金字塔介绍
http://blog.csdn.net/touch_dream/article/details/62419496
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/imgproc/pyramids/pyramids.html
- 一个图像金字塔是一系列图像的集合 - 所有图像来源于同一张原始图像 ,通过对原始图像连续采样获得,直到达到某个终止条件才停止采样。
- 有两种类型的图像金字塔常常出现在文献和应用中:
- 高斯金字塔(Gaussian pyramid): 用来向下采样
- 拉普拉斯金字塔(Laplacian pyramid): 用来从金字塔低层图像向上采样重建图像。
- 高斯金字塔 :为一层一层的图像,层级越高,图像越小。
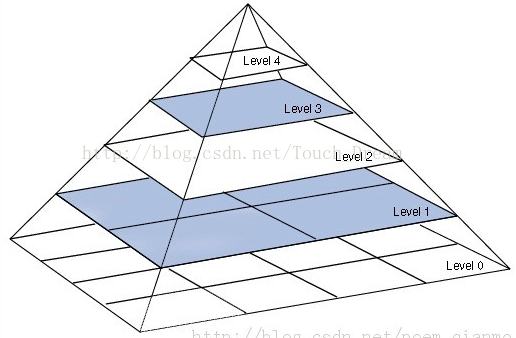
每一层都按从下到上的次序编号, 层级 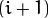 (表示为
(表示为 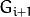 尺寸<
尺寸<  (
(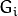 ))。
))。
为了获取层级为 的金字塔图像,我们采用如下方法:
将 与高斯内核卷积: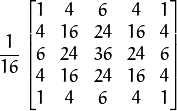
去除所有偶数行和偶数列。显而易见,结果图像只有原图的四分之一。
通过对输入图像  (原始图像) 不停迭代以上步骤就会得到整个金字塔。
(原始图像) 不停迭代以上步骤就会得到整个金字塔。
- 以上过程描述了对图像的向下采样,如何将图像变大呢?
首先,将图像在每个维度上扩大为原来的两倍,新增的行(偶数行)以0填充。再使用先前同样的内核(乘以4)与放大后的图像卷积,获得 “新增像素” 的近似值。
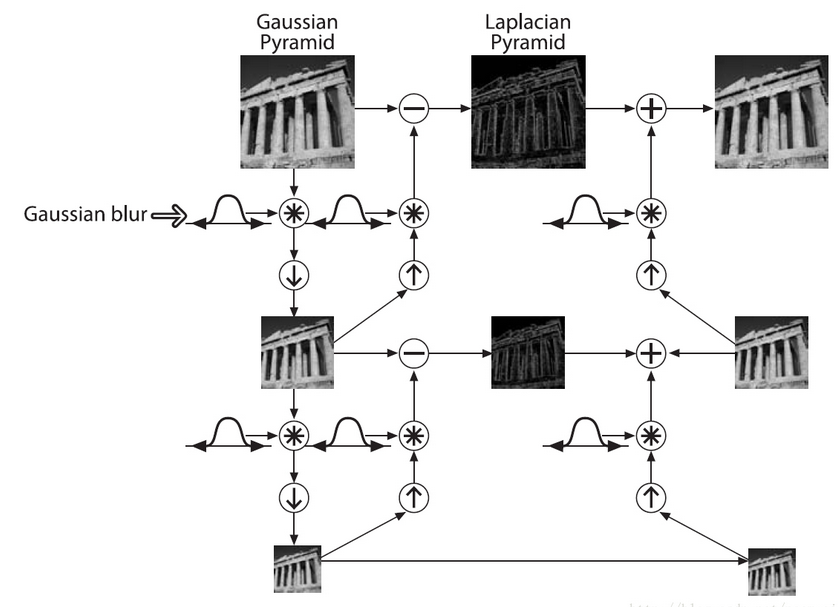
得到的图像即为放大后的图像,但是与原来的图像相比会发觉比较模糊,因为在缩放的过程中已经丢失了一些信息,如果想在缩小和放大整个过程中减少信息的丢失,这些数据形成了拉普拉斯金字塔。
这两个(向下和向上采样) 分别通过OpenCV函数pyrDown 和 pyrUp 实现。
Note:函数 pyrUp并不是函数pyrDown的逆操作。之所以这样,是因为pyrDown是一个会丢失信息的函数。
- 拉普拉斯金字塔:(高斯金字塔其逆形式)
