[从今天开始修炼数据结构]线性表及其实现以及实现有Itertor的ArrayList和LinkedList
[从今天开始修炼数据结构]栈、斐波那契数列、逆波兰四则运算的实现
[从今天开始修炼数据结构]队列、循环队列、PriorityQueue的原理及实现
一、线性表
1,什么是线性表
线性表就是零个或多个数据元素的有限序列。线性表中的每个元素只能有零个或一个前驱元素,零个或一个后继元素。在较复杂的线性表中,一个数据元素可以由若干个数据项组成。比如牵手排队的小朋友,可以有学号、姓名、性别、出生日期等数据项。
2,线性表的抽象数据类型
线性表的抽象数据类型定义如下。
ADT List
Data
线性表的数据对象集合为{a1,a2,...,a3},每个元素的类型均为DataType
Operation
InitList (L) : 初始化操作,建立一个空的线性表L
ListEmpty (L) : 若线性表为空,则返回true,否则返回false
ClearList(L): 清空线性表
GetElem(L,i,e): 将线性表L中的第i个位置元素值返回给e
LocateElem(L,e): 在L中查找与给定值e相等的元素,若查找成功,返回位
序;若查找失败,返回0
ListInsert(L,i,e): 在L中的第i个位置插入新元素e
ListDelete(L,i,e): 删除线性表L中的第i个未知元素,并通过e返回其值
ListLength(L): 返回L中的元素个数
endADT
上述操作是最基本的,对于实际中涉及的线性表有更复杂的操作,但一般可以用上述简单操作的组合来完成,例如我们来思考将线性表A和B组合,实现并集操作,只要循环B中的元素,判断该元素是否在A中,若不存在,插入A即可,实现如下。
public class ListDemo { public static void main(String[] args){ List<String> ListA = new ArrayList<String>(); List<String> ListB = new ArrayList<String>(); ListA.add("zhang"); ListA.add("li"); ListA.add("wang"); ListB.add("zhang"); ListB.add("li"); ListB.add("liu"); for (String name: ListB ) { if (!ListA.contains(name)){ ListA.add(name); } } System.out.println(ListA.toString()); } }
二、线性表的顺序存储结构
1,顺序存储结构的实现
可以用一维数组来实现顺序存储结构。描述顺序存储结构需要三个属性:
1,存储空间的起始位置:即数组的存储位置
2,线性表的最大存储容量:数组初始化的长度
3,线性表的当前长度

2,顺序存储结构的泛型实现
package List;
import java.util.Iterator;
import java.util.List;
public class ArrayListDemo<T> {
//初始化后可存放的数量,从1开始计数
private int capacity;
//private T[] data; 不能构造泛型数组,我们用Object[]
private Object[] data;
//已存的数量,从0开始计数。 当size == capacity 时,满。 size = index + 1.
private int size;
private static int DEFAULT_CAPACITY = 10;
/**
* 自定义顺序存储线性表的构造函数
* @param capacity 数组的初始化长度
*/
public ArrayListDemo(int capacity) {
//下面写法会报错。因为Java中不能使用泛型数组,有隐含的ClassCastException
//date = new T[length];
//那么JDK中的ArrayList是怎么实现的?
//JDK中使用Object[]来初始化了表
if (capacity > 0){
this.capacity = capacity;
this.data = new Object[capacity];
size = 0;
}else {
throw new IndexOutOfBoundsException("长度不合法");
}
}
public ArrayListDemo() {
this(DEFAULT_CAPACITY);
}
public void add(T element){
if (size >= capacity){
grow();
}
data[size++] = element;
}
private void grow() {
capacity = (int)(capacity * 1.5);
Object[] newDataArr = new Object[(int)(capacity)];
for (int i = 0; i < size; i++){
newDataArr[i] = data[size];
}
data = newDataArr;
}
/**
* 指定序号元素的获取,Java核心技术中称随机存取
* @param index 得到数组元素的角标
* @return 对应的数据元素
*/
public T getElem(int index){
if (index >= size){
throw new IndexOutOfBoundsException();
}
return (T) data[index]; //这里会报警告,如何解决?
