接口
一、接口的基本概念
关键字为:Interface,在JAVA编程语言中是一个抽象类型,是抽象方法的集合。也是使用.java文件编写。
二、接口声明
命名规范:与类名的命名规范相同,通常情况下以大写字母 I 开头,与类作于区分。接口的访问修饰符只能使用public或者缺省修饰,不能使用protected和private修饰。
接口中的所有属性只能是公开的静态的常量: public static final 数据类型 属性名 ;(public/static/final可以省略)
接口中的所有方法必须是公共的抽象方法,而且接口中的抽象方法也可以省略public/abstract关键字。写法:public abstract 返回值类型 方法名();
三、接口的使用
一个类实现接口使用implements关键字,实现类实现接口必须重写接口中的所有方法,除非实现类也是个抽象类。(可以多实现接口,多个接口之间用逗号隔开)。
class 实现类 implements 接口1,接口2{//某类实现了两个接口 @Override public void print() { System.out.println("接口1的抽象方法print()"); } @Override public void get() { System.out.println("接口2的抽象方法get()"); } }
四、接口的引用
 3.ArrayList和LinkedList的区别
3.ArrayList和LinkedList的区别
接口的引用可以指向实现类的对象,类似于父类引用指向子类对象。
例如: ITest t = new TestImpl();
五、接口的继承
在Java中,一个接口可以使用extends关键字同时继承多个接口,当实现类在实现C接口的时候需要重写接口C和其父类接口A和接口B的方法。
例如:
interface A{ public void funA(); } interface B{ public void funB(); } interface C extends A,B{//C接口同时继承了A和B两个接口 public void funC(); }
六、接口优点
(1).可以被多继承
(2).设计和实现完全分离
(3).更自然的使用多态
(4).更容易搭建程序框架
(5).更容易更换实现
七、抽象类和接口的区别
(1).本质区别:class和interface关键字不同。 抽象类是类,接口是一种规范。子类继承抽象类,要求子类必须和父类是一类事物,必须符合"is a"关系,例如:Chinese is a people。接口只是对功能的拓展,多个实现类实现接口时并不要求所有的实现类是一类事物。接口符合"like a"关系,理解为"XX具备什么样的功能"。
(2).接口可以多继承多实现,抽象类只能单继承。
(3).抽象类可以有自己的属性,接口中只能有静态常量。
(4).接口中的方法必须是抽象方法,抽象类可以有非抽象方法。(接口中的抽象方法可以省略abstract)
(5).抽象类是类,接口是一种规范。
子类继承抽象类,要求子类必须和父类是一类事物
接口并不要求多个实现类是同一类事物,只是进行设计与实现的分离。
集合框架
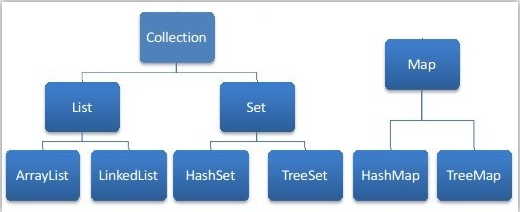
一、集合框架体系图
二、四个接口的区别
collection:存储不唯一、无序的数据。
list:存储有序的、不唯一的数据。记录先后添加的顺序。
set: 存储无序的、唯一的数据。不记录先后添加多少顺序。
map: 以键值对的形式存储数据,以键取值,键不可以重复,值可以重复。
三、List以及List子类和常用方法
ArrayList :是数组结构,长度是可变的,ArrayList不是线程安全的。
LinkedList:是基于双向循环链表实现的,是链表结构。
Vector : 线程安全的,其他的月ArrayList类似
1.常用方法:
(1)add(E e):在列表的末尾插入元素
(2)add(int i,E e): 在列表指定位置插入元素。
(3)size():返回当前列表的长度。
(4)get(int index):返回下标为index的元素,如果没有泛型的约束,需要强转,如果有泛型的约束无需强转。
(5)clear():移除此列表中的所有元素。
(6)contains():传入一个对象,检测列表中是否包含该对象,如果此列表中包含指定的元素,则返回 true。(如果传入的是String和基本数据类型可以直接比对,如果传入的是实体对象,则默认只比对两个对象的地址,因此在实体类中重写equals()方法)
(7)isEmpty():如果此列表中没有元素,则返回 true。
(8)remove(int index): 移除列表中制定位置的元素,如果下标大于size,会报下标越界异常。
(9)remove(object o): 要求重写equals方法,返回true或false,移除列表中第一次出现的元素。
(10)removeRange(int fromIndex, int toIndex):移除列表中索引在 fromIndex(包括)和 toIndex(不包括)之间的所有元素。
(11)indexof(object o):传入一个对象,返回该对象在列表中首次出现的地址。
(12)lastIndexof(object o):传入一个对象,返回该对象在列表中最后一次出现的地址。
(13)set(int index, E e): 用指定的元素替代此列表中指定位置上的元素。
(14)subList(fromIndex, toIndex):截取一个子列表,fromIndex(包括)和 toIndex(不包括)之间的所有元素,返回List类型。
(15)toArray():将列表返回一个object类型的数组。
2.遍历列表
1.使用for循环遍历列表
2.使用foreach循环遍历列表
3.使用迭代器遍历列表(iterator)
使用列表调用iterator()方法,返回一个迭代器对象。
使用迭代器调用hasNext()方法,判断是否有下一条数据。
使用迭代器对象调用next()方法,取出下一条数据。
ArrayList<String> strings = new ArrayList<String>(); strings.add("123"); strings.add("345"); Iterator<String> iterator = strings.iterator(); while (iterator.hasNext()) { String s = iterator.next(); System.out.println(s); }
