python基础知识清单
-



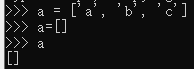
- python可以清空列表
- 嵌套列表

- range遍历数字序列,以合法的索引生成长度为*的序列
- range也可以以另一个数字开头,或者以指定的幅度增加(甚至是负数;有时这也被叫做 '步进')

- python默认会换行,不需要换行在变量末尾加end=" ";
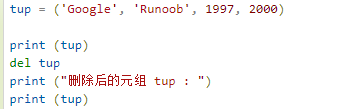
- 元组中的元素值是不允许修改的,但我们可以对元组进行连接组合

- 元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
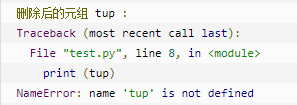
- 以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
- 元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用
- 字典
- 修改字典,向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对
- pycharm:Ctrl+shift+- 代码全部折叠,Ctrl+shift+代码全部展开

- 创建一个新的python文件:Alt+insert;运行:shift+F10,在中文状态下,Ctrl+shift+b(调出win表情包) 快速查看文档:Ctrl + Q;代码格式化:Ctrl + Alt + L;调试:Shift + F9;文件中用法高亮显示:Ctrl + Shift + F7;显示用法:Ctrl + Alt + F7;全局查找/全局替换:Ctrl + Shift + F/Ctrl + Shift + R;显示错误描述或警告信息:Ctrl + F1;快速查看文档:Ctrl + Q;自动生成代码:Alt + Insert;Ctrl + F /R : 当前文件查找/替换

- 以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
- 字符型:%.2f保留两位小数




- 格式化字符串除了%s,还有f{'表达式'},

- 在python中,用户


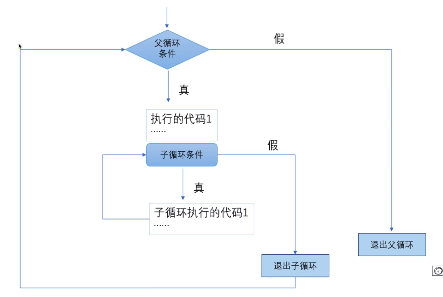
- 循环:当内部循环执行完成之后,再执行下一次外部循环的条件判断,循环的执行流程:
- 字符串单双三引号都可以,三引号的字符串支持回车换行,单双引号换行时后面会加上
,



- 列表可以一次性储存多个数据,且可以为不同数据类型。
- 列表的循环遍历:依次打印列表中的各个数据,while 、for
- 列表的常用:增删改查(index()、count()、in、not in、{append():列表追加数据,如果append()追加的数据是⼀个序列,则追加整个序列到列表;extend():列表结尾追加数据,如果数据是⼀个序列,则将这个序列的数据逐⼀添加到列表;insert():指定位置新增数据,列表序列.insert(位置下标, 数据)。} {del() 删除列表、 删除指定数据。pop():删除指定下标的数据(默认为最后⼀个),并返回该数据,语法: 列表序列.pop(下标); remove():移除列表中某个数据的第⼀个匹配项,语法:列表序列.remove(数据)} 逆置:reverse(),排序:sort(),函数:copy() 列表嵌套
- 字符串单双三引号都可以,三引号的字符串支持回车换行,单双引号换行时后面会加上
,
- ⼀个元组可以存储多个数据,元组内的数据是不能修改的。支持查找,为不可变类型,但元组里嵌套的列表则可以修改。 例如保存身份证
- 字典里的数据以键值对形式出现,字典数据和数据顺序没有关系,字典不支持下标,后期数据无论如何变化,只需按照对应的名字查找数据即可
- 一般称冒号前面的为键(key),冒号后面的为值,称value
- 字典常见操作:增,写法:字典序列[key]=值;删:del(),删除字典或删除字典中指定键值对;清空列表:clear();改:字典序列[key] = 值(如果key存在则修改这个key对应的值 ;如果key不存在则新增此键值对。);查:key值查找(如果当前查找的key存在,则返回对应的值;否则则报错;get() ,语法:字典序列.get(key, 默认值))
- keys()、values()、items()
- 字典的遍历:遍历字典的key、遍历字典的value、遍历字典的元素、遍历字典的键值对
- 定义字典:dict1={'name':'python', 'age':30}、dict2={}、dict3=dict()
- 增/改:字典序列[key]=值
- 查找
- 字典序列[key]
- keys()
- values()
- items()
- 集合:创建集合使⽤ {} 或 set() , 但是如果要创建空集合只能使⽤ set() ,因为 {} ⽤来创建空字典。集合无序,无下标。集合可以去掉重复数据
- 集合常见操作方法
- 创建集合
- 有数据集合:s1 = {数据1, 数据2, ...}
- 无数据集合:s1 = set()
- 增加数据:add(),因为集合有去重功能,所以,当向集合内追加的数据是当前集合已有数据的话,则不进⾏任何操 作。update(), 追加的数据是序列。
- 删除数据:remove(),删除集合中的指定数据,如果数据不存在则报错。discard(),删除集合中的指定数据,如果数据不存在也不会报错。pop(),随机删除集合中的某个数据,并返回这个数据。
- 查找数据:in:判断数据在集合序列;not in:判断数据不在集合序列
- 创建集合
- 公共操作
- 运算符

- 公共方法(注意:range()生成的序列不包含end数字)

- enumerate() ,语法:enumerate(可遍历对象, start=0);start参数⽤来设置遍历数据的下标的起始值,默认为0。
- 容器类型转换:(注意: 集合可以快速完成列表去重;集合不⽀持下标)
- tuple():将某个序列转换成元组,例如列表、字典等
- list()::将某个序列转换成列表,例如元组、字典等
- set():将某个序列转换成集合,例如列表、元组等
- 推导式:
- 列表推导式:化简代码:创建或者控制有规律的列表。列表推导式⼜叫列表⽣成式。
- while循环创建有规律的列表

- for循环创建有规律的列表

- while循环创建有规律的列表
- 列表推导式实现

- 带if的列表推导式

- 多个for循环实现列表推导式(等同于for循环嵌套)

- 字典推导式:快速合并列表为字典或提取字典中⽬标数据。
- 快速体验:1. 创建⼀个字典:字典key是1-5数字,value是这个数字的2次⽅。

- 总结:
- 1. 如果两个列表数据个数相同,len统计任何一个列表的长度都可以
- 2. 如果两个列表数据个数不同,len统计数据多的列表数据个数会报错;len统计数据少的列表数据个数不会报错
- 集合推导式:

- 快速体验:1. 创建⼀个字典:字典key是1-5数字,value是这个数字的2次⽅。
- 推导式总结:
- 推导式的作⽤:简化代码
- 推导式写法

- 函数
- 函数的作用:函数就是将⼀段具有独⽴功能的代码块 整合到⼀个整体并命名,在需要的位置调⽤这个名称即可完成对 应的需求。函数在开发过程中,可以更⾼效的实现代码重⽤。
- 封装代码,高效的代码重用
- 函数的使用步骤:
- 1.定义函数

- 调用函数:函数名(参数)

- 1.定义函数
- 1
- 函数的注意事项:
- 1. 函数先定义后调用,如果先调用会报错
- 2. 如果没有调用函数,函数里面的代码不会执行
- 3. 函数执行流程: 当调用函数的时候,解释器回到定义函数的地方去执行下方缩进的代码,当这些代码执行完,回到调用函数的地方继续向下执行 定义函数的时候,函数体内部缩进的代码并没有执行
- 函数的注意事项:
- 函数参数:作用:使函数变得更灵活
- return:返回结果到函数调用的地方,语法:return 表达式

- return:返回结果到函数调用的地方,语法:return 表达式
- 函数的说明文档:定义函数的第一行缩进的多行注释
- 1

- 查看函数的说明文档:help(函数名)
- 函数说明文档的高级使用

- 1
- 函数嵌套调用:是⼀个函数⾥⾯⼜调⽤了另外⼀个函数。函数调用执行定义函数缩进的代码

- 函数的作用:函数就是将⼀段具有独⽴功能的代码块 整合到⼀个整体并命名,在需要的位置调⽤这个名称即可完成对 应的需求。函数在开发过程中,可以更⾼效的实现代码重⽤。
- 函数二
- 变量作用域:
- 局部变量:定义在函数体内部的变量,之在函数体内部生效
- 作用:在函数内部,临时保存数据,即当函数调用完成之后,则销毁局部变量。可在函数内部访问,在函数外部访问会报错
- 全局变量:在函数体内、外都能生效的变量
- 修改全局变量:在函数体内修改全局变量:先global声明a为全局变量,然后再变量重新赋值

- 多函数程序执行流程
- 函数返回值作为参数传递:
- 1.保存函数的返回值
- 将函数返回值所在变量作为参数传递到函数中

- 函数的多个返回值:语法:return a,b 默认的是返回是元组,(a,b)
- return 后面可以连接列表、元组或字典,以返回多个值
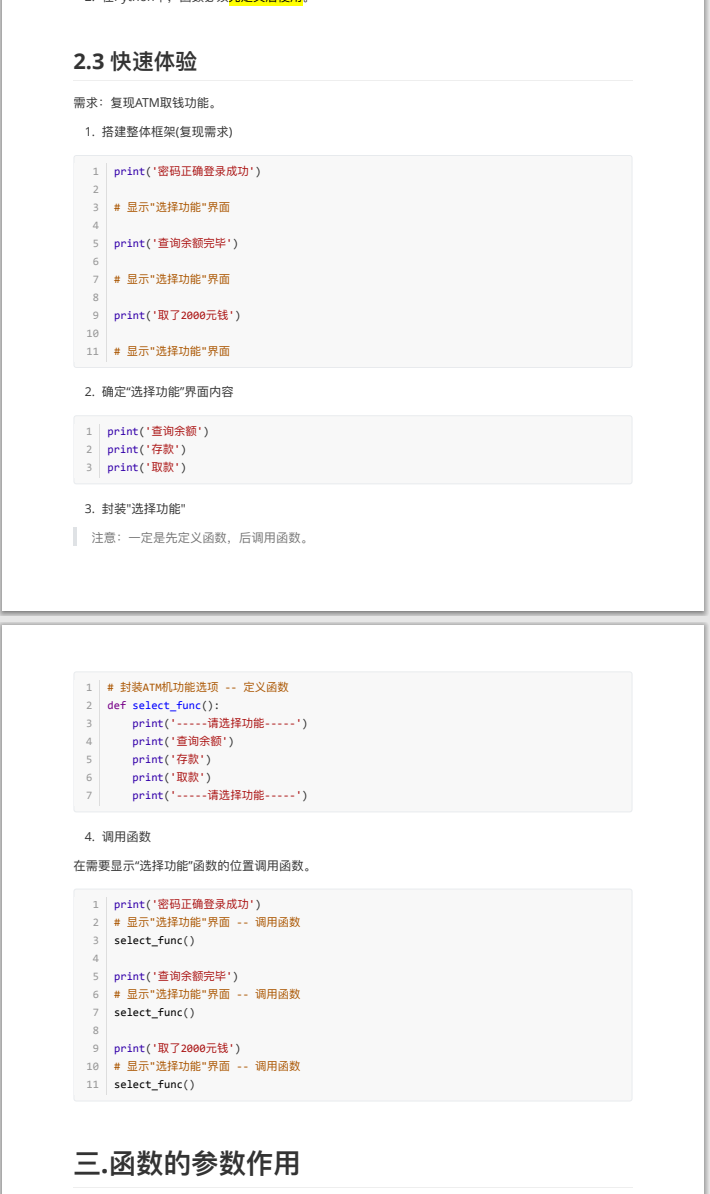
- 函数参数
- 位置参数:调用函数时根据函数定义的参数位置来传递参数。注意:传递和定义参数的顺序及个数必须一致
- 关键字参数:函数调用,通过“键=值”形式加以指定。可以让函数更加清晰、容易使⽤,同时也清除了参数的顺序需 求。

- 注意::函数调⽤时,如果有位置参数时,位置参数必须在关键字参数的前⾯,但关键字参数之间不存在 先后顺序。
- 缺省参数:也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值,注意:所有位置参数必须出现在默认参数前,包括函数定义和调⽤。
- 注意:函数调⽤时,如果为缺省参数传值则修改默认参数值;否则使⽤这个默认值。
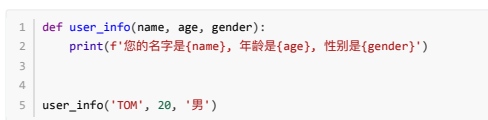
- 不定长参数:也叫可变参数。⽤于不确定调⽤的时候会传递多少个参数(不传参也可以)的场景。此时,可 ⽤包裹(packing)位置参数,或者包裹关键字参数,来进⾏参数传递,会显得⾮常⽅便。
- 包裹位置传递:

- 注意::传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为⼀个元组(tuple), args是元组类型,这就是包裹位置传递。
- 包裹关键字传递:返回的是一个字典
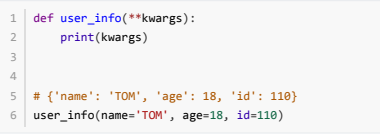
- 综上:⽆论是包裹位置传递还是包裹关键字传递,都是⼀个组包的过程。
- 包裹位置传递:
- 拆包:
- 拆包元组:

- 拆包字典:按key查找

- 拆包元组:
- 位置参数:调用函数时根据函数定义的参数位置来传递参数。注意:传递和定义参数的顺序及个数必须一致
- 交换变量的值:
- 方法一:定义中间的第三变量,为了临时存储a或b的数据

- 方法二:将、a,b分别赋值,再将a,b交换变量,然后打印出来

- 方法一:定义中间的第三变量,为了临时存储a或b的数据
- 了解引用
- 在python中,值是靠引⽤来传递来的。
- 我们可以⽤ id() 来判断两个变量是否为同⼀个值的引⽤。 我们可以将id值理解为那块内存的地址标 识。
- int为不可变类型,修改数据后ID改变。列表为可变类型,修改数据后ID不变。
- 因为修改了a的数据,内存要开辟另外一份内存取存储2,id检测a和b的地址不同
- 引用当做实参:
- int:计算前后id值不同
- 列表:计算前后id值相同
- 局部变量:定义在函数体内部的变量,之在函数体内部生效
- 可变类型与不可变类型是指:数据能够直接进⾏修改,如果能直接修改那么就是可变,否则是不可 变.
- 可变类型:列表、字典、集合
- 不可变类型:整型、浮点数、字符串、元组
- 变量作用域:
- 函数加强:
- 制作学员管理系统
- 递归:
- 应用场景:要遍历⼀个⽂件夹下⾯所有的⽂件,通常会使⽤递归来实现;
- 递归的特点:函数内部⾃⼰调⽤⾃⼰;必须有出⼝。
- 如果没有出口,报错:超出最大递归深度
- lambda:也叫匿名函数
- 应用场景:如果⼀个函数有⼀个返回值,并且只有⼀句代码,可以使⽤ lambda简化。
- 语法:lambda 参数列表 : 表达式
- 注意:lambda表达式的参数可有可⽆,函数的参数在lambda表达式中完全适⽤。 lambda函数能接收任何数量的参数但只能返回⼀个表达式的值
- 例子:

- lambda实例:计算两个数之和

- lambda的参数形式:
- 无参数:

- 一个参数:

- 默认参数:(缺省参数)

- 可变参数:**args

- 可变参数:**kwargs(返回的是字典)

- 无参数:
- lambda的应用:

- 列表数据按字典key的值排序

- 高阶函数:把函数作为参数传⼊
- abs() 函数:对数字求绝对值计算。
- round()函数:对数字四舍五入
- 高阶函数实验:

- 内置的高阶函数:
- map()
- map(func, list),将传⼊的函数变量func作⽤到lst变量的每个元素中,并将结果组成新的列表(Python2)/ 迭代器(Python3)返回。

- reduce():功能函数每次计算的结果和序列的下一个数据作累计计算。reduce(func(x,y),list),其中func必须有两个参数。

- filter():filter(func, lst)函数⽤于过滤序列, 过滤掉不符合条件的元素, 返回⼀个 filter 对象,。如果要转换为列表, 可以使⽤ list() 来转换。

- map(func, list),将传⼊的函数变量func作⽤到lst变量的每个元素中,并将结果组成新的列表(Python2)/ 迭代器(Python3)返回。
- map()
- 文件
- 把⼀些内容(数据)存储存放起来,可以让程序下⼀次执⾏的时候直接使 ⽤,⽽不必重新制作⼀份,省时省⼒。
- 文件的基本操作:注意:可以只打开和关闭⽂件,不进⾏任何读写操作。
- 1.打开文件(r:只读,如果文件不存在,会报错。不支持写作操作,表示只读)


- 2.读写等操作(w:只写,如果文件不存在,新建文件;执行写入,会覆盖原有内容)
- 3.关闭文件
- a:追加,如果文件不存在,新建文件;在原有内容基础上,追加新内容
- 访问模式参数可以省略, 如果省略表示访问模式为r
- 1.打开文件(r:只读,如果文件不存在,会报错。不支持写作操作,表示只读)
- 读取函数:
- read():

- 文件内容如果换行,底层有 ,会有字节占位,导致read书写参数读取出来的眼睛看到的个数和参数值不匹配。read不写参数表示读取所有;
- readlines():以按照⾏的⽅式把整个⽂件中的内容进⾏⼀次性读取,并且返回的是⼀个列表,其中每⼀⾏ 的数据为⼀个元素。

- readline():⼀次读取⼀⾏内容。

- seek():⽤来移动⽂件指针。
- 语法:⽂件对象.seek(偏移量, 起始位置) 0开头1当前2结尾

- 语法:⽂件对象.seek(偏移量, 起始位置) 0开头1当前2结尾
- 文件备份:
- 步骤:

- 步骤:
- 文件和文件夹的操作
- 在Python中⽂件和⽂件夹的操作要借助os模块⾥⾯的相关功能,具体步骤如下:
- 1. 导⼊os模块:import os
- 2. 使⽤ os 模块相关功能:os.函数名()
- ⽂件重命名:os.rename(⽬标⽂件名, 新⽂件名)
- 删除⽂件:os.remove(⽬标⽂件名)
- 创建⽂件夹:os.mkdir(⽂件夹名字)
- 删除⽂件夹:os.rmdir(⽂件夹名字)
- 获取当前⽬录: os.getcwd()
- 改变默认⽬录 :os.chdir(⽬录)
- 获取⽬录列表 :os.listdir(⽬录)
- 在Python中⽂件和⽂件夹的操作要借助os模块⾥⾯的相关功能,具体步骤如下:
- read():
- 总结

- 带if的列表推导式
- 列表推导式:化简代码:创建或者控制有规律的列表。列表推导式⼜叫列表⽣成式。
- 运算符
- 面向对象
- 类是对⼀系列具有相同特征和⾏为的事物的统称,是⼀个抽象的概念,不是真实存在的事物。对象是类创建出来的真实存在的事物,例如:洗⾐机。
- 特征即是属性
- ⾏为即是⽅法
- 创建对象 语法:对象名 = 类名()
- self:是调⽤该函数的对象。
- 一个类可以创建多个对象,当对象调用函数时,self地址不相同
- 添加和获取对象属性(对象属性既可以在类外⾯添加和获取,也能在类⾥⾯添加和获取。)
- 在类外面添加对象属性 语法:对象名.属性名 = 值
- 类外⾯获取对象属性 语法:对象名.属性名
- 体验:

- 在类里面获取对象属性 语法:self.属性名
- 体验

- 体验
- 体验:
- 魔法方法
- __init__ () 方法 作用:初始化对象
- __init__() ⽅法,在创建⼀个对象时默认被调⽤,不需要⼿动调⽤
- __init__(self) 中的self参数,不需要开发者传递,python解释器会⾃动把当前的对象引 ⽤传递过去。

- 带参数的__init__():一个类创建多个对象,可以通过传参对不同的对象设置不同的初始化值

- __init__ () 方法 作用:初始化对象
- __str__():会打印从 在这个⽅法中 return 的数据。

- __del__():当删除对象时,python解释器也会默认调⽤ __del__() ⽅法。
- 魔法方法

- 类是对⼀系列具有相同特征和⾏为的事物的统称,是⼀个抽象的概念,不是真实存在的事物。对象是类创建出来的真实存在的事物,例如:洗⾐机。
- 集合常见操作方法
- 继承:是多个类之间的所属关系,即⼦类默认继承⽗类的所有属性和⽅法
- 注意:在Python中,所有类默认继承object类,object类是顶级类或基类;其他⼦类叫做派⽣类。
- 多继承:是⼀个类同时继承了多个⽗类
- 注意:当⼀个类有多个⽗类的时候,默认使⽤第⼀个⽗类的同名属性和⽅法。
- ⼦类重写⽗类同名⽅法和属性:如果⼦类和⽗类具有同名属性和⽅法,子类创建对象调用属性和方法,调用的是子类里面同名的属性和方法

- 显示类的继承关系:语法:print(类名._mro_)
- 子类调⽤⽗类的同名⽅法和属性
- 多层继承
- super:调用父类方法
- 有参数: super(当前类名, self).函数()
- 无参数: super().函数()
- 注意:使⽤super() 可以⾃动查找⽗类。调⽤顺序遵循 __mro__ 类属性的顺序。⽐较适合单继承 使⽤。
- 私有权限:
- 定义私有属性和⽅法:在属性名和⽅法名 前⾯ 加上两个下划线 __。
- 作用:即设置某个实例属性或实例⽅法不继承给⼦类。
- 注意:私有属性和私有⽅法只能在类⾥⾯访问和修改。
- 获取和修改私有属性

- 定义私有属性和⽅法:在属性名和⽅法名 前⾯ 加上两个下划线 __。
- 面向对象

- 多态:是指⼀类事物有多种形态,(⼀个抽象类有多个⼦类,因⽽多态的概念依赖于继承)。 定义:多态是⼀种使⽤对象的⽅式,⼦类重写⽗类⽅法,调⽤不同⼦类对象的相同⽗类⽅法,可以 产⽣不同的执⾏结果
- 实现多态的步骤:

- 类属性和实例属性
- 类属性
- 设置和访问类属性


- 修改类属性:类属性只能通过类对象修改,不能通过实例对象修改,如果通过实例对象修改类属性,表示的是创建了 ⼀个实例属性。
- 设置和访问类属性
- 实例属性:实例属性不能通过类访问
- 类属性
- 类方法和静态方法
- 类方法


- 静态方法

- 异常
- 写法

- 异常的类型:在控制台报错的最后一句
- 捕获异常


- 异常的else : else表示的是如果没有异常要执⾏的代码。
- 异常的finally:finally表示的是⽆论是否异常都要执⾏的代码,例如关闭⽂件。
- 扩展命令提示符运行py文件
- 异常的传递
- 自定义异常
- 总结

- 写法
- 类方法
- range也可以以另一个数字开头,或者以指定的幅度增加(甚至是负数;有时这也被叫做 '步进')