}
public void insertElem(int index, T elem){
if (size == capacity){
grow();
}
for (int i = size - 1; i > index; i--){
data[i + 1] = i;
}
size++;
data[index] = elem;
}
private void checkIndex(int index)throws IndexOutOfBoundsException{
//TODO
if (index < 0){
throw new IndexOutOfBoundsException();
}
}
/**
* 从指定index的位置上移除元素,且返回该元素的值
* @param index 要移除的索引
* @return 被移除的元素的值
* @throws IndexOutOfBoundsException 超出范围
*/
public T removeElem(int index)throws IndexOutOfBoundsException{
checkIndex(index);
if (index >= size){
throw new IndexOutOfBoundsException();
}else {
Object elem = data[index];
for (int i = index; i < size - 1; i++){
data[i] = data[i + 1];
}
size--;
return (T)elem; //这里会报警告,如何解决?
}
}
public int size(){
return capacity;
}
public ArrayListItertor itertor(){
return new ArrayListItertor();
}
private class ArrayListItertor implements List {
private int currentIndex;
public ArrayListItertor(){
currentIndex = 0;
}
@Override
public boolean hasNext() {
return !(currentIndex >= size);
}
@Override
public Object next() {
Object o = data[currentIndex];
currentIndex++;
return o;
}
}
}
顺序存储结构的优点:无需为表中元素的逻辑关系而增加额外的存储空间;可以快速存取表中任意位置的元素
缺点:插入和删除操作需移动大量元素;当线性表长度变化较大时,难以确定存储空间容量;造成存储空间的“碎片”。
三、链式存储结构
1,链式存储结构的概念
为了表示每个数据元素ai与其直接后继数据元素ai+1之间的逻辑关系,对数据元素ai来说,除了储存其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。把存储数据元素信息的域成为数据域,把存储后继位置的域成为指针域。
指针域中存储的信息称作指针或链,这两部分信息组成数据元素ai的存储映像,称为结点Node。
链表中第一个结点的存储位置叫做头指针。
链表中最后一个结点指针为“空”。

2,链式存储结构的实现
package List; import java.nio.file.NotDirectoryException; import java.util.Collection; import java.util.Iterator; import java.util.LinkedList; /* 模仿JDK的双向链表实现一个简单的LinkedList 没有头结点 */ public class LinkedListDemo<T> implements Iterable { private Node<T> firstNode; private Node<T> lastNode; private int size; public LinkedListDemo(){ size = 0; } /** * 在表尾插入一个新节点 * @param data 新节点的数据域 */ public void addLast(T data){ Node<T> last = lastNode; Node<T> node = new Node<>(data, last, null); lastNode = node; if (last == null){ firstNode = node; } else{ last.nextNode = node; } size++; } /** * 在表头插入一个新结点 * @param data 新结点的数据域 */ public void addFirst(T data){ Node<T> first = firstNode; Node<T> node = new Node<T>(data,null, first); firstNode = node; if (first == null){ lastNode = node; }else { first.preNode = node; } size++; } public T get(int index){ checkIndex(index); return search(index).data; } public int size(){ return size; } private Node<T> search(int index){ checkIndex(index); Node<T> pointer = firstNode; for (int i = 0; i < index; i++){ pointer = pointer.nextNode; } return pointer; } /** * 在index前面插入一个元素 * @param index 索引 * @param data 数据域 */ public void insert(int index, T data){ checkIndex(index); if (index == 0){ Node<T> f = firstNode; Node<T> newNode = new Node<>(data, null, f); firstNode = newNode; f.preNode = newNode; }else { Node<T> n = search(index); Node<T> pre = n.preNode; Node<T> newNode1 = new Node<>(data, pre, n); pre.nextNode = newNode1; n.preNode = newNode1; } size++; } /** * 检查index是否越界.合法的最大index = size - 1. * @param index 要检查的索引 */ private void checkIndex(int index) { if (index >= size || index < 0){ throw new IndexOutOfBoundsException(); } } /** * 根据结点的次序来删除结点。 