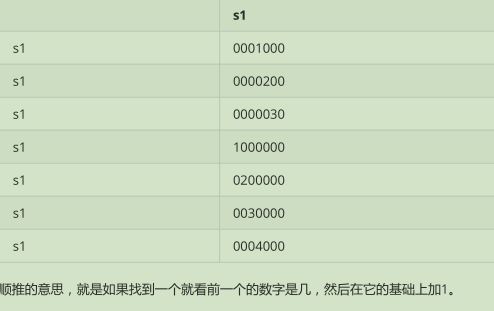
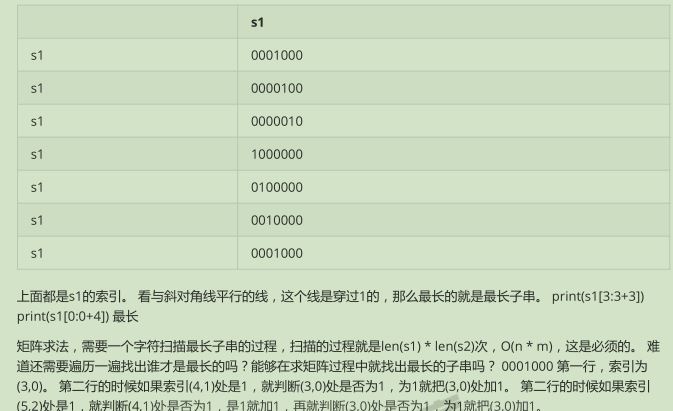
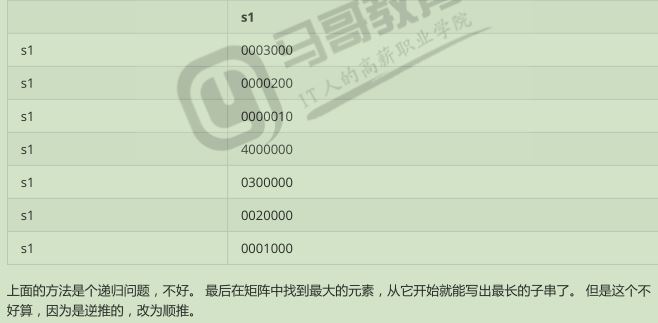
1 s1 = 'abcdefg' 2 s2 = 'defabcd' 3 s2 = 'qdefabd' 4 5 # 方法一 :矩阵算法:后面有介绍。可以私聊我 6 7 def findit(s1, s2): 8 if len(s2) > len(s1): # 从s2 中找 ,用s2 去对比 9 s1, s2 = s2, s1 10 xmax = 0 11 xindex = 0 12 martix = [[0] * len(s1) for _ in range(len(s2))] 13 14 15 for i,x in enumerate(s2):# 拿s2 中的去s1 中比较 16 for j, y in enumerate(s1): 17 if x != y: 18 pass 19 else:# 两个字符相同在做处理 20 if i == 0 or j == 0: #边界上,只能是 1 21 martix[i][j] = 1 22 else: 23 martix[i][j] = martix[i-1][j-1] + 1 # 前一轮,左上角 24 #每轮记录最大值 25 if martix[i][j] > xmax: 26 xmax = martix[i][j] # 记录最大值,用于下次比较 27 xindex = j 28 print(martix) 29 start = xindex + 1 - xmax # 切片的起始点索引 30 end = xindex + 1 31 print(xmax, xindex, s1[start:end]) 32 33 findit(s1, s2) 34 35 36 37 # 利用切片方式: 38 39 s1 = 'defpabc' 40 s2 = 'defdefmabcabcdabc' 41 # s2 = 'qdefabd' 42 43 def findit(s1, s2): 44 if len(s2) < len(s1): # 从s2 中找 ,用s2 去对比 45 s1, s2 = s2, s1 46 47 length = len(s1) 48 maxlen = 0 49 for sublen in range(length, 0, -1):# 倒着,从长到短 50 for start in range(0, length - sublen +1):# 在s2 中起始位置,最长到 length-suben + 1 51 substr = s1[start:start+sublen] 52 53 # 有缺点 54 # if s2.find(substr) > -1: 55 # # print(substr) 56 # return substr # 缺点:只能输出第一次遇到的子串 57 58 # 修改 59 if s2.find(substr) > -1: 60 if len(substr) >= maxlen: 61 maxlen = len(substr) # 记录如果大于,则记录下,以便下次来了在比较 62 print(substr) 63 64 findit(s1, s2) 65 66 # 我自己写的, 67 # 思路是,从左往右,不断缩小,第一次 定第一个字母,从后往前找,第二次,定第二个字母,从后往前找,以此类推,遇到相同的记录,同时记录这次 68 # 的长度,下次比较这个长度 ,比这个长度短的就不用再比较了 69 s1 = 'abcdeg' # abcdef 70 s1 = 'a1b' # abcdef 71 s1 = 'a1bc1doddddde1fff1g' # abcdef 72 s2 = 'defabcdoabcdeftw' #abcdef 73 74 length = len(s1) 75 lens = {} 76 max_num = 0 77 78 for i in range(length): 79 for j in range(length, i, -1): 80 if s1[i:j] in s2 and len(s1[i:j]) >= max_num: 81 lens[s1[i:j]] = lens.get(s1[i:j], 0) + len(s1[i:j]) 82 max_num = len(s1[i:j]) 83 84 for i in sorted(lens): 85 if len(i) == max_num: 86 print(i)
通过图片可以理解: