提起微服务架构,不可避免的两个话题就是服务治理和分布式事务。数据库和业务模块的垂直拆分为我们带来了系统性能、稳定性和开发效率的提升的同时也引入了一些更复杂的问题,例如在数据一致性问题上,我们不再能够依赖数据库的本地事务,对于一系列的跨库写入操作,如何保证其原子性,是微服务架构下不得不面对的问题。
1 分布式事务解决方案
针对分布式系统的特点,基于不同的一致性需求产生了不同的分布式事务解决方案,追求强一致的两阶段提交、追求最终一致性的柔性事务和事务消息等等。各种方案没有绝对的好坏,抛开具体场景我们无法评价,更无法能做出合理选择。在选择分布式事务方案时,需要我们充分了解各种解决方案的原理和设计初衷,再结合实际的业务场景,从而做出科学合理的选择。
2 强一致解决方案
2.1 两阶段提交
两阶段提交算法中有两种角色:事务协调者和事务参与者,一个事务一般会涉及多个事务参与者,具体的两阶段过程如下图所示:
第一阶段:写库操作完成后协调者向所有参与者发送Prepare消息,询问各参与者的本地事务是否可以提交,参与者根据自身情况向协调者返回可以或不可以;
第二阶段:协调者收到所有参与者的反馈后,如果全部返回的是可以提交则向所有参与者发送提交事务命令。只要有一个参与者返回的是不能提交,则向所有参与者发送回滚命令。如下图所示:
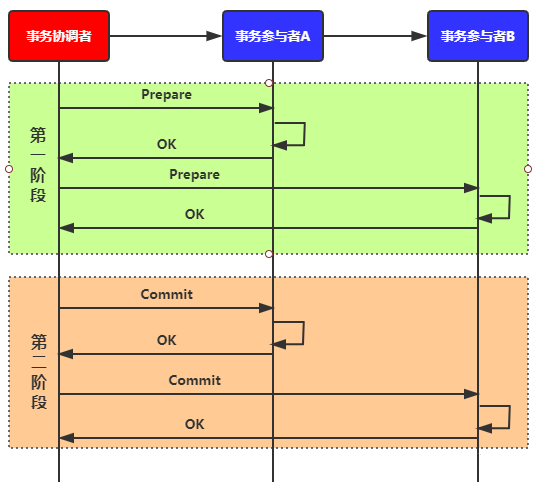
图1 两阶段提交
在上述的两阶段模型中,事务提交过程中有可能出现协调者或个别参与者宕机的情况,但多数情况下参与事务的节点可以通过询问其他节点得知事务状态,做出正确的操作。但在极端情况下事务有可能处于未知状态。我们分析下下面这个场景:当协调者发送提交指令后宕机,而唯一收到提交指令的参与者完成提交后也宕机了,此时没有节点知道事务应该提交还是回滚,事务处于未知状态,所以在这种极端情况下可能造成数据的不一致。针对两阶段的缺陷,又提出了三阶段提交协议。
2.2 三阶段提交
三阶段提交是将第二阶段拆分成预提交和确认提交两个阶段。这样在事务提交过程中,无论哪个节点宕机,只要有一个存活节点处于预提交或是提交状态我们都可以确定事务是可以提交的(第一阶段已经确认事务可以提交),反之如果没有处于这两种状态的节点,则回滚事务。
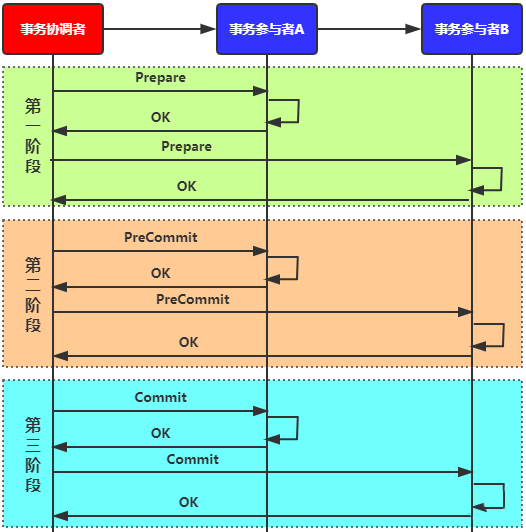
图2 三阶段提交
从上面的分析可以看到,无论是两阶段还是三阶段最后的“提交”都是一个耗时极短的操作,即使在分布式系统中失败的概率也是非常小的,所以我们可以认为两阶段提交基本能够保证分布式事务原子性。
3 落地方案
上面介绍的只是理论基础,XA规范就是基于两阶段提交的理论模型提出的分布式事务规范,规范中的资源管理器相当于事务参与者;事务管理器相当于事务协调者,目前很多主流的关系数据库都实现了XA接口。
落地到实际应用中我们会发现两阶段提交存在的一些问题:
1. 数据库产品要保证数据完成性,写入需要加锁,所以在整个分布式事务协调过程中可能造成数据库资源锁定时间过长,不适合并发高以及子事务生命周期较长的业务场景;
2. XA规范要求事务管理器本地记录事务执行状态,所以事务管理器作为有状态服务不支持事务异地恢复;
XA能够最大程度保证数据的一致性,但在高并发场景下性能衰减非常严重,所以在数据一致性需求上如果不是“强一致”,不建议使用。
3.1 最终一致性解决方案
在我们大多数的业务场景中,追求的都是数据的最终一致性,业界也提出了很多柔性事务的解决方案,可以很大程度上保证数据的一致性,我们可以根据实际场景来权衡使用。具体的解决方案有很多,总结其设计思路可以分为下面3种模型:
3.1.1 TCC(Try-Confirm-Cancel)