后发现与JDK中的删除操作不同。 * JDK中LinkedList没有按照次序插入或删除的操作,都使用比较数据域是否相同的方法来删除。 * @param index 结点的次序 * @return 被删除结点的数据域 */ public T remove(int index){ checkIndex(index); Node<T> pointer = search(index); Node<T> pre = pointer.preNode; Node<T> next = pointer.nextNode; if (firstNode == null) { pre.nextNode = next; }else { pre.nextNode = next; pointer.nextNode = null; } if (next == null){ lastNode = pre; }else { next.preNode = pre; pointer.preNode = null; } size--; return pointer.data; } /** * 清空链表,帮助GC回收内存。 * 在JDK中,LinkedList实现了Iterator,如果迭代到链表的中间,那么只释放表头的话就不会引起GC回收 * 所以要在循环中逐一清空每一个结点。 */ public void clear(){ for (Node<T> pointer = firstNode;pointer != null; ){ Node<T> next = pointer.nextNode; pointer.data = null; pointer.preNode = null; pointer.nextNode = null; pointer = next; } size = 0; firstNode = null; lastNode = null; } private static class Node<T>{ T data; Node<T> nextNode; Node<T> preNode; public Node(){ } private Node(T data, Node<T> pre, Node<T> next){ this.data = data; this.preNode = pre; this.nextNode = next; } } public LinkedListItertor itertor(){ return new LinkedListItertor(); } class LinkedListItertor implements Iterator{ private Node<T> currentNode; private int nextIndex; public LinkedListItertor(){ currentNode = firstNode; nextIndex = 0; } @Override public boolean hasNext() { return nextIndex != size; } @Override public T next() { Node<T> node = currentNode; currentNode = currentNode.nextNode; nextIndex++; return node.data; } } }
单链表与顺序存储结构对比:
| 单链表 | 顺序存储结构 | |
| 查找 | O(n) | O(1) |
| 插入和删除 | O(1) | O(n) |
| 空间性能 |
需要预分配;分大了容易浪费;分小了需要扩容 |
不需要预分配 |
三、静态链表
1,什么是静态链表?
用数组描述的链表叫做静态链表。该数组的每一个元素有两个数据域,data存储数据,cur存储后继结点的角标。该数组会被建立的大一些,未使用的作为备用链表。
该数组的第一个元素的cur存储备用链表的第一个节点的下标;数组最后一个元素的cur存储第一个有数值的元素的下标。如下图。

若为新建的空链表,则如下图。
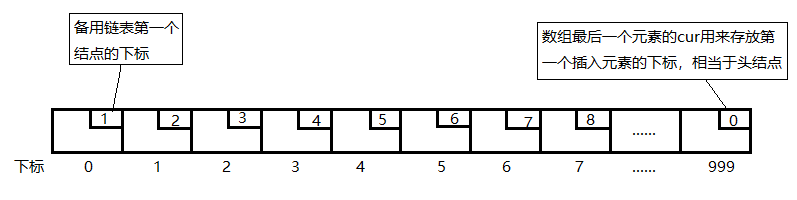
2,静态链表的实现
package List; import java.util.List; import java.util.prefs.NodeChangeEvent; public class StaticLinkList <T>{ private ListNode<T>[] list; private static int DEFAULT_CAPACITY = 1000; private int capacity; private int size; // private ListNode firstNode; // private ListNode endNode; // private int capacity; // private int size; private StaticLinkList(int capacity){ this.capacity = capacity; list = new ListNode[capacity]; list[0] = new ListNode<T>(null, 1); list[capacity - 1] = new ListNode<T>(null, 0); size = 0; /* size = 0; this.capacity = capacity; list = new Object[capacity]; firstNode = new ListNode<Integer>(null, 1); list[0] = firstNode; endNode = new ListNode<Integer>(null, 0); list[capacity - 1] = endNode; */ } public int size(){ return capacity; } public StaticLinkList(){ this(DEFAULT_CAPACITY); } public void addLast(T data){ ListNode tail = FindTail(); ListNode<T> newNode = new ListNode<T>(data, 0); list[list[0].cur] = newNode; tail.cur = list[0].cur; synchronize(); size++; } /** * 在index前面插入一个元素 由于是单向链表,所以要先取到index上一个元素 * @param index 角标 * @param data 数据 */ public void insert(int index, T data){ ListNode beforeIndexNode = searchPreNode(index); int indexCur = beforeIndexNode.cur; ListNode<T> newNode = new ListNode<T>(data, indexCur); list[list[0].cur] = newNode; beforeIndexNode.cur = list[0].cur; synchronize(); size++; } private void synchronize(){ int i = 1; while(list[i] != null){ i++; } list[0].cur = i; } public T delete(int index){ checkIndex(index); ListNode<T> preNode = searchPreNode(index); ListNode<T> indexNode = list[preNode.cur]; //这行报错NullPointerException int cur = indexNode.cur; preNode.setCur(indexNode.getCur()); indexNode.cur = 0; T data = indexNode.data; indexNode.data = null; synchronize(); size--; return data; } public void checkIndex(int index){ if (index >= size){ throw new IndexOutOfBoundsException(); } } private ListNode FindTail(){ ListNode tailNode = list[capacity - 1]; while (tailNode.cur != 0){ tailNode = list[tailNode.cur]; } return tailNode; } /** * 拿到index - 1这个结点,才能将新结点插入到index位置上 * @param index 要插入的索引(从0开始) * @return 返回查找到的结点 */ private ListNode<T> searchPreNode(int index){ ListNode<T> node = list[capacity - 1]; for(int i = 0; i < index; i++){ node = list[node.cur]; } return node; } private class ListNode<T>{ private T data; private int cur; private ListNode(T data, int cur){ this.data = data; this.cur = cur; } public void setData(T data) { this.data = data; } public void setCur(int cur) { this.cur = cur; } private T getData(){ return data; } private int getCur(){ return cur; } } }
3,静态链表的优点:在插入和删除操作时,只需要修改游标,不需要移动元素。
缺点:没有解决连续存储分配带来的表长难以确定的问题; 失去了顺序存储结构随机存取的特性。
在高级语言中不常使用,但可以学习这种解决问题的方法。
四、循环链表
1,什么是循环链表
将单链表中终端节点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表成为单循环链表,简称循环链表
循环链表解决了一个很麻烦的问题,如何从当中一个结点出发,访问到链表的全部结点。循环链表的结构如下图所示

单链表表尾的判断是p->next是否为空,而循环链表是判断p->next是否为头结点。
2,改造循环链表
我们在上面的循环链表中,访问表头的复杂度为O(1) , 访问表尾的复杂度为O(n)。那么能不能让访问表尾的复杂度也为O(1)呢?
我们把头指针改为尾指针,如下图

这样不管是访问表头还是表尾都方便了很多。如果我们要把两个循环链表合并,只需要做如下操作。
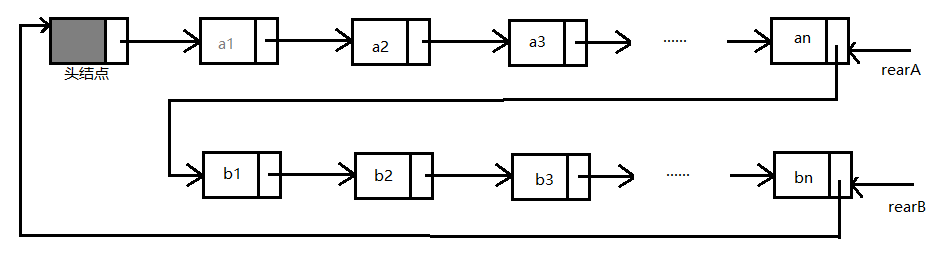
3,循环链表的实现
package List;
public class CircularLinkedList<T> {
private Node<T> last;
private Node<T> headNode;
public CircularLinkedList(){
Node<T> node = new Node<>();
headNode = new Node<T>(null, node);
last = new Node<T>(null, headNode);
headNode.nextNode = last;
}
/**
* 添加数据时先调用此函数设置last中的data,然后再使用add添加其他元素
* @param data last中的data
*/
public void setLast(T data){
last.data = data;
}
public void add(T data){
Node<T> newNode = new Node<>(data, headNode);
last.nextNode = newNode;
last = newNode;
}
public T deleteFromLast(){
Node<T> lastNode = last;
T data = lastNode.data;
//lastNode.data = null;
Node<T> node = lastNode;
while (node.nextNode != last){
node = node.nextNode;
}
node.nextNode = headNode;
last = node;
lastNode.nextNode = null;
lastNode.data = null;
return data;
}
public boolean combine(CircularLinkedList<T> circularLinkedList){
Node<T> listHeadNode = circularLinkedList.last.nextNode;
last.nextNode = circularLinkedList.last.nextNode.nextNode;
circularLinkedList.last.nextNode = headNode;
listHeadNode.nextNode = null;
last = circularLinkedList.last;
return true;
}
private static class Node<T>{
T data;
Node<T> nextNode;
public Node(){
}
private Node(T data, Node<T> next){
this.data = data;
this.nextNode = next;
}
}
}
双向链表的实现在上面ArrayList的实现中给出。
总结:
我们就线性表的两大结构做了讲述,先将的顺序存储结构,通常用数组实现;然后是我们的重点,由顺序存储结构的插入和删除操作不方便,消耗时间大,受固定的存储空间限制,我们引入了链式存储结构。分为单链表、静态链表、循环链表、双向链表做了讲解。