是高斯金字塔的修正版,为了还原到原图,通过计算残差图来达到还原。下式是拉普拉斯金字塔第i层的数学定义:L(i)=G(i) - PyrUp(G(i+1));
将降采样之后的图像再进行上采样操作,然后与之前还没降采样的原图进行做差得到残差图,为还原图像做信息的准备。
- 另外再提一点,关于图像金字塔非常重要的一个应用就是实现图像分割。图像分割的话,先要建立一个图像金字塔,然后在G_i和G_i+1的像素直接依照对应的关系,建立起”父与子“关系。而快速初始分割可以先在金字塔高层的低分辨率图像上完成,然后逐层对分割加以优化。OpenCV函数 cvPyrSegmentation 实现。
高斯金字塔在SIFT中的应用 http://blog.csdn.net/alecsophia/article/details/17509195
SIFT(Scale-Invariant Feature Transform,尺度不变特征转换)在目标识别、图像配准领域具有广泛的应用,高斯金字塔是SIFT特征提取的第一步。
一.前言
[1]高斯金字塔
对于高斯金字塔,很容易直观地理解为对同一尺寸的图像,然后进行不同程度的高斯平滑(即高斯核模糊),这些图像构成高斯金字塔,这种是不对的,这描述的图像集合叫做一个八度。金字塔总要有个变“尖”的过程,真正的高斯金字塔要有个平滑以及下采样的过程,因此整个图像平滑以及下采样再平滑,构成的所有图像集合才构成了图像的高斯金字塔。
八度(octave) :简单地说八度就是在特定尺寸(长宽)下,经不同高斯核模糊的图像的集合。八度的集合是高斯金字塔,一般有4,5个octave应该就行。
[2]为什么要构建高斯金字塔
高斯金字塔模仿的是图像的不同的尺度,尺度应该怎样理解?对于一副图像,你近距离观察图像,与你在一米之外观察,看到的图像效果是不同的,前者比较清晰,后者比较模糊,前者比较大,后者比较小,通过前者能看到图像的一些细节信息,通过后者能看到图像的一些轮廓的信息,这就是图像的尺度,图像的尺度是自然存在的,并不是人为创造的。
好了,到这里我们明白了,其实以前对一幅图像的处理还是比较单调的,因为我们的关注点只落在二维空间,并没有考虑到“图像的纵深”这样一个概念,如果将这些内容考虑进去我们是不是会得到更多以前在二维空间中没有得到的信息呢?于是高斯金字塔横空出世了,它就是为了在二维图像的基础之上,榨取出图像中自然存在的另一个维度:尺度。因为高斯核是唯一的线性核,也就是说使用高斯核对图像模糊不会引入其他噪声,因此就选用了高斯核来构建图像的尺度。
下图两幅图像是典型的图像高斯金字塔,这就是模仿的图像离你远去时在你视网膜上的成像,图像分别以动态方式表示。

