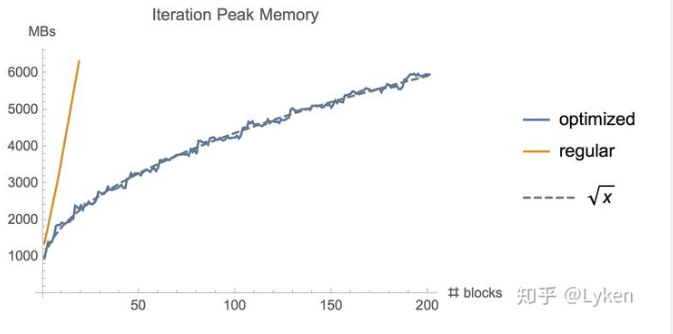
陈天奇的Training Deep Nets with Sublinear Memory Cost告诉我们,训练deep nets的时候,memory的最大的开销来自于储存用于backward的activation。这个很好理解,前向的时候,每一层的activation都要保存下来,用于计算backward。
那么这个时候,一个简单的解决方案就是,我们隔着sqrt(n)层存一次activation,然后在需要的时候,我们再进行一次计算。这样的话,memory就大致省下来sqrt(n)倍。并且显存使用越多,省下来的越多。
reference
- https://arxiv.org/abs/1604.06174 Training Deep Nets with Sublinear Memory Cost.
- https://www.zhihu.com/question/274635237/answer/755102181