1) ArrayList 实现了一个长度可变的数组,在内存空间中开辟一块空间,和数组的区别是长度可以随时修改。这种循环遍历和随机访问元素的速度比较快。LinkedList 使用链表结构存储数据,在插入和删除元素时比较快。
2) LinkedList特有的方法:
addFirst()和addLast(),分别是开头插入元素和结尾插入元素。
removeFirst()和removeLast(),删除第一个元素或者最后一个元素,并返回删除的元素。
getFirst()和getLast(),查询第一个元素或者最后一个元素,并返回查找到的元素。
四、Set以及Set子类和常用方法
1.常用方法: 与List接口基本相同,但是由于set接口中的元素是无序的,因此没有与下标相关的方法。例如:get(index),remove(index),add(index,E e)。
2.Set集合的特点: 唯一、无序。
3.Set集合的遍历方式:
(1)foreach循环遍历。
(2)迭代器遍历(iterator)。
Iterator<String> iterator = hashSet.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); }
4.HashSet: 底层是调用HashMap的相关方法,传入数据后,根据数据的hashCode进行散列运算,得到一个散列值后再进行运算,确定元素在序列中的位置。
HashSet如何确定一个对象是否想等?
先判断元素的哈希值(hashcode()),如果哈希值不同,肯定不同一个对象,如果哈希值相同,重写equals()方法,再次判断元素的内容是否相同,如果equlas返回true,意味着两个元素相同,如果返回的是false,意味着两个元素不相同,继续通过算法算出位置进行存储。
所以使用HashSet存储实体对象时,必须重写对象的HashCode()和equals()两个方法。
5.LinkedHashSet: 在HashSet的基础上,新增了一个链表,用链表来记录HashSet中元素放入的顺序,因此使用迭代器遍历的时候,可以按照放入的顺序进行打印输出。
6.TreeSet:将存入的元素进行排序,然后再输出。
①如果存入的是实体对象,那么实体类需要实现comparable接口,并重写compareTo()方法。
Class Person implmments Comparable { @Override public int compareTo(Object obj) { Person p = (Person) obj; if (this.age > p.age) { return 1; }else if (this.age < p.age) { return -1; }else{ return 0; } } }
②可以在实例化TreeSet的同时,通过构造函数传入一个比较器(比较器:一个实现了comparator接口,并重写其方法。)
Set<Person> hashSet = new TreeSet<Person>(new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { return o1.getAge()-02.getAge(); } });
③自定义一个比较类,实现conparator()接口,并重写其方法。
TreeSet<Person> list = new TreeSet<Person>(new cp()); class cp implements Comparator<Person>{ @Override public int compare(Person o1, Person o2) { // TODO Auto-generated method stub return o1.getAge()-02.getAge(); } }
五、Map以及Map子类和常用方法
1.特点:以键值对的形式进行存储,以键取值,键不能重复,值可以重复。
2.常用方法:
(1)put(K key, V value): 在列表的末尾插入一个键值对。
(2)get(Object key): 返回到指定键所映射的值。
(3)clear(): 从该列表中删除所有的数据。
(4)containsKey(Object key):如果此集合中包含指定键的映射,则返回 true 。
(5)containsValue(Object value):如果此集合中有一个或多个键映射到制定的值,则返回 true 。
(6)replace(K key, V value):只有当目标映射到某个值时,才能替换指定键的条目。
(7)remove(Object key, Object value) : 仅当指定的密钥当前映射到指定的值时删除该条目。
(8)remove(Object key) : 如果存在(从可选的操作),从该地图中删除一个键的映射。
3.遍历map的方式:
(1)KeySet(): 返回值是一个set集合,通过遍历每一个键得到每一个值。
Set<String> keySet = map1.keySet(); for (String string : keySet) { System.out.println(map1.get(string)); }
(2)values(): 返回值是一个collection接口的集合,直接取到的是map集合中的value值,而无法拿到key。
Collection<String> values = map1.values(); Iterator<String> iterator = values.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); }
(3)entrySet(): 返回此映射的所有的set集合,集合的每个值也是一个key-value的键值对形式的值。
Set<Entry<String, String>> entrySet = map1.entrySet(); for (Entry<String, String> entry : entrySet) { //System.out.println(entry.getKey()+"-"+entry.getValue()); System.out.println(entry); }
entry是java给我们提供的特殊类型,其实就是一个键值对。(取键 getKey();取值 getValue())