二.高斯金字塔的构建步骤
根据Lowe的论文,高斯金字塔的构建还是比较简单的,高斯卷积核是尺度变换的唯一的线性核。
高斯金字塔构建过程中,一般首先将图像扩大一倍,在扩大的图像的基础之上构建高斯金字塔,然后对该尺寸下图像进行高斯模糊,几幅模糊之后的图像集合构成了一个八度,然后对该八度下的最模糊的一幅图像进行下采样的过程,长和宽分别缩短一倍,图像面积变为原来四分之一。这幅图像就是下一个八度的初始图像,在初始图像图像的基础上完成属于这个八度的高斯模糊处理,以此类推完成整个算法所需要的所有八度构建,这样这个高斯金字塔就构建出来了。构建出的金字塔如下图所示:

三.尺度空间:
以上已经从人视觉感知的角度让大家感性认识了“尺度”,上文也提到使用高斯核来实现尺度的变换,那么具体实现过程中,尺度体现在哪里?是如何量化的呢?
在高斯金字塔中,两个变量很重要,即第几个八度(o)和八度中的第几层(s),这两个量合起来(o,s)就构成了高斯金字塔的尺度空间。尺度空间也不难理解,首先一个八度中图像的长和宽是相等的,即变量o控制的是塔中尺寸这个尺度;区分同一个尺寸尺度下的图像,就需要s了,s控制了一个八度中不同的模糊程度。这样(o,s)就能够确定高斯金字塔中的唯一一幅图像了,这是个三维空间,两维坐标,一维是图像。
根据lowe的论文,(o,s)作用于一幅图像是通过公式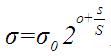 确定的。通过公式也可以看出,尺度空间是连续的,两个变量控制着δ的值,其中在第一个八度中有 1<(o+s/S)<=2 ,同理在第二个八度中有2<(o+s/S)<=3,以此类推,δ中的关键部分(o+s/S)部分是逐渐增大的(具体实现时,有些高斯金字塔中这个值是增大,但不是逐渐均匀增大,只能说是连续的)。
确定的。通过公式也可以看出,尺度空间是连续的,两个变量控制着δ的值,其中在第一个八度中有 1<(o+s/S)<=2 ,同理在第二个八度中有2<(o+s/S)<=3,以此类推,δ中的关键部分(o+s/S)部分是逐渐增大的(具体实现时,有些高斯金字塔中这个值是增大,但不是逐渐均匀增大,只能说是连续的)。
上图中第一个八度的中图像的尺度分别是δ,kδ,k^2δ......,第二个八度的尺度分别是2δ,2kδ,2k^2δ........,同理第三个八度的尺度分别是4δ,4kδ,4k^2δ........。这个序列是通过下式来确定的:
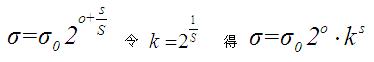
下图形象说明了什么是尺度空间:

四.构建差分高斯金字塔
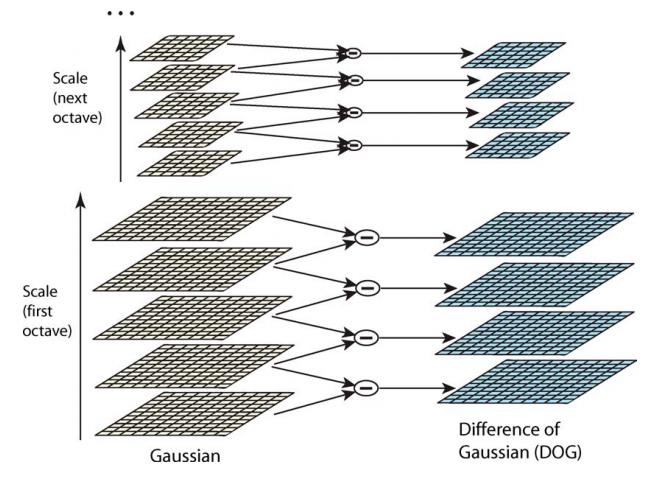
对同一个八度的两幅相邻的图像做差得到插值图像,所有八度的这些插值图像的集合,就构成了差分高斯金字塔。
过程如下图所示,差分高斯金字塔的好处是为后续的特征点的提取提供了方便。
五.尺度空间的连续性
在弄清楚这个问题之前,我们还需要解决一个问题,即为什么高斯金字塔中每个八度有s+3幅高斯图像?s的意思是将来我们在差分高斯金字塔中求极值点的时候,我们要在每个八度中求s层点,通过lowe论文可知,每一层极值点是在三维空间(图像二维,尺度一维)中比较获得,因此为了获得s层点,那么在差分高斯金字塔中需要有s+2图像,好了,继续上溯,如果差分高斯金字塔中有s+2幅图像,那么高斯金字塔中就必须要有s+3幅图像了,因为差分高斯金字塔是由高斯金字塔相邻两层相减得到的。好了,到了这里似乎真相大白,但是我们上面的推导有一个致命的问题,我们上来就假设“我们要在每个八度中求s层点”,为什么要s层点呢?这才是这个小节的主题:是为了保持尺度的连续性!下面进行详细的分析:
以一个八度中的图像为例说明,高斯金字塔和差分高斯金字塔那几个公式还要在这里贴出来一下:
高斯函数G对图像I的模糊函数:

高斯差分函数:

通过以上这两个公式,可以确定一个八度中(以第一个八度为例)高斯图像和差分高斯图像的尺度如下(以lowe论文为例,s=3,所以每个八度中会有3+3=6幅图像),每一幅图像的尺度也在图像标示了出来。

