- JavaScript高级程序设计 - 读书笔记 by JerryChan
JavaScript高级程序设计 - 读书笔记 by JerryChan
第2章 在HTML中嵌入JavaScript
2.5 小结
-
把JavaScript插入到HTML页面中要使用
<script>元素。使用这个元素可以把JavaScript嵌入到HTML页面中,让脚本与标记混合在一起;也可以包含外部的JavaScript文件。而我们需要注意的地方有:- 在包含外部JavaScript文件时,必须将src属性设置为指向相应文件 的 URL。而这个文件既可以是与包含它的页面位于同一个服务器上的文件,也可以是其他任何域中的文件。
- 所有
<script>元素都会按照它们在页面中出现的先后顺序依次被解析。在不使用defer和async属性的情况下,只有在解析完前面<script>元素中的代码之后,才会开始解析后面<script>元素中的代码。 - 由于浏览器会先解析完不使用defer属性的
<script>元素中的代码,然后再解析后面的内容,所以一般应该把<script>元素放在页面最后,即主要内容后面,</body>标签前面。 - 使用defer属性可以让脚本在文档完全呈现之后再执行。延迟脚本总是按照指定它们的顺序执行。
- 使用async属性可以表示当前脚本不必等待其他脚本,也不必阻塞文档呈现。不能保证异步脚本按照它们在页面中出现的顺序执行。
-
另外,使用
<noscript>元素可以指定在不支持脚本的浏览器中显示的替代内容。但在启用了脚本的情况下,浏览器不会显示<noscript>元素中的任何内容。
第3章 基本概念
3.1.4 严格模式
-
ECMAScript 5引入了严格模式(strictmode)的概念。严格模式是为JavaScript定义了一种不同的解析与执行模型。在严格模式下,ECMAScript 3中的一些不确定的行为将得到处理,而且对某些不安全的操作也会抛出错误。要在整个脚本中启用严格模式,可以在顶部添加如下代码:
"use strict";
-
在函数内部的上方包含这条编译指示,也可以指定函数在严格模式下执行:
functiondoSomething(){ "usestrict"; //函数体 }
严格模式是一个编译指示,目的是为了兼容 ECMAScript 3语法。
3.3 变量
- 虽然省略
var操作符可以定义全局变量,但这也不是我们推荐的做法。因为在局部作用域中定义的全局变量很难维护,而且如果有意地忽略了var操作符,也会由于相应变量不会马上就有定义而导致不必要的混乱。给未经声明的变量赋值在严格模式下会导致抛出ReferenceError错误。
省略
var可声明全局变量,但不推荐使用。
3.4 数据类型
- ECMAScript中有5种简单数据类型(也称为基本数据类型):Undefined、Null、Boolean、Number和String。
使用操作符typeof可以检测变量的数据类型。
3.4.3 Null类型
-
实际上,undefined值是派生自null值的,因此ECMA-262规定对它们的相等性测试要返回true:
alert(null == undefined); //true
-
无论在什么情况下都没有必要把一个变量的值显式地设置为undefined,可是同样的规则对null却不适用。换句话说,只要意在保存对象的变量还没有真正保存对象,就应该明确地让该变量保存null值。这样做不仅可以体现null作为空对象指针的惯例,而且也有助于进一步区分null和undefined。
3.4.4 Boolean类型
- 可以对任何数据类型的值调用Boolean()函数,而且总会返回一个Boolean值。至于返回的这个值是true还是false,取决于要转换值的数据类型及其实际值。下表给出了各种数据类型及其对应的转换规则。
| 数据类型 | 转换为true的值 | 转换为false的值 |
|---|---|---|
| Boolean | true | false |
| String | 任何非空字符串 | ""(空字符串) |
| Number | 任何非零数字值(包括无穷大) | 0和NaN(参见本章后面有关NaN的内容) |
| Object | 任何对象 | bull |
| Undefined | n/a | undefined |
n/a(或N/A),是notapplicable的缩写,意思是“不适用”。
3.4.5 Number类型
八进制字面量在严格模式下是无效的,会导致支持的JavaScript引擎抛出错误。在进行算术计