数组与集合的区别
数组可以看作是一种集合,但是数组初始化后大小不可变;数组只能按索引顺序存取。
https://www.cnblogs.com/tiandi/p/10641773.html
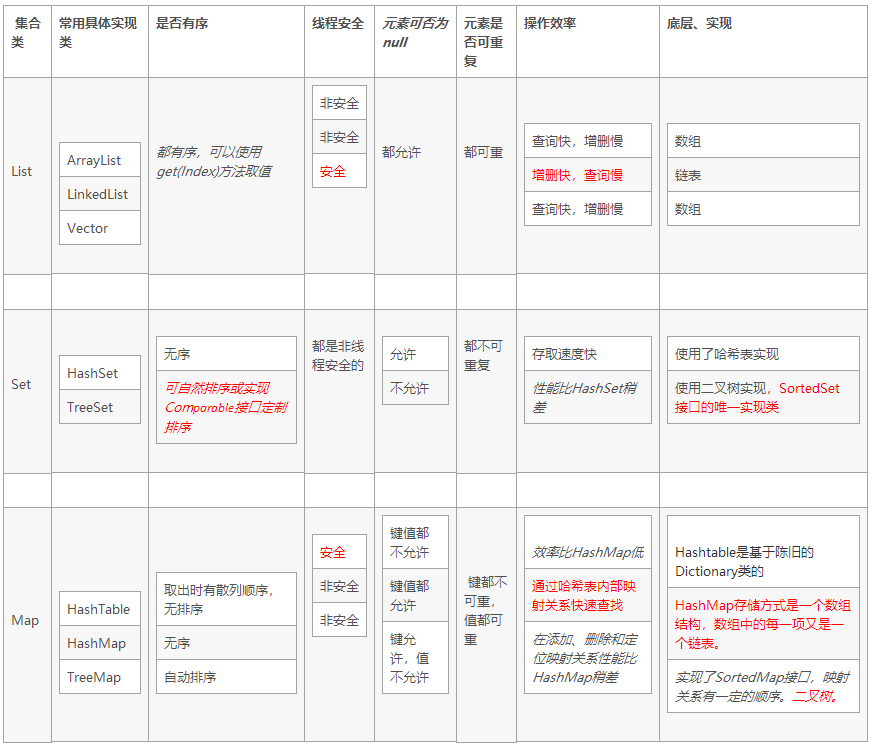
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合
List,继承Collection,可重复、有序的对象
Set,继承Collection,不可重复、无序的对象
Map,键值对,提供key到value的映射。key无序、唯一;value无序,可重复

重写equals方法
如果你创建了一个自己编写的类List,那么你需要重写equals方法,不然无法正确的判断某个对象是否在List中(contains()、indexOf())。https://www.liaoxuefeng.com/wiki/1252599548343744/1265116446975264#0
Map
遍历
对Map来说,要遍历key可以使用for each循环遍历Map实例的keySet()方法返回的Set集合,它包含不重复的key的集合:
Map和List不同的是,Map存储的是key-value的映射关系,并且,它不保证顺序。在遍历的时候,遍历的顺序既不一定是put()时放入的key的顺序,也不一定是key的排序顺序。使用Map时,任何依赖顺序的逻辑都是不可靠的。以HashMap为例,假设我们放入"A","B","C"这3个key,遍历的时候,每个key会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历的输出顺序都是不同的!
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (String key : map.keySet()) {
Integer value = map.get(key);
System.out.println(key + " = " + value);
}
}
}
hashMap 源码阅读
https://blog.csdn.net/crpxnmmafq/article/details/75331318
static final int MIN_TREEIFY_CAPACITY = 64;
-> 树形最小容量:哈希表的最小树形化容量,超过此值允许表中桶转化成红黑树
static final int TREEIFY_THRESHOLD = 8;
-> 树形阈值:当链表长度达到8时,将链表转化为红黑树
static final int UNTREEIFY_THRESHOLD = 6;
-> 树形阈值:当链表长度小于6时,将红黑树转化为链表
int threshold; -> 可存储key-value 键值对的临界值 需要扩充时;值 = 容量 * 加载因子
hashMap有一个十分有意思的函数 tableSizeFor();
https://www.liangzl.com/get-article-detail-28281.html
连接内的源码是java8的,现在的Java13的函数作用相同,但是实现方法已经是-1>>>n
-1补码为111111111(全为1),而>>>又是无符号操作。
2、“当两个对象的hashcode相同会发生什么?”
因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用LinkedList存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在LinkedList中。(当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置。当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false)。),此时若你能讲解JDK1.8红黑树引入,面试官或许会刮目相看。
3、“如果两个键的hashcode相同,你如何获取值对象?”
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。如果有两个值对象储存在同一个bucket,将会遍历LinkedList直到找到值对象。找到bucket位置之后,会调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象。(当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。)
hashCode()返回的int范围高达±21亿,先不考虑负数,HashMap内部使用的数组得有多大?
实际上HashMap初始化时默认的数组大小只有16,任何key,无论它的hashCode()有多大,都可以简单地通过:
int index = key.hashCode() & 0xf; // 0xf = 15
源码中的实现看https://blog.csdn.net/qq_42034205/article/details/90384772
为什么说hash之后的下标是均匀的(length-1)https://blog.csdn.net/yyyCHyzzzz/article/details/78516088
jdk1.7:
static int indexFor(int h, int length) {
return h & (length-1);
//由于length永远是2的幂次方,即补码为100……000,-1之后为111……111,这样&之后可以是奇数也可以是偶数
//在最小jdk中是get函数中的tab[i=(n-1)&hash]
}
jdk1.8
因为对自己改造过的哈希大量冲突时的红黑树有信心,所以简单一点,只是把高16异或下来(异或的操作是相同为0 不同为1)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h =key.hashCode()) ^ (h >>> 16);
}
为什么容量要是2的次方
https://blog.csdn.net/apeopl/article/details/88935422
treeMap
还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。
使用TreeMap时,放入的Key必须实现Comparable接口。String、Integer这些类已经实现了Comparable接口,因此可以直接作为Key使用。作为Value的对象则没有任何要求。
优先队列
PriorityQueue和Queue的区别在于,它的出队顺序与元素的优先级有关,对PriorityQueue调用remove()或poll()方法,返回的总是优先级最高的元素。