https://blog.csdn.net/u014038273/article/details/78773515
https://blog.csdn.net/qq_35414569/article/details/80770121
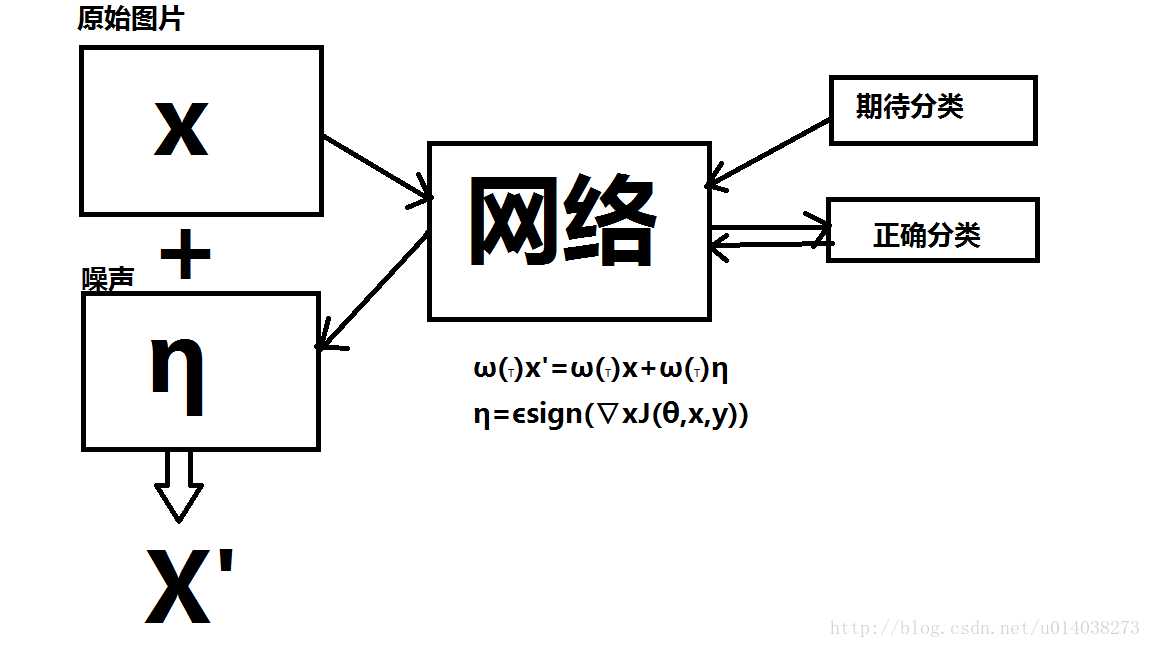
对抗样本
通过对原始图片添加噪声来使得网络对生成的图片X’进行误分类,需要注意的是,生成图片X’和原始图片X很像,人的肉眼无法进行辨别,生成的图片X’即为对抗样本。
1)定向对抗样本
注意是对X’(n-1)求偏导,并非X,而且注意loss函数J中的参数是X’和Y’,而不是X和Y。这个是定向对抗样本生成的过程,f(x)是针对噪声的裁剪过程。
X’(n)=X+ε*f(sign(∇X’J(θ,X’(n-1),Y’)))
2)不定向对抗样本
针对不定向对抗样本的生成过程,则直接对x和y求偏导数即可。
X’=X+ε*sign(∇X’J(θ,X,Y))
FGSM
产生噪声η有很多种的方法,这里我们采用的是Fast Gradient Sign Method,即通过在梯度方向上进行添加增量来诱导网络对生成的图片X’进行误分类,我们可以通过指定我们期待的分类使得网络针对任何输入图片均产生指定分类的对抗样本,同时也可以不指定期待的分类,只需要使得生成的图片被网络识别为与正确分类不同的分类即可。
针对指定预期分类的对抗样本生成来说,我们需要更改它的loss损失函数,交叉熵损失函数变为:
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y_logits, labels=[pl_cls_target]),通过计算网络对于参数的梯度进行噪声的生成即对抗样本的生成。
在2014年提出了神经网络可以很容易被轻微的扰动的样本所欺骗之后,又对产生对抗样本的原因进行了分析,Goodfellow等人认为高维空间下的线性行为足以产生对抗样本。
对抗样本的线性解释
常见的数据图像大部分表示成1-255,8bit/像素点的形式,所以能够表示样本的精度十分有限,由于这种有限的表达能力,可能在原始样本上加小小的扰动就被误分类。现在我们有:
原始图像:x
扰动:η
对抗样本: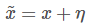
当存在一个小到可忽略的ε满足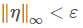 ,我们期望分类器对这两个样本的分类结果一致,然而……
,我们期望分类器对这两个样本的分类结果一致,然而……
现在考虑加入权值向量ω信息,则: 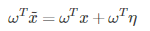
对抗扰动通过ωTη影响激活函数从而影响分类结果。如果ω有n个维度,权向量的一个元素的平均大小是m,那么激活函数就会增加εmn。虽然∥η∥∞不会随着维度增加而增加,但是η会随n线性增长,然后就有高维问题了。