在lowe的论文中s=3,因此有

因此,根据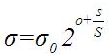 当前八度中各高斯图像的尺度依次为:σ,2^(1/3)σ, 2^(2/3)σ, 2^(3/3)σ, 2^(4/3)σ, 2^(5/3)σ;
当前八度中各高斯图像的尺度依次为:σ,2^(1/3)σ, 2^(2/3)σ, 2^(3/3)σ, 2^(4/3)σ, 2^(5/3)σ;
当前八度中各差分高斯图像的尺度依次为: σ,2^(1/3)σ, 2^(2/3)σ, 2^(3/3)σ, 2^(4/3)σ。
同理,我们可以推断出,下一个八度中各高斯图像的尺度依次为: 2×σ,2×2^(1/3)σ,2×2^(2/3)σ,2×2^(3/3)σ,2×2^(4/3)σ,2×2^(5/3)σ;
下一个八度中各差分高斯图像的尺度依次为: 2×σ,2×2^(1/3)σ,2×2^(2/3)σ,2×2^(3/3)σ,2×2^(4/3)σ。
可以观察到,其中红色标注数据所代表的层,是差分高斯金字塔中获得极值点的层,也就是说只有在这些层上才发生与上下两层比较获得极值点的操作。下面将这些红色数据连成一串:2^(1/3)σ, 2^(2/3)σ, 2^(3/3)σ,2×2^(1/3)σ,2×2^(2/3)σ,2×2^(3/3)σ......。发现了什么?对了,这些数据是连续的,我们通过在每个八度中多构造三幅高斯图像,达到了尺度空间连续的效果,这一效果带来的直接的好处是在尺度空间的极值点确定过程中,我们不会漏掉任何一个尺度上的极值点,而是能够综合考虑量化的尺度因子![]() 所确定的每一个尺度!
所确定的每一个尺度!
六.下一个八度的第一幅图像如何确定
这个问题,是上面问题(尺度空间的连续性)的延伸,当前八度中的第一幅图像是通过前一个八度的倒数第三幅图像得到。OpenCV这段源码有个很重要的问题:不同的八度间的尺度不是会有一个2的差异吗?为什么本部分源码并没有体现这一点,而是在对每一个八度处理中都是用相同的数组sig[]。首先明确一下sig数组内.存储的并不是一个绝对的模糊核,而是相对的模糊核,这一点很重要,既然是相对的模糊核,那么第一幅图像的核就很重要了,所以尺度的连续就看每个八度的第一幅图像了。
对于以下列出的高斯金字塔的构建过程来看,每个八度中的第一幅图像并没有一个2倍的尺度跃进过程。但是,这个2倍的跃进式隐含在整个高斯金字塔的构建过程中了!
再看倒数第三幅图像,这幅图像的尺度是2^(3/3)*δ,3/3=1,也就是说,在这个八度中,第一幅图像的尺度是δ,而倒数第三幅图像的尺度是2*δ,正好发生了一个2的跃进!这就是以这幅图像作为基准进行下采样的原因,如此的话,下一个八度的第一幅图像的初始尺度就是2*δ了。
这就是真相,这就是为什么选用倒数第三幅图像进行下采样的原因。
总体概括 https://www.zhihu.com/question/19911080/answer/72923486


英文Octave是音乐上一个八度的意思,在这里指的是一组图像,一般有4,5个octave应该就行。这一组图像的分辨率是相同的,但是采用了不同的高斯函数进行滤波,因此从模糊程度上看(或者说从关注的尺度上看)是有区别的,而不同组的图像具有不同的分辨率,在尺度上的差别就更大。
为什么已经使用了不同尺度的高斯函数进行滤波还需要引入高斯金字塔呢?这是因为SIFT算法希望能具有更高的尺度分辨率(也就是希望相邻尺度的变化比较精细),所以就需要有很多层。如果不用高斯金字塔,都在原始分辨率上靠采用不同的高斯函数实现多尺度检测,那么对于比较粗尺度的特征提取在计算量上就相当浪费。所以采用高斯金字塔是为了高效地提取不同尺度的特征。
不同octave之间的尺度差异靠高斯金字塔在分辨率上的区别实现,同一个octave内部不同层之间的尺度差异靠高斯函数的方差变化来实现。
另外SIFT在DOG问题上并不是使用DOG函数直接滤波,而是用相邻两层的高斯滤波结果相减得到的,为什么要这样呢?
也是为了节省计算量。因为如果直接采用DOG函数,为了提取不同的尺度,就必须逐渐扩大DOG函数的窗口,这会引起计算量的增加。