节点的子节点。而调用appendChild()、insertBefore()、removeChild()、replaceChild()方法可以改变一个节点的子节点从而改变文档树。
需要指出的是,childNodes[]的值实际上是一个NodeList对象。因此,可以通过遍历childNodes[]数组的每个元素,来枚举一个给定节点的所有子节点;通过递归,可以枚举树中的所有节点。下表列出了Node对象的一些常用属性和方法:
Node对象常用属性:
| 属性 | 描述 |
| attributes | 如果该节点是一个Element,则以NamedNodeMap形式返回该元素的属性。 |
| childNodes | 以Node[]的形式存放当前节点的子节点。如果没有子节点,则返回空数组。 |
| firstChild | 以Node的形式返回当前节点的第一个子节点。如果没有子节点,则为null。 |
| lastChild | 以Node的形式返回当前节点的最后一个子节点。如果没有子节点,则为null。 |
| nextSibling | 以Node的形式返回当前节点的兄弟下一个节点。如果没有这样的节点,则返回null。 |
| nodeName | 节点的名字,Element节点则代表Element的标记名称。 |
| nodeType | 代表节点的类型。 |
| parentNode | 以Node的形式返回当前节点的父节点。如果没有父节点,则为null。 |
| previousSibling | 以Node的形式返回紧挨当前节点、位于它之前的兄弟节点。如果没有这样的节点,则返回null。 |
Node对象常用方法:
| 方法 | 描述 |
| appendChild() | 通过把一个节点增加到当前节点的childNodes[]组,给文档树增加节点。 |
| cloneNode() | 复制当前节点,或者复制当前节点以及它的所有子孙节点。 |
| hasChildNodes() | 如果当前节点拥有子节点,则将返回true。 |
| insertBefore() | 给文档树插入一个节点,位置在当前节点的指定子节点之前。如果该节点已经存在,则删除之再插入到它的位置。 |
| removeChild() | 从文档树中删除并返回指定的子节点。 |
| replaceChild() | 从文档树中删除并返回指定的子节点,用另一个节点替换它。 |
下表是只读类型的属性:
|
DOM对象属性
|
返 回 值
|
| FirstChild | 返回一个对象(Object),表示第一个孩子节点(child node)。 |
| LastChild | 返回一个对象(Object),表示最后一个孩子节点(child node)。 |
| NextSibling | 返回一个对象(Object),表示下一个相邻的兄弟节点。 |
| NodeName | 返回节点对应的HTML标记。比如:P,Script。对应文本项节点,返回#text。 |
| nodeType | 返回节点的类型, 1表示此节点是标记(tag), 2表示属性(attribute), 3表示文本项。 |
| parentNode | 返回一个对象(Object),表示当前节点的双亲节点(parent node)。 |
| previousSibling | 返回一个对象(Object),表示前一个相邻的兄弟节点。 |
| specified | 返回一个布尔型变量(Boolean),表示是否设置了属性值(attribute)。 |
下表是可读写类型的属性:
|
DOM对象属性
|
返 回 值
|
| data | 返回一个字符串,表示文本项节点的值。如果是其他类型节点,返回undefined。 |
| nodeValue | 返回一个字符串,表示文本项节点的值。如果是其他类型节点,返回null。 |
下表是DOM中相关属性集合:
|
DOM对象属性
|
返 回 值
|
| attributes | 表示节点的属性集合,通过id来访问,比如attributes.id。 |
| childNodes | 表示节点的孩子节点集合,通过数组索引方式访问,比如:childNodes[2]。 |
包含表格的文档的DOM结构分析
一般而言,DOM结构准确地反映了HTML文档所包含的内容,也就是说,每个HTML标记表现为一个标记节点(tag node),每个文本项内容表现为一个文本项节点(text node)。这种表现形式一般称为WYSIWYG,即所见即所得。但是,<TABLE>标记是一个例外情况。当有<TABLE>标记时,我们可以设想它另外包含一对<TBODY>标记。来看看下面的一段代码:
<TABLE ID="tableNode">
<TR><TD BGCOLOR="yellow">This is row 1, cell 1</TD><TD BGCOLOR="orange">This is row 1, cell 2</TD></TR>
<TR><TD BGCOLOR="red">This is row 2, cell 1</TD><TD BGCOLOR="magenta">This is row 2, cell 2</TD></TR>