非线性模型的线性扰动
我们假设神经网络都太线性了以至于不能抵抗对抗样本。常见的LSTM、ReLU和maxout网络都趋向于线性表现,而类似sigmod这种非线性性模型也把大量的时间花在非饱和和线性系统中。
我们从公式开始理解(fast gradient sign method): 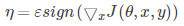
模型参数:θ
模型输入,即图像:x
结果标签:y
损失函数:J(θ,x,y)
符号函数:sign()
我们可以线性化代价函数的当前值θ,获得最优max-norm η
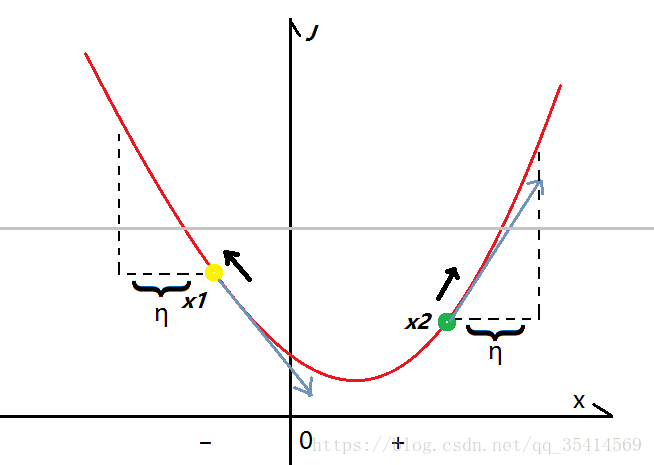
算法的主要思想:让我们的变化量与梯度的变化方向完全一致,那么我们的误差函数就会增大,那么将会对分类结果产生最大化的变化。
sign函数保证了变化方法同梯度方向一致。对损失函数求偏导,即得到权值向量ω有关的函数。
首先明确,横坐标表示单维x输入值,纵坐标表示损失值,函数图像是损失函数J,损失值越大表示越大概率分类错误,假设灰的线上方为分类错误,下方为分类正确。
以样本点x1为例。根据公式,此时的偏导函数为负,则黑色箭头方向为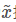 扰动方向,同理x2样本在取值为正时,也沿着黑色箭头方向变化,只要我们的 ε取值合适,就能生成对抗样本,使得分类错误。
扰动方向,同理x2样本在取值为正时,也沿着黑色箭头方向变化,只要我们的 ε取值合适,就能生成对抗样本,使得分类错误。
线性模型与权值衰减的对抗性训练
如果我们可以考虑的最简单的模型是逻辑回归。在这种情况下,FGSM是准确的。

代码
代码实现主要参考链接:Python3环境下cleverhans对抗样本防护编译与测试(含FGSM攻击与ADV防护),但是原博客没有直接给出可运行的代码,所以自己基于基础代码改了一下,在博客最后附下载链接。
工程如下:
fgsm.py 可直接运行主程序,实现FGSM算法生成对抗样本,也能实现防御
eval_on_adversarisl.py 实现防御训练模型
checkpoint 两个防御模型
input 原始输入图像
output 对抗样本
通过修改checkpoint_path来实现调用不同模型:

inception_v3.ckpt 是原始经典模型
adv_inception_v3.ckpt 是Step L.L.防御训练后的模型
ens4_adv_inception_v3.ckpt 是集成四个模型Step L.L.防御训练后的模型
结果展示函数:
classify() 展示预测结果最高的类别
show_classify() 展示图像以及预测结果最高的前十个结果,如下图:
代码主要调用cleverhans集成库,里头还有许多现成的攻击算法可以调用。