4.HashMap和Hashtable的区别:
1.Hashtable是线程安全(线程同步)的,HashMap是线程不安全(线程不同步)的。
2.Hashtable的key不能为null,HashMap的key可以为null。
5.LinkedHashMap:可以使用链表,记录数据存入的次序,进入让读出的顺序与录入的顺序一致,与LinkedHashSet一致。
6.TreeMap:按照键的顺序的进行排序后输出,如果存入的是对象排序方法与TreeSet一致。
Collections工具类
collections : 是Java中专门用于操作集合的工具类。
(1)Collections.sort(list):对集合中的数据进行排序。
如果集合存储的是一个实体对象,那么:
1.实体类实现comparable接口,并重写CompareTo方法
2.在sort第二个参数,传入比较器,需要实现comparator接口,并重写compare方法
(2)Collections.addAll(list, "11","2222"):向集合中添加多个数据(个数可以为多个)。
(3)Collections.binarySearch(list, "list3"):二分法查找数据在当前集合的位置(需要先是有个sort()方法排序)。
如果泛型是个实体类,那么:
1.就必须在实体类中实现comparable接口并重写方法后,才可以使用此方法。
2.在binarySearch第二个参数,传入比较器,需要实现comparator接口,并重写compare方法。
(4)Collections.max(list)/Collections.min(list):返回最大最小值,如果是实体类重写比较器。
(5)Collections.replaceAll(list, oldVal, newVal):替换内容。(需要重写equals方法)
(6)Collections.reverse(list):反转列表中的所有元素。
(7)Collections.shuffle(list):对集合中的元素进行随机排序。
(8)Collections.swap(list, i, j): 将集合中的第i位置的值和j位置的值交换。
(9)Collections.fill(list, "11111"): 将集合中的所有元素替换成一个值。
泛型 -- 参数化类型
1.在定义类型时,不将类型定死,而是采用泛型参数进行定义,使用时传入具体的泛型参数。
2.泛型类: 在声明类的时候加入泛型约束。例如:class Test<T> {private T demo;}(T可以理解成泛型声明的形参,在泛型类中,T就可以当作特殊的数据类型使用)。泛型类调用时需要将实际的数据类型传入。
3.泛型类的特点: 1.泛型只在编译阶段生效,同一个类通过不同泛型拿到对象,使用getClass()判断是属于同一个类的。
2.同一个类,通过不同的泛型拿到的对象,互相互不兼容,不能互相赋值。
3.即便,声明的泛型有父子关系,但是有泛型的父子关系的泛型类也不可以互相赋值。
4.泛型类在实例化的时候可以不传入泛型,类中的数据类型以赋值时传入的数据类型为主.
Test t = new Test();
t.setDemo(123);
t.setDemo("1234");
5.泛型约束时只能传入类型,可以是系统类也可以传入自己的类,但不能传入基本数据类型。
6.泛型约束时,可以同时约束多个泛型。
7.不能对确切的泛型类型使用Instanceof()方法操作。
test2 instanceof test//✔
test2 instanceof test<Integer>//✖
泛型通配符和上下边界
1.为了解决同一个类的多个不同泛型对象相互不兼容的问题,可以使用泛型通配符<?>.
2.<?>表示可以兼容所有类的数据类型。
3.泛型通配符上边界:<? extends 类名>,表示泛型通配符只支持制定类及制定类的子类。
Test<? extends Number> t = new Test<Integer>();//✔
Test<? extends Number> t = new Test<Double>();//✔
Test<? extends Number> t = new Test<String>();//✖
4.泛型通配符下边界:<? super 类名>,表示泛型通配符只支持制定类及其超类。
Test<? super Integer> t = new Test<Integer>();//✔
Test<? super Integer> t = new Test<Number>();//✔
Test<? super Integer> t = new Test<String>();//✖
泛型接口
1.声明泛型接口 interface inter<T>{ void test(T t); } 2.实现类如果实现泛型接口,不能直接使用接口的泛型,需要重新声明 class test3<T> implements inter<T>{ @Override public void test(T t) { // TODO Auto-generated method stub } } 3.如果实现类不想作为泛型类,那么可以实现接口时直接给泛型的接口赋值。 class test3 implements inter<String>{ @Override public void test(String t) { // TODO Auto-generated method stub } }
泛型方法
1.泛型方法可以独立于泛型类,在任何类中都可以使用泛型方法
2.使用泛型方法,可以实现可变参数的方法。
3.如果在方法中声明了<T>的方法才叫泛型方法,如果在方法中使用了类的泛型,这不能称为泛型方法。
class test3{ public <T> void test(T t) { System.out.println(); } public static <T> void test1(T t) { System.out.println(); } public static <T> void test2(T... t) { for(T t1 : t){ System.out.println(); } } } 1.调用:test3.test("String"); 2.调用:test3.test2(1,true,"123"); test3.test2(nwe Integer[]{1,2,3});
注意:静态方法中不能使用类泛型,只能将静态方法单独声明成泛型方法。