参考知乎大佬:https://zhuanlan.zhihu.com/p/62892586
一、倒排索引
倒排索引也叫反向索引,举个例子,理解一下。叫你背一首《静夜思》,立马可以背出,但是叫你被一首包含“前”字的是诗,你却想不到《静夜思》。但是如果我们以“前”作为索引,这样就可以背出来。简单理解正常索引就是正常背诗,从诗名到作者到内,倒排索引就是被带有“前”字的诗,背的过程可以理解为建立索引的过程。但是这样会引发一个问题。类别数据库索引,正常背诗就是聚合索引,通过建立主键索引。
二、搜索量爆炸
一首《静夜思》内容有20个字,如果每个字都建立倒排索引,例如
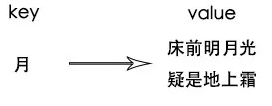
这样数据量爆炸增长,所以我们可以把value值改为诗名,这样可以大大压缩数据内容。类别数据库索引,反常背诗就是非聚合索引,通过多内容字段新建索引,索引指向主键值,在通过主键找到目标内容。
对于一些常用的字段,每次调用都要进行非聚会索引的话,总是要通过主键查找,这样会产生大量的io操作,占用CPU,应对这一问题,出现了覆盖索引,也称多字段查询。即在建立新索引时把索引的内容添加到value值中,这样就可以直接索引,而不用通过主键索引,这里有个知识点,联合索引,左端原则,就不展开了,有兴趣的伙伴可以自己Google一下。
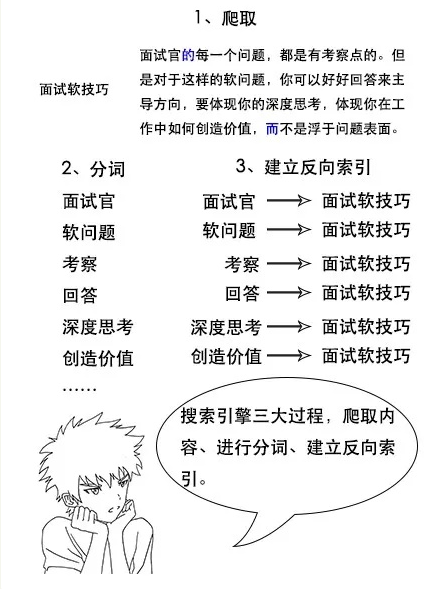
三、搜索引警原理
通常搜索引警都是通过词语找文章,ES也是如此。它们的核心就是建立倒排索引,还包括爬虫、停顿词过滤等等。爬虫就是网页爬取。停顿词过滤就是把一句话中的没有意思的词过滤,例如“了”,“啊”等等。也即分词。
四、Elasticsearch介绍
利用lucence库可以很方便的建立倒排索引,但是 Lucene 还是一个库必须要懂一点搜索引擎原理的人才能用的好,所以后来又有人基于 Lucene 进行封装,写出了 Elasticsearch。
es的好处:
a、es对搜素引警的操作都封装成了restful的api,通过http请求就可以对其操作。
b、考虑到海量数据,实现了分布式,是一个可以存储海量数据的分布式搜索引警。
阅读到此处可以转到我的另一篇博客,内容有重复就不写了。
https://www.cnblogs.com/JimShi/p/11309651.html
五、Elasticsearch中如何建立索引
a、之前我们说过,Elasticsearch 把操作都封装成了 HTTP 的 API,我们只要给 Elasticsearch 发送 HTTP 请求就行。比如使用 curl -XPUT 'http://ip:port/poems',就能建立一个名为 Poems 的索引,其他操作也是类似的。
b、可以通过es的数据展示工具Kibana操作,GET、POST、PUT、DELETE
详细请看我的另一篇微博,kibana的基本操作:https://www.cnblogs.com/JimShi/p/11242657.html
六、Elasticsearch分布式原理
详情请看我的另一篇博客:https://www.cnblogs.com/JimShi/p/11309640.html
七、ELK系统
很多公司都用 Elasticsearch 搭建 ELK 系统,也就是日志分析系统。其中 E 就是 Elasticsearch,L 是 Logstash,是一个日志收集系统,K 是 Kibana,是一个数据可视化平台。
分析日志的用处可大了,你想,假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。依赖Elasticsearch提供的强大的反向索引功能,可以根据关键字查询关键的错误日志。