MapReduce的整个运行分为两个阶段: Map和Reduce
Map阶段由一定数量的Map Task组成
输入格式的数据格式化:InputFormat
数日数据的处理:Mapper
数据分组:Partitioner
下面流程图:
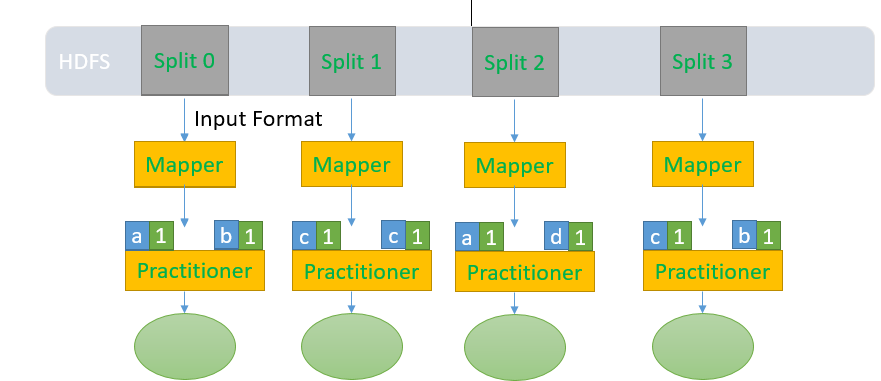
1. Map task 首先从HDFS上Read文件,通过Input Format把分件切分成一个一个的split.生成<Key,Value> key默认用行在文件中的偏移量
2.对每一个split块执行Map操作
3.
4. Maper的<Key,Value>输出到Reducer段
Redue阶段由一定数量的Reduce Task 组成
数据的远程COPY
数据按Key排序
数据处理:Reducer
数据输出格式: OutputFormat
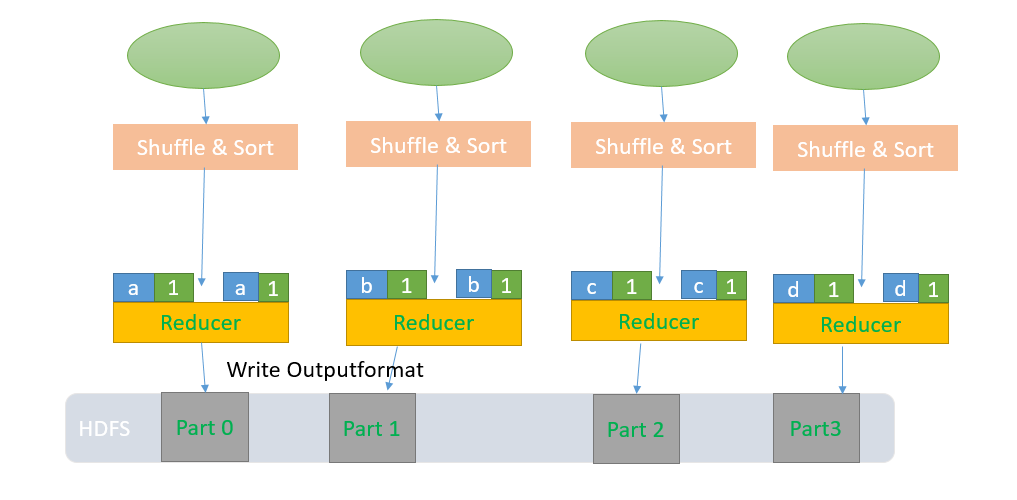
1. 拿到Mapper的ouput作为Input
2. 把patitiioner的结果远程copy到本地
3. Shffle & Sort操作。
4. Reducer操作
5.输出