希望在毫不知情(很少的人类介入)的情况下实现。即端对端的实现。

一、Intro


工具推荐:

二、Auto-Encoder
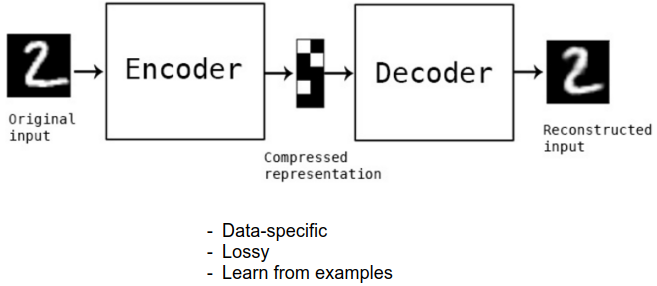
使用自编码器的情况:1)拿到的原始数据缺少标签 (数据降噪) 2)数据太大了,需要进行降维,使得最后数据集大小可接受(例如可以讲原始的8*8图片压缩成2*1的)
将原始图片“数字2”压缩(encoder一个从大到小的NN)到一个中间量(compressed representation),然后通过一个完全反过来的(Decoder一个从小到大的NN)恢复出原始图片。
自编码器实质:自己来学习自己。在中间加了两个对立漏斗形的NN。目的在于处理前后输入输出图片之间的差异尽量小。
当输出可以很好恢复出输入的时候,可以认为中间量(compressed representation)是足够好,足够独特的。

Auto-Encoder可以视为是DL的开山鼻祖,因为它最早且直观简单的。真实熟练地实现了DL的精确要素,不用人为处理来提取。
比较文本编解码前后相似度的方法:(1)列文斯坦距离。(原句子到输出语句需要进行多少步转换)
(2)或者将原文本表示成矩阵向量,然后计算两词向量之间的夹角cosine值,来表示这俩向量之间的距离。
对于init DNN weights:
将encoder取出来作为NN的init位,建立一个NN的前面几位可以不用学习了,因为通过encoder学习得到的可以被视为是已经提取出来的特征表达形式。从而可以让NN变得更加快速。
而这个思路被证实还不如做随机初始化(random initial),因为随机初始化的时候还不容易陷入局部最优解。
batch normalization:分成一个个小batch,并将每个小batch(融合到一堆进行训练)进行normalization(归一化),使得最后计算结果的学习曲线能够更加平滑。
Residual Learning(残差学习):每次学习的时候都随机跳过几个DL的块,这样既能加快整体训练速率,又能保证整个DL的严谨性。

因此每当你处在一个三维的环境当中的时候,你是没有办法跳出这个维度本身,即你无法很好的解释这个三维世界本身。
也就是说,你至少要比你所在维度高一维才能很好地来解释它。因此很可能你得到的是局部最优解,因为你没办法判断是不是全局最优

python2是基于ASCII的,python3是基于Unicode(现阶段较完美的替代ASCII,囊括了全世界的所有语言)。
这里采用ASCII(共256)来实现对英文句子的编码,对于一个神经网络模型而言,输入的X——Y的过程中要求X应该应该是等长的。
因此在__init__函数的参数列表中:sen_len均固定长度为512,经过encoder得到的中间量的长度encoding_dim=32,训练次数epoch=50次,从训练集中取val_ratio=0.3来保证在学习的时候进行观测有无过拟合现象的产生。
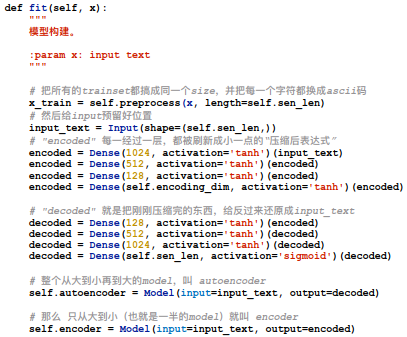
当中的preprocess需要自行补充:将text扩展/截断成512的长度,sen_len并且每个字符用ASCII表示。得到的结果作为x_train。
因此,所有input都变为unified的表达形式。并且它们都有各自一一对应的特征表达。
input层:512长度
encoder:1024——512——128——32(encoding_dim)
decoder:128——512——1024——512(sen_len)

预留好input size的目的是为了保证输入的shape和之前的是一样的
把所有的layer倒推一下(即encoder的倒数n层作为decoder的正数n层)
进行compile一下:adam优化器,损失函数,来进行自我学习,直到它们的差异达到最小。
fit:将x_train作为输入x放入,将x_train作为y也输入。shuffle=True的意思是每次学习完后将学到的数据进行打乱。
KNN:将x_train这个文本利用predict变为32位代码(压缩码),从而编译时间就会变得很短。
然后再用一个kmean最近模型将相近的划分到一起,远的分为另一类。从而实现粗略的分类(即聚类)。

此时模型已经训练好了,现在进行测试预测:
predict函数:先将x变为等长的512位的ASCII码,并处理成32位压缩码x_test,再用KNN分类[0,1]
KNN是一个无监督的分类器。(kmean模型聚类算法)
Auto-Encoder整个过程没有用到任何的label,用的都是数据x本身,都没有用到y,这是一个很完善的非监督算法。缺点在于算法的精确度不是很高。
三、CNN4Text

CNN相当于将输入的同一张图片在不同的滤镜下得到不同的显示形式,暗含图片的一些鲜为人知的特征。
这些特征可以通过计算机进行学习后,作为原图片的特征表达向量。利用这个向量和label标签y进行学习。
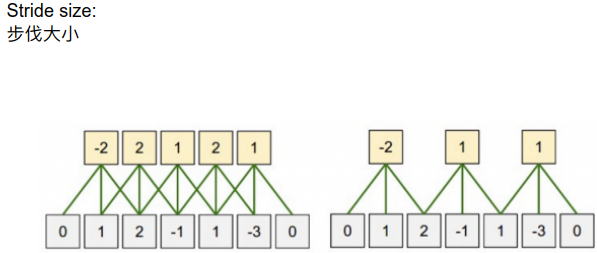
“ 滤镜”对应图中的黄色部分。图片为绿色的5*5图片。“滤镜”的获取也不是随机的,是CNN学习的一部分。

右图中:中间点和上下左右的像素如果相近的话,加起来就会抵消变0,呈现黑色。但是如果周围和中心点的颜色相差很大的话,

可以利用word2vec将一句话转换为数字向量的形式。从而将每个单词都写成一个个横向的向量,如下图:
成功将一句话扩展成为了一张图片的表达形式(二维的像素值),从而此形式的数据就能直接放入CNN当中:
先用一个滤镜扫过得到一个个特征点,
然后利用max-pooling(因为滤镜扫过了所有的像素点产生了所有的特征值,而这些特征值不一定全是我们需要的)选择特征向量中的最大值
(采用maxpool的原因是:拿到一张图片最耀眼是最值得关注的,因此只需要将这个最被注意的点提取出来代表这个区域。)
采用max-pool实质就是为了降维降低计算复杂度。
池化层之后所有特征都会变成一维的横向排布。然后输出对应到0,1的分布。
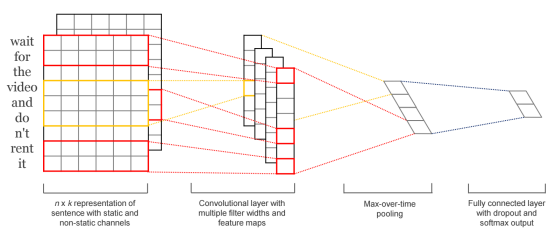

我们不一定要将句子处理成图片的形式,也可以把它处理成一维向量形式。
利用ASCII预处理的过程,将输入text统一变为512位(用256中ASCII表示的)数字代码sentence。
然后通过一维的filter照射每一个区域,得到一个个feature map
经过max-pooling取出最大值,
然后通过分类器(MLP:SVM,LR)得出分类的y
这个方式会比方法一转换过程要简单一点,不用转换为图片形式。
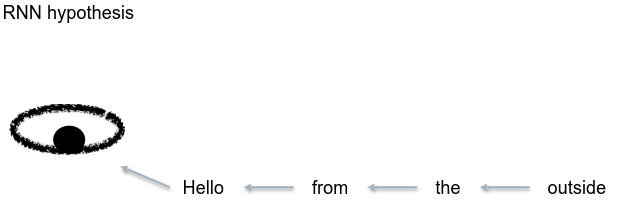
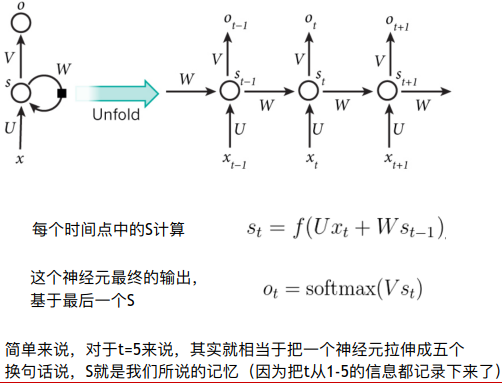
RNN:对于一个有记忆的时间序列模型而言,人眼是从头开始一个个按顺序的看。
RNN可以很好保存信息的前后关系,时间序列。

CNN:人眼看语句的时候用的是图像思维,并非真的一个个字看过去。是将看到的先转换为一张图片,然后进行大脑处理,再进行语义提取。
相当于“看到”和“到看”经过池化层之后只会得到最具特征的“看”,同样“话句”也会被池化层处理为“话”。
CNN重点在于处理传入语句的含义,不纠结与句子的前后语序。
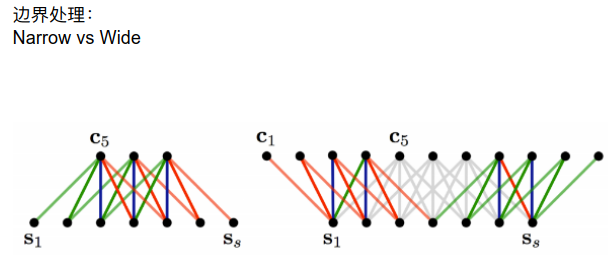
wide中采用padding来保证图片中每一点都能被扫到,但也可能带来一些意想不到的噪声。
narrow中都是自己的点,不会越过原图本身。