今天来聊一聊面试八股文:布隆过滤器。
说道布隆过滤器,就免不了说到缓存穿透。
缓存穿透
在高并发下,查询一个并不存在的值时,缓存不会被命中,导致大量请求直接落到数据库。
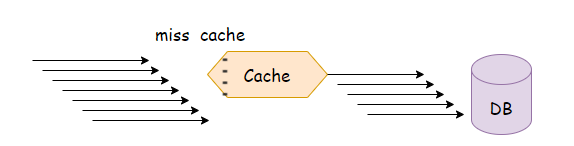
数据库的响应能力肯定没有缓存大,出线这样的情况,一般是黑客攻击,拖慢了系统的响应速度。
头脑风暴
朴素的分析思路: 在缓存前加一道屏障:放置存在(可能存在)的查询键,屏蔽不可能存在的查询键,
业内一般使用布隆过滤器来做这个屏障。
布隆过滤器的实现过程
布隆过滤器内部维护了一个全为0的bit数组,几个hash函数(f1,f2)
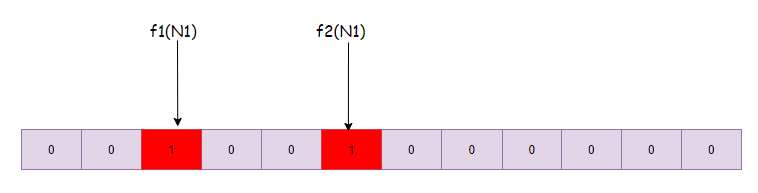
假设有输入集合{N1,N2},哈希函数f1、f2
- 经过计算 f1(N1)=2, f2(N1)=5, 则将数组下表为2,5的位置标记为1:
- 同理计算f2(N1)=3, f2(N2)=4,则将数组下表为3,4的位置标记为1:
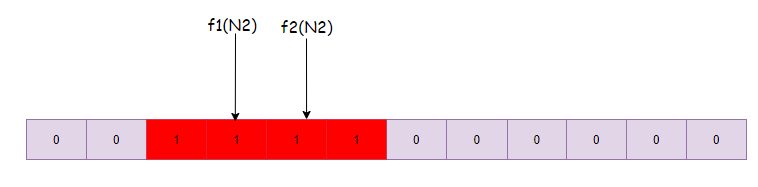
- 有第三个数N3,我们判断N3在不在集合{N1,N2}中, 就进行f1(N3)、f2(N3)的计算
- 如果f1(N3),f2(N3)计算的值均落在上图红色区域, 则说明N3可能属于集合{N1,N2}中的一员
- 如果f1(N3),f2(N3)计算的值有一个落在红色区域的外面,则说明N3一定不属于集合{N1,N2}
布隆过滤器的设计原理
(这里是重点,再看不懂,私聊我)
数据库所有的键,经过一次哈希运算,收敛到(A,B)区间,
某个待查询的键K,如果经过同样的哈希运算,落在(A,B)区间,因为存在哈希碰撞,所以我们说K有可能属于数据库中所有的键中的一员;
但是如果该K经过哈希运算,没有落在收敛区间,则证明K一定不属于原数据库键。
那为什么要使用多个哈希函数?
因为经过一次哈希函数落在收敛区间,只能说该K有可能属于原数据库键,但是如果经过多个哈希函数,还是落到收敛区间,概率叠加,无形中增大了该K属于原数据库键的概率。
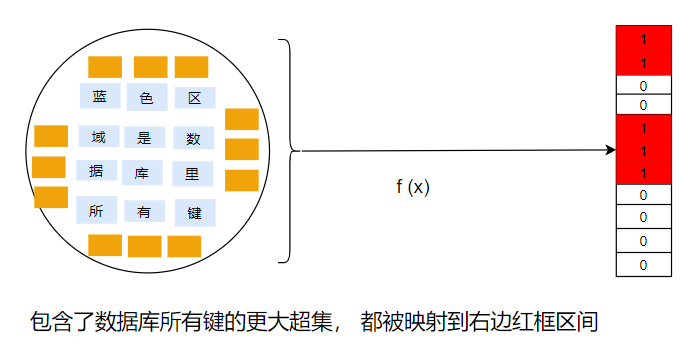
总体上看: 布隆过滤器是利用了哈希算法的单向收敛性+概率论。
时间复杂度: 要判断N是否属于原查询键,只需要经过几次哈希运算,所以布隆过滤器判断的过程是很快的,
布隆过滤器的应用
很明显,布隆过滤器存在误报, 经过上面的分析:误报率跟哈希碰撞和有几个哈希函数有关,
成熟的布隆过滤器,这些你都不需要考虑,只需要指定 ① 哈希结果的存储区 ②容量 ③误报率
| package | nuget |
|---|---|
| BloomFilter.NetCore | 以内存存储哈希结果 |
| BloomFilter.Redis.NetCore | 以redis存储哈希结果 |
| BloomFilter.EasyCaching.NetCore |
using BloomFilter;
using System;
using System.Collections.Generic;
namespace BoomFilter
{
class Program
{
static readonly IBloomFilter bf = FilterBuilder.Build(10000000, 0.03);
static void Main(string[] args)
{
int size = 10000000;
for (int i = 0; i < size; i++)
{
bf.Add(i);
}
var list = new List<int>();
// 故意取100个不在布隆过滤器中的值,看下有多少值误报
for(int i= size+1;i<size+100;i++)
{
if (bf.Contains(i))
{
list.Add(i);
}
}
Console.WriteLine($"误报的个数为:{list.Count}");
}
}
}

总结
布隆过滤器是 哈希函数单向收敛和 概率论的完美结合,
从上面的分析看,解决缓存穿透,我们在Cache前面预热一个布隆过滤器,就可以阻止绝大部分非法的查询键。
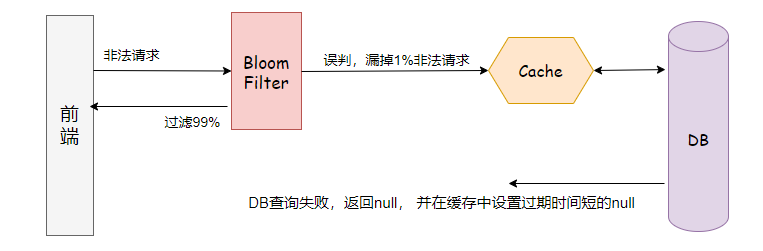
注意,布隆过滤器对删除不友好,所以如果数据库键有大量变更,需要重建布隆过滤器。