1.Jpa的介绍与使用
JPA(Java Persistence API)是Sun官方提出的Java持久化规范。它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合ORM技术,结束现在Hibernate,TopLink,JDO等ORM框架各自为营的局面。值得注意的是,JPA是在充分吸收了现有Hibernate,TopLink,JDO等ORM框架的基础上发展而来的,具有易于使用,伸缩性强等优点。从目前的开发社区的反应上看,JPA受到了极大的支持和赞扬
注意:JPA是一套规范,不是一套产品,那么像Hibernate,TopLink,JDO他们是一套产品,如果说这些产品实现了这个JPA规范,那么我们就可以叫他们为JPA的实现产品。
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
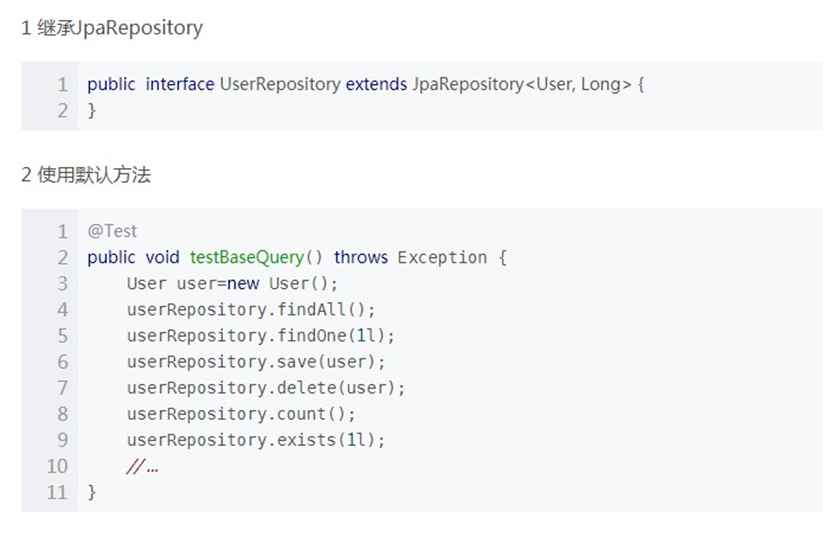
使用时需要继承JpaRepository
2.JPA的基本查询—默认实现
3.Springboot集成JPA
引入依赖
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- springdata jpa依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
修改配置文件
###数据源配置 ######################################################## spring.datasource.url = jdbc:mysql://localhost:3306/springboot spring.datasource.username = root spring.datasource.password = root spring.datasource.driverClassName = com.mysql.cj.jdbc.Driver spring.datasource.max-active=20 spring.datasource.max-idle=8 spring.datasource.min-idle=8 spring.datasource.initial-size=10 ######################################################## ### 持久化配置 ######################################################## # Specify the DBMS spring.jpa.database = MYSQL # Show or not log for each sql query spring.jpa.show-sql = true # Hibernate ddl auto (create、create-drop、update、validate、none) #validate: 在每次项目启动的时候,会自动进行表结构与我们的实体类的验证,如果表结构与实体类的代码不相符,就会产生报错。 spring.jpa.hibernate.ddl-auto = update # Naming strategy #[org.hibernate.cfg.ImprovedNamingStrategy #org.hibernate.cfg.DefaultNamingStrategy] spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.ImprovedNamingStrategy # stripped before adding them to the entity manager) spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
其中,spring.jpa.hibernate.ddl-auto 参数用来配置是否开启自动更新数据库表结构,可取create、create-drop、update、validate、none五个值。 create 每次加载hibernate时,先删除已存在的数据库表结构再重新生成;create-drop 每次加载hibernate时,先删除已存在的数据库表结构再重新生成,并且当 sessionFactory关闭时自动删除生成的数据库表结构;update 只在第一次加载hibernate时自动生成数据库表结构,以后再次加载hibernate时根据model类自动更新表结构;validate 每次加载hibernate时,验证数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。none 关闭自动更新
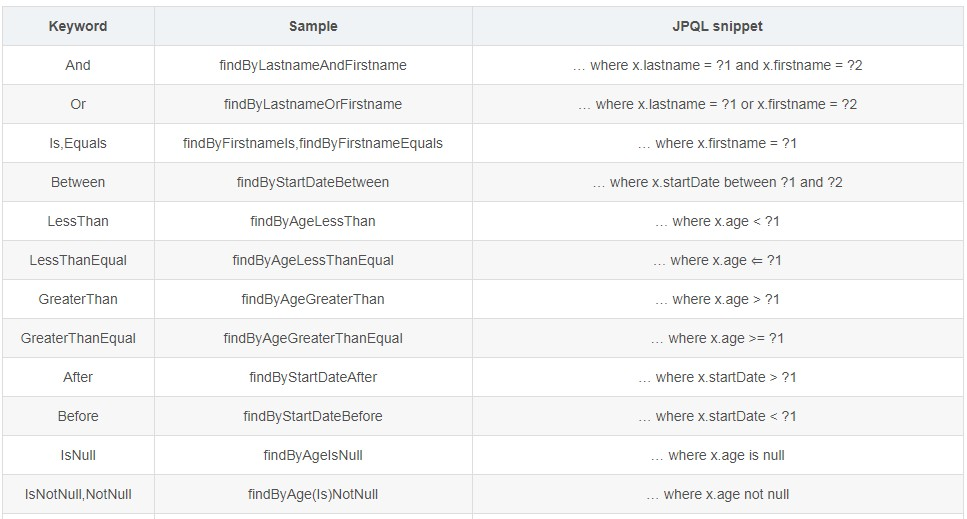
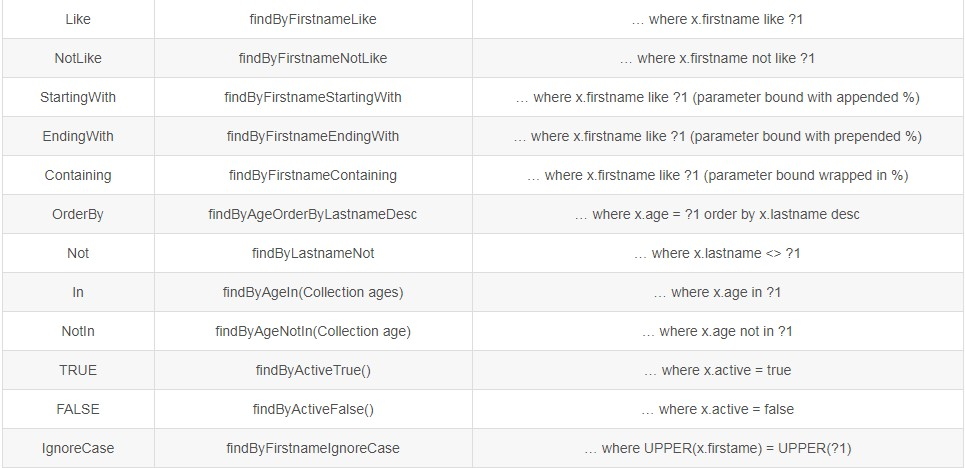
4.JPA的基本查询—方法名解析
5.JPA的复杂查询-分页查询
分页查询在实际使用中非常普遍了,spring data jpa已经帮我们实现了分页的功能,在查询的方法中,需要传入参数Pageable ,当查询中有多个参数的时候Pageable建议做为最后一个参数传入Pageable 是spring封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则
Page<User> findALL(Pageable pageable); Page<User> findByUserName(String userName,Pageable pageable);
6.JPA的复杂查询-限制查询
有时候我们只需要查询前N个元素,或者只取前一个实体。
User findFirstByOrderByAgeAsc(); User findTopByOrderByAgeDesc(); List<User> findFirst10ByAge(Integer age, Sort sort); List<User> findTop10ByAge(Integer age, Pageable pageable);
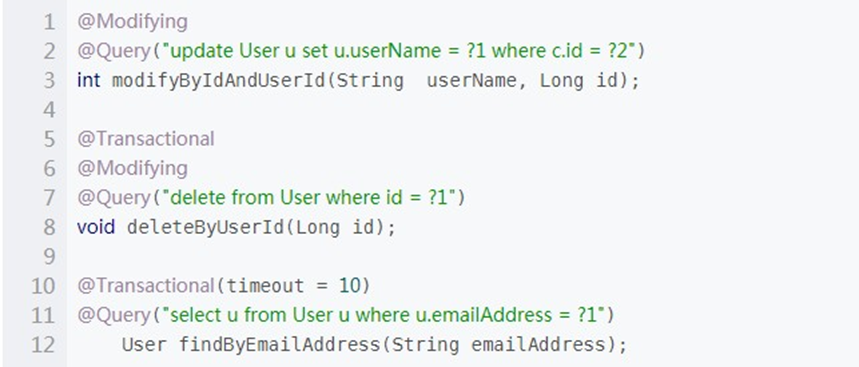
7.自定义SQL查询
其实Spring data 觉大部分的SQL都可以根据方法名定义的方式来实现,但是由于某些原因我们想使用自定义的SQL来查询,spring data也是完美支持的;在SQL的查询方法上面使用@Query注解,如涉及到删除和修改在需要加上@Modifying.也可以根据需要添加 @Transactional 对事物的支持,查询超时的设置等