接下来我们开始新的学习,对于一门完全全新的语言大家可以准备好从头开始学习了...
好消息是如果你对之前的基础掌握并不是那么牢靠,那么这部分知识点是一个新的开始,坏消息是这部分内容需要你们调用你们的小脑袋瓜记住了。
首先介绍什么是前端:任何与用户直接面对面的操作界面我们都称他们为前端,那么我们就有了相应的后端的概念,所有与用户不是直接打交道的我 们都称其为后端。
前端对于我们来说更多的意味着网页等形式,所以我们的学习就从网页入手。
提到了网页我们就必须提一下网页的几大巨头他们分别是HTML:骨架,没有任何的样式。
CSS: 给网页添加样式,让骨架看上去像是人了。
JS:控制网页动态效果,让上一步得到的模型像人一样动起来。
大家可以思考一下,当我们浏览网页的时候都发生了什么?
1.浏览器向服务端发送请求
2.服务端接受请求
3.服务端向浏览器发送结果
4.浏览器接受结果,将网页展示给我们
所以我们在浏览网站时候虽然我们等待的时间特别短,但是我们的浏览器与服务端就完成了这些操作。
我们发现我们在使用浏览器的时候我们的浏览器是一个客户端的角色,我们可以与多种不同的服务端进行交互,比如我们可以打开腾讯的网页,可以打开百度的网页,而这些网页的语言并不相同,浏览器是如何做到集百家之长的呢?
其实我们不难发现,我们在学习数据库的时候也遇到过相同的问题,我们当时提出了两种方案,其中通晓百家语言这条被我们pass掉了,所我们也需要一个限制来限制这些服务端的语言。
HTTP协议:超文本传输协议,用来限制服务端发送给浏览器的数据格式,使我们真正成为统一的格式。
当然作为一种限制而不是强制,你也可以不使用这种协议,但是就需要进行自己书写客户端了,浏览器是不认识你的。
这里需要我们记住的有该协议的四大特性:
1.基于请求响应,也就是有请求才会有响应
2.基于TCP/IP作用于应用层之上的协议
3.无状态,不保存用户状态,也就是对于服务端来说你的每次请求都来自一个他不认识的客户端
4.无/短链接 一次请求对应一次连接,之后就没有其他的任何联系(对应的长连接就是双方建立连接之后默认不断开)
说了半天我们各大厂商不得不为之服软的协议它的格式究竟是什么样的呢?
请求数据格式:
请求首行(标注着协议的版本,请求方式等)
请求头 (一大堆k,v键值对)
换行符(/r/n)必不可少
请求体(并不是所有的请求方式都有这个部分,get没有 post有,存放的是提交的敏感数据)
既然介绍了请求那么就不得不说一下响应了
响应数据格式:
响应首行(标注着协议的版本,响应状态码)
响应头 (一大堆k,v键值对)
换行符(/r/n)必不可少
响应体(返回给浏览器并最终展示给用户的内容)
响应状态码:响应状态码有很多,尤其是各个公司内部又为了更加详细地描述会出现的问题所设计的状态码更是数不胜数,所以我们只需要知道几个 通用且常用的即可
1xx:服务端成功接收了请求并且在处理数据,可以继续发送请求
2xx:服务端成功响应了你想请求的数据
3xx:重定向,概念上我更加倾向于后台自己完成的网页跳转,也就是有你访问的a页面自动跳转到b页面
4xx:请求失败
403:当前请求不合法或者不符合访问资源的条件
404:请求的内容丢失
5xx:服务端错误
上述内容是否已经把小伙伴看蒙蔽了,其实知识点一点也不紊乱,我们在了解请求数据结构是发现我们提交请求数据的方法不同我们所发送的格式也不同,那么接下来我们就介绍一下get和post方法吧。
请求方法:
get方法:像服务端要数据(就像你像你爸要零花钱,直接伸手)
post方法:像服务端提交数据 (就像你取找银行要钱,需要提供你的银行卡,看看自己的余额还特么不努力?)
这里穿插一个我们之后会经常用到的知识点url
url:统一资源定位符 其实也就是网址。

接下来我们就来介绍一下我们使用的统一语言吧。
HTML语言简介:既然我们之前就类比了sql数据库那么接下来我们就来认识一下前端中独有的语言,虽然之后我们使用的仍旧是别人封装好的框架,但是我们仍然要接触底层代码。
老规矩在接触一门新的语言之前我们先来接触一下他的注释。
在HTML语言中我们使用
<!--内容-->来进行单行注释
<!--
内容
内容
内容
-->来进行多行注释
文档结构:
标签的分类依据1: 根据结构可以分为
双标签<h1></h1>有头有尾型
单标签(也叫自闭和标签)<img>有头无尾型
head内常用标签:

body内常用标签:我们所直观看到的网页的内容基本上都是由body内内容决定的
基本标签:

特殊标签:
空格
> 大于号
< 小于号
& &
¥ ¥
© ©
商标® ®
标签的分类依据2:我们在完成简单的HTML编写之后实用浏览器打开,发现不同的标签所占位置的大小是不同的,那么我们就根据这个来 为标签进行第二次分类。
1.块级标签:不管内容是否满一行都独占一行 exp:h p div 等标签
块级标签可以修改占空间的大小
块级标签内可以嵌套任意的行内标签和块级标签(p标签除外,p只能套行内标签)
2.行内标签:只占据内容大小的空间
行内标签不可以修改占空间的大小,即使修改了变化也不大
行内标签只能嵌套行内标签
常用标签:
div块标签:我还是更愿意称他为块标签,因为正如名字一样div就是一块一块的,我们在进行网页布局的时候,我们习惯性的先将整个页面分割成多个块,再依次进行内容填充
span标签:行内标签,一般普通的文本内容也就是网页内的文字部分都是放在span标签内
img标签:
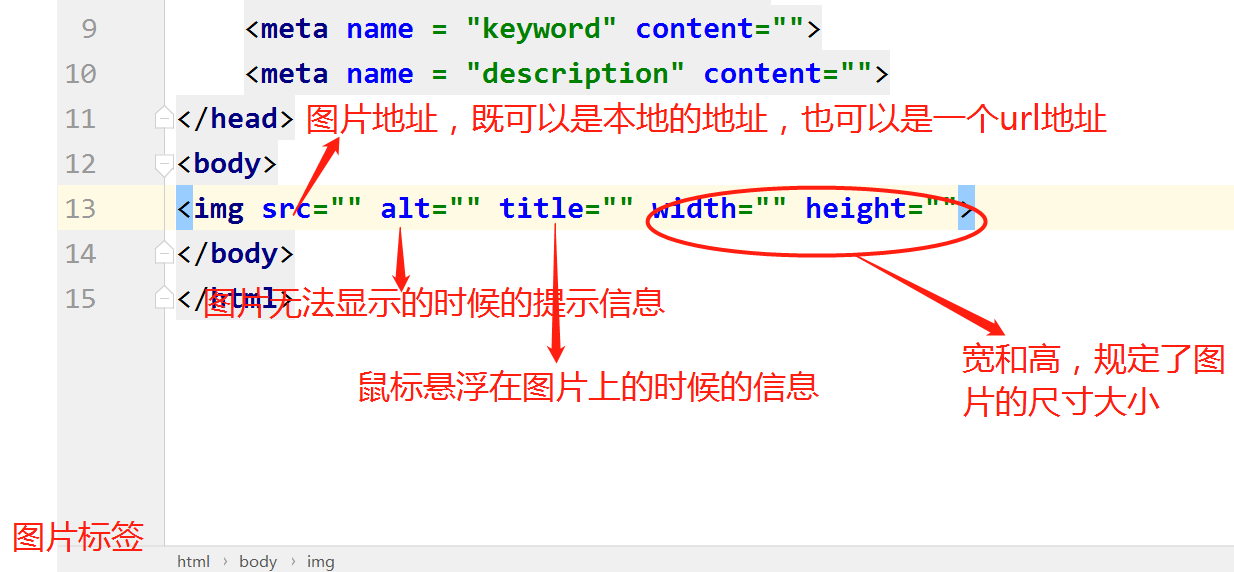
a标签:
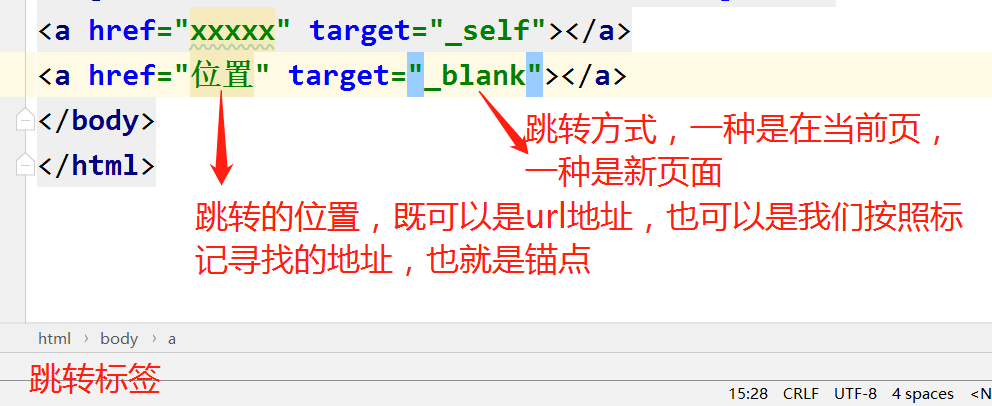
ps(self是当前页面,blank是新页面)
标签的重要属性:
1.id值 类似于标签的身份证号 在同一个html页面上id值不能重复
2.class值 该值有点类似于面向对象里面的继承 一个标签可以继承多个class值
列表标签:
无序 <ul>
<li></li>
</ul>
有序 <ol>
<li></li>
</ol>
标题 <dl>
<dt>标题</dt>
<dd>内容</dd>
</dl>