<TR><TD BGCOLOR="lightgreen">This is row 3, cell 1</TD><TD BGCOLOR="beige">This is row 3, cell 2</TD></TR>
</TABLE>
在分析它的DOM结构前,我们要为这段代码添加上一对<TBODY>标记:
<TABLE ID="tableNode">
<TBODY>
中间代码略
</TBODY>
</TABLE>
经过这样的处理,DOM结构可以分析如下:Tree的根是<TABLE>标记节点,它只包含一个孩子节点<TBODY>;<TBODY>标记节点又包含3个孩子节点,每一个节点对应一个表格行<TR>;每个<TR>标记节点包含2个孩子节点,每一个节点对应表格行的一个单元<TD>;每个<TD>标记节点包含孩子节点,也就是一个文本项节点,它表示了单元格的内容。
右面是上述HTML文档的DOM Tree图示,可点击放大。
{kind=link}
包含表格文档的节点导航
现在我们来看看如何在包含表格的文档中进行DOM节点导航。同样,正确地理解上面所示的DOM Tree图示,有助于我们清晰地看懂导航节点表达式
JS应用DOM入门:和DHTML对象模型的比较
DOM是文档对象化模型(Document Object Model)的简称。使用过DHTML对象模型的开发者一定能非常熟练地操作HTML页面上的每个标记内容,但如果借助DOM技术,我们就可以通过更加直接而且简易的方式达到同样的目的。
概要
DOM技术被Internet Explorer 5.0及以上版本的浏览器所支持,它采取一种非常直观且一致的方式将HTML文档进行模型化处理,并借此提供访问、导航和操作页面的简易编程接口。通过DOM技术,我们不仅能够访问和更新页面的内容及结构,而且还能操纵文档的风格样式。DOM由W3C组织所倡导,这样,大多数浏览器都将最终支持这项技术。
DOM和DHTML对象模型的比较
可以这么说,DOM是从DHTML对象模型发展而来的。但更准确而言,DOM更象是对DHTML对象模型进行了根本变革的产物。
借助DHTML对象模型技术,我们能够单独地访问并更新HTML页面上的对象,每个HTML标记通过它的ID和NAME属性被操纵,每个对象都具有自己的属性、方法和事件,通过方法操纵对象,通过事件触发因果过程。
DOM则要比DTHML对象模型功能更全面,它提供了一个对整个文档的访问模型,而不仅仅再局限于单一的HTML标记(Tag)范围内。DOM将文档描绘为一个树形(Tree)结构,Tree的每个节点表现为一个HTML标记或者HTML标记内的文本项。树形结构精确地描述了HTML文档中标记间以及文本项间的相互关联性,这种关联性包括child(孩子)类型、parent(双亲)类型和兄弟(sibling)类型。
使用DHTML对象模型访问和更新HTML页面内容时,不可避免地需要查询相关技术手册。因为HTML对象很多,每个HTML对象又有很多的属性、方法和事件。但是采用DOM技术访问和更新HTML页面内容时,任何手册都可以放在一边了。首先查看一下HTML源代码,推算出页面的Tree结构模型;然后,按照层次结构关系操纵需要的属性。比如要更新页面上的文本项内容,如果采用DTHML对象模型,需要使用到innerHTML属性,但必须要注意并不是所有的HTML对象都支持innerHTML属性;如果采用DOM技术,只要修改相关Tree节点都具有的nodeValue属性值即可。
DOM技术使我们可以方便地沿着文档的树型结构在上、下以及一侧方向做节点导航,从页面的任何地方开始,使用child、parent或者sibling三种关联性组成的表达式代表页面的另外地方。而DTHML对象模型不包含Tree结构,所以也就不具备页面对象的相互导航功能。当我们从一个标记对象开始时,不可能用关联表达式来表达相近的标记。虽然对于某些标记,比如 <TABLE> ,DHTML对象模型可以提供特殊的属性和方法存取相关内容,但实现方式和效果远不如DOM技术显得一致化和直观化。采用DTHML对象模型访问<TABLE> 中的单元(cell)内容时,首先要查询手册确定单元的坐标值i、j,然后再通过表达式tableObj.rows[i].cells[j].innerHTML实现访问。但对于DOM来说,访问TABLE每个单元的内容将变得非常简单,只需要建立一个节点导航表达式就可以。
另外,DOM技术允许我们操纵文档的Tree结构,这包括创建新节点(nodes)、删除存在的节点以及在Tree中移动节点。实际上,这就是执行创建新标记(tags)、删除存在的标记以及在文档中移动标记的过程。DTHML对象模型则不允许更改文档结构,我们只能操纵现有的对象。
与DHTML对象模型相比较,DOM只有一个缺憾:DOM不能支持事件处理,而DTHML对象模型对于文档对象则拥有一个广泛的事件处理功能。
本文来自http://www.cnblogs.com/slfyeye/articles/850247.html同大家分享~