Spark核心原理
spark 运行架构
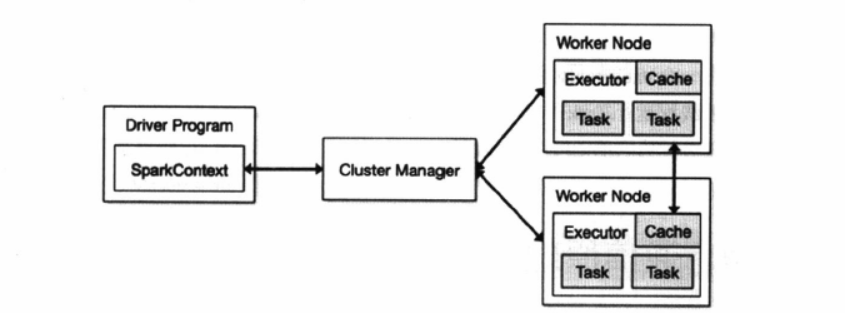
Application (应用程序) : 用户编写的Spark应用程序,包含 DriverProgram (驱动程序)和 在分布由集群
中节点上运行的Executor代码,在执 行过程由一个或者多个作业组成;
Driver (驱动程序):为应用程序Application的main函数创建SparkContext,
为Spark运用程序创建运行环境;
由SparkContext 负责与ClusterManager通信进行资源的分配,任务分配,监控等;
当Executor 运行结束, 由Driver 关闭SparkContext ;
Cluster Manager(集群资源管理器):在集群上获取资源的外部管理器, 以下几种 :
Standalone: Spark原生资源管理,由Master 负责资源管理
Hadoop Yarn:由YARN 的Resource Manager负责资源管理;
Mesos : 由Mesos 中的Mesos Master 负责资源管理;
Master(总控进程) : Spark Standalone 运行模式下的主节点;
管理和分配资源来运行Spark Application;
Worker(工作节点):集群中任何运行Application代码的节点, 类似于YARN中的NodeManager, 在standLone中通过
slave 文件配置的Worker节点, 在Spark On Yarn 中就是Node Manager;
Executor(执行进程) : Application运行在Worker 上的进程;
1、消息通信原理
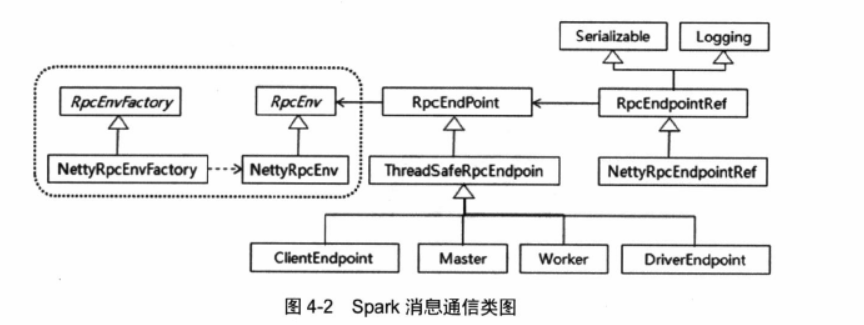
1.1、 Spark 消息通信架构
1.2 Spark 启动消息通信
Spark 启动过程中,主要运行Master 和 Worker 的通信;
Worker 向Master 发送注册消息, 如果Master在standby 则忽略该申请;该Worker已经注册,则返回注册失败;
如果Worker注册Master成功, Master则返回消息,并监听Worker的心跳消息;
1.3 Spark运行时消息通信

用户提交应用程序时,应用程序的SparkContext 会向Master 发送应用注册消息, 并由Master给该应用分配
Execuator;
Executor启动后,Executor向SparkContext 发送注册成功消息;
当SparkContext 的RDD触发行动操作后,创建RDD的DAG, 通过DAG Scheduler 进行划分 stage并将 stage
转化为 TaskSet;
再由 TaskScheduler 向注册的Executor发送执行消息, Execuator接收到任务消息后启动运行;
当所有任务运行时, 由Driver处理结果并回收资源
2、作业执行原理
Spark 作业和任务调度系统中的术语:
Job(作业):RDD中由行动操作生成的一个或多个调度阶段;
Stage (调度阶段):每个作业因为RDD之间的依赖挂你拆分为多组任务集合,称为调度阶段,也叫任务集。
调度阶段的划分由DAGScheduler来划分,调度阶段由Sheffle Map Stage 和Result Stage两种
Task ( 任务) : 分发到Excutor上的任务;
DAG Scheduler : 面向调度阶段的任务调度器;
接收Spark应用提交的作业,根据RDD的依赖关系划分调度阶段,'
并提交调度阶段给Task Scheduler
Task Scheduler : 面向任务的调度器, 接收 DAG Scheduler 提交的调度阶段, 然后把任务发送Work节点运行,
由Worker 节点的Excutor 运行该任务;
2、概述

1)spark应用程序进行各种转换操作,并通过转化操作触发作业运行;
提交作业后, 根据RDD的依赖关系构建DAG图,并将DAG图给DAGScheduler解析;
2)DAGScheduler 把DAG 拆分为互相依赖的调度阶段,调度阶段以宽依赖作为划分依据,
调度阶段包含一个或多个任务,形成任务集,交给TaskScheduler调度运行;
DAG 还要记录哪些RDD 存入磁盘等动作,并需求任务最优调度;
3)TaskScheduler 将任务集一个个分发到Worker节点的Executor运行,失败则需要重新运行;
4)Worker中的Executor收到TaskScheduler的任务后,以多线程的方式运行,
一个线程运行一个任务;
完成任务后返回个TaskScheduler;
==================================================================
资料来源: 1.《Spark权威指南》
2. 《图解Spark核心技术和实例实战》