TCC将事务分为Try,Confirm,Cancel三个阶段。
1. Try阶段:尝试执行业务,预留资源;
2. Confirm阶段:确认执行业务,使用Try阶段资源;
3. Cancel阶段:取消执行业务,释放Try阶段预留的资源;
我们用一个转账汇款的业务场景,说明下TCC的具体过程。例如:张三给李四转账100元,一次转账业务由两个本地事务组成:1、张三账户扣减100元;2、李四账户增加100元。
事务成功处理流程如图3:

图3 Try-Confirm事务成功处理流程
事务失败处理流程如图4:
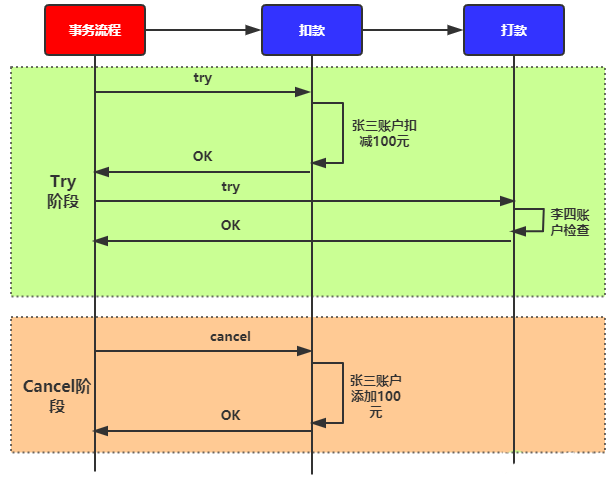
图4 Try-Cancel事务成功处理流程
Try阶段:
1、检查张三账户,满足要求账户扣减100元,记录扣减事件(预留资源);
2、检查李四账户有效性;
Confirm:
如果Try成功,李四账户增加100元,事务完成;
Cancel:
如果Try失败,张三账户增加100元,删除扣减事件记录(释放预留资源),事务取消。
从性能角度分析,TCC过程没有对资源加锁,对系统并发性能几乎没有影响,只是会有些额外辅助操作。需要注意,在这个模型中要保证数据一致性有两个技术难点需要解决:
1. 需要有类似事务管理器的角色保证TCC过程的完整性;
2. Confirm和Cancel方法需要保证幂等(由于不可避免的重试操作必须要保证幂等);
TCC对业务侵入非常大,对RD同学十分不友好,业务改造成本相当高。
3.1.2 SAGA模型
SAGA模型把一个分布式事务拆分为多个本地事务,每个本地事务都有相应的执行模块和补偿模块,当事务中任意一个本地事务出错时,可以通过调用对应的补偿方法恢复之前的事务,从而达到数据的最终的一致性。SAGA的事务管理器负责在事务失败时执行补偿逻辑,可以通过调用执行模块的逆向操作(例如执行子事务时同时生成逆向SQL)或调用业务开发人员提供的补偿方法(需要保证补偿的幂等性)来实现。
可以看到,SAGA虽然对业务造成一定的侵入,但当相对TCC已经有好很多了,而且,事务管理器理论上可以做到向后补偿(撤销所有已完成操作,恢复到事务开始状态)或向前补偿(继续完成未完成事务,使业务请求得到成功处理,更符合业务预期)。
3.1.3 MQ事务消息
MQ事务消息对分布式事务模型进行了简化,重点不再是保证所有子事务的原子性,而是保证本地事务和发送MQ消息的原子性,我们可以利用这一特点,将分布式事务转化成本地事务和若干发送MQ消息的操作,然后要求消费方确保消费成功。利用MQ事务消息,在系统中去掉了TCC和SAGA方案中的事务管理器角色,简化了分布式事务模型,同时这也是对业务侵入最低最友好的方案(不用提供补偿接口)。
当然这里也有两个基本前提:
1. MQ系统保证消息能不丢失;
2. 消费方确保消费幂等(保证不丢失,就很难避免重复消费)。
需要注意的是,MQ事务消息简化了事务模型、降低了业务侵入,所以对数据一致性的保证保障也就相对比较低了。
4. 总结
柔性事务解决方案中,虽然SAGA和TCC看上去可以保证数据的最终一致性,但分布式系统的成产环境复杂多变,某些情况是可以导致柔性事务机制失效的,所以无论使用那种方案,都需要最终的兜底策略,人工校验,修复数据。
我们综合对比下几种分布式事务解决方案:
一致性保证:XA > TCC = SAGA > 事务消息
业务友好性:XA > 事务消息 > SAGA > TCC
性 能 损 耗:XA > TCC > SAGA = 事务消息
最后,在设计系统时我们一定要结合业务自身的一致性需求,选择恰当的方案。可以看到对数据一致性保障越高的方案其开发成本、维护难度和系统性能损耗就越大,一定不要一味的追求高大上的方案,对系统过度设计。
更多免费技术资料及视频
