[从今天开始修炼数据结构]线性表及其实现以及实现有Itertor的ArrayList和LinkedList
[从今天开始修炼数据结构]栈、斐波那契数列、逆波兰四则运算的实现
[从今天开始修炼数据结构]队列、循环队列、PriorityQueue的原理及实现
一、什么是串?
串是羊肉牛肉等用铁签穿过的食物,常碳烤、油炸。不对,错了…… 串String是由零个或多个字符组成的有限序列,又名字符串。
二、串的比较
在计算机中串的大小取决于它们挨个字母的字典顺序,比如“silly”和“stupid”,首字母s相同,比较第二个字母,“i” < “t” 所以“silly“<“stupid”。如果像”stu“和”stud“比较,那么因为多了一个字母”d“,则”stud“更大。
事实上,串的比较是通过组成串的字符之间的编码来进行的,而字符的编码指的是字符在对应字符集中的序号。
计算机中常用字符是使用标准的ASCII编码,由七位二进制数表示一个字符,总共128个。后来多了一些特殊字符,发现128个不够用,就扩展为8位二进制数,表示256个字符。然而世界上那么多种语言和特殊符号,256个字符显然是不够的,因此后来就有了Unicode编码,由16为二进制数表示一个字符,这样就可以表示大约6.5万个字符了,当然,为了兼容,Unicode的前256个字符和ASCII的是完全相同的。
对于中文,还有GBK,UTF-8等。
三、串的抽象数据类型
串的存储结构与线性表相同,分为两种。
1,顺序存储结构
用一组地址连续的存储单元来存储串中的字符序列(Java中的String底层就是一个char[]),C语言中用malloc函数从堆中动态分配空间~
2,链式存储结构
链是存储与线性表的链式存储类似,不过每个元素数据只是一个字符,一个节点对应一个字符的话就会浪费很大的空间。因此一个节点可以存放多个字符,若最后一个结点没有占满,可以用”#“或其他非串值字符补全。
这里一个节点存多少个字符才合适显得十分重要,这会直接影响着串处理的效率,需要根据实际情况做出选择。但总体来说除了在连接串与串的操作时有一定方便之外,总的来说不灵活,性能也不如顺序存储结构好。
四、朴素的模式匹配算法
朴素模式匹配就是对主串的每一个字符作为子串开头,与要匹配的字符串进行匹配。对主串做大循环,每个字符开头做小循环,直到匹配成功或全部遍历完成为止。
简单实现如下:
/* 外层控制主串,内层控制匹配串 如果内层匹配到最后一个位置了还没有break,则说明匹配成功 */ public class IndexDemo { public static int index(String main, String arg){ int index = -1; for (int i = 0; i < (main.length() - arg.length() + 1); i++){ for (int j = 0; j < arg.length(); j++){ if (main.charAt(i + j) != arg.charAt(j)){ break; }else if (j == arg.length()-1){ index = i; } } } if (index == -1){ return -1; } return index; } }
上面这种写法循环嵌套复杂度有点太高了,下面换成一个循环+角标回溯的方法再写一个
public class IndexDemo { public static int index(String main, String arg, int pos){ int i = pos; //控制main的角标 int j = 0; //控制arg的角标 while(i < main.length() && j < arg.length()){ if (main.charAt(i) == arg.charAt(j)){ i++; j++; }else{ i = i - j + 1; j = 0; } } if (j >= arg.length()){ return i - j; }else { return -1; } } }
这种算法简单好理解,但是时间复杂度很高,如果说被匹配的字串恰好在最后,而且前面的子串又跟匹配串的前几位都很像,那么这个串的时间复杂度将达到O(n2)。所以我们下面来一起学习高级的模式匹配方法 —— KMP方法
五、KMP模式匹配算法
KMP这个名字并不是什么专业术语,而是发明这个算法的三个前辈名字首字母的组合。
1,讲讲原理
我们在匹配过程中,假如遇到下面这种情况。我们把上面主串命名为S,下面的串命名为T。

如果我们现在用的是朴素匹配算法,那么在i = j = 5时遇到了不同的字符之后,下一轮会从i = 1, j = 0开始匹配。这里我们可以知道,T的首字符与后面的字符都不相同,而之前又匹配过T的前五个字符与S的前五个字符相同,所以可得T的首字符与S的前五个字符都不相同。那么经过了第一次比较之后,我们是不是就不需要判断T的首字符与S的第2 - 5个字符是否相同了呢? 所以我们只需要比较 ①当i = 0,j = 0时, 下一次就要比较 ⑥当i = 6,j = 0时
上面这是首字符与后面字符都不相同的情况,我们再来看首字符与后面的字符有重复的情况。

S和T的前五个字符完全相同,第六个字符不同,如上图。根据刚才的经验,T的首字符与角标1,2字符都不相同,不用做判断。而T的0,1位与T的3,4位相同。
又由第一次比较,知道T的3,4位与S的3,4位也相同,所以T的0,1与S的3,4必定相同,因而下一次比较也不需要比较T的0,1和S的3,4。所以第二次比较我们可以直接从i = 5,j = 2开始比较。如下图(打叉表示无需比较)
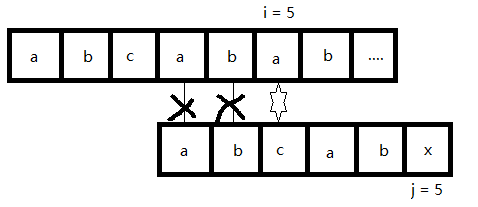
对比这两个例子我们会发现,在①时,我们的 i 值也就是主串的当前位置下标是5,在朴素的模式匹配算法中,主串的i值是不断回溯来完成的,即i = 0比完之后继续比较i = 1,2,3,4,才回到5,这种回溯其实是不必要的,我们的KMP算法就是为了让这没必要的回溯不再发生而产生的。
既然 i 不回溯,那么要考虑的变化就是 j 了。通过观察我们可以发现,我们屡屡提到T中首字符与后面字符的比较,如果有相等字符,j 值的变化就会不相同。也就是说 j 值的变化关键取决于T串的结构中是否有重复。
我们把T串各个位置的 j 值的变化定义为一个数组next,那么next的长度就是T串的长度。于是我们可以得到下面的函数定义:
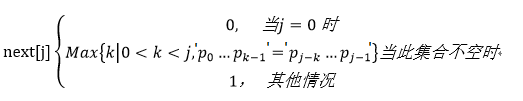
通过上面的函数我们来推导一下T的next数组值。
1,T = “abcdex”
| j | 0 | 1 | 2 | 3 | 4 | 5 |
| 模式串T | a | b | c | d | e | x |
| next[j] | -1 | 0 | 0 | 0 | 0 | 0 |
2,T="abcabx"
| j | 0 | 1 | 2 | 3 | 4 | 5 |
| 模式串T | a | b | c | a | b | x |
| next[j] | -1 | 0 | 0 | 0 | 1 | 2 |
1)当j=0时,next[0] = -1
2)当j=1,2,3时,next[j] = 0
3)当j=4时,此时j由0到j-1的串是abca,前缀a和后缀a相同,因此k=1(算法是由 )因此next[4] = 1;
)因此next[4] = 1;
4)当j=5时,此时j由0到j-1的串时abcab,前缀ab和后缀ab相同,因此可得k=2,所以next[5] = 2
3,T=“aaaaaaaaab”
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 模式串T | a | a | a | a | a | a | a | a | b |
| next[j] | -1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
1)当j=0时,next[0] = -1
2)当j=1时,next[1]=0
3)当j=2时,j由0到j-1的串是aa,前缀a与后缀a同。next[2]=1;
4)当j=3时,j由0到j-1的串是aaa,前缀aa与后缀aa同,可推k=2,所以next[3] = 2
5)……
6)当j=8时,j由0到j-1的串是“aaaaaaaa”,前缀aaaaaaa和后缀aaaaaaa同,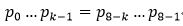 ,k=7所以next[8] = 7
,k=7所以next[8] = 7
总结:next[]数组的计算方法就是递推来的.是根据以下三条性质写出的代码
性质I:
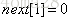
性质II:若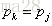

性质III:若
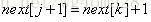
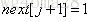
2,说完原理,下面我们来实现一下KMP算法
看到这你也许一头雾水,我也发现我貌似水平有限,不一定能让大家明白我所讲的KMP算法,所以贴上大佬博客
https://www.cnblogs.com/SYCstudio/p/7194315.html
https://blog.csdn.net/wg4oma28/article/details/80115137 大佬1讲匹配过程比较清楚,大佬2讲求解next数组的代码讲解的比较清楚
下面是KMP的实现代码
public class KMPDemo { public static int index_KMP(String main, String arg) { int i = 0; int j = 0; int[] next = getNext(arg); while (i < main.length() && j < arg.length()) { if (j == -1 || main.charAt(i) == arg.charAt(j)) { i++; j++; } else { j = next[j]; } } if (j >= arg.length()) { return i - j; } else { return -1; } } private static int[] getNext(String arg) { int[] next = new int[arg.length() + 1]; next[0] = -1; int i = 0;//模式串中当前匹配到的位置的下标值 int j = -1;//子串匹配前缀最后一个位置的下标,-1表示没有子串,即已经回退到了0位置 while (i < arg.length()) { if (j == -1 || arg.charAt(i) == arg.charAt(j)) { i++; j++; next[i] = j; } else {//若上一轮匹配到的前j个元素加上这轮新来的一个元素现在不能满足这么长的前缀等于后缀,则找到之前求得的next[j],说明当前满足的前缀要变短才能匹配。 j = next[j]; } } return next; } }
上面的i,j等注释,是我个人理解,如果有误,请各位一定指出!!!!感激不尽!!!!
六、KMP模式匹配算法的改进
在KMP算法中,我们当遇到有j位置匹配不上的情况时,要去查next[j];如果再匹配不上,再查next[next[j]],这样会浪费一些时间。那我们是不是可以优化一下next[]数组?
1,原理:如果pj = pnext[j],就让j = next[j],跳过一个无用的比较。
代码如下
private static int[] getNextval(String arg) { int[] nextval = new int[arg.length() + 1]; nextval[0] = -1; int i = 0;//模式串中当前匹配到的位置的下标值 int j = -1;//子串匹配前缀最后一个位置的下一个元素的下标 while (i < arg.length()) { if (j == -1 || arg.charAt(i) == arg.charAt(j)) { i++; j++; if (arg.charAt(i) != arg.charAt(j)){ nextval[i] = j; }else { nextval[i] = nextval[j]; } } else {//若上一轮匹配到的前j个元素加上这轮新来的一个元素现在不能满足这么长的前缀等于后缀,则找到之前求得的next[j],说明当前满足的前缀要变短才能匹配。 j = nextval[j]; } } return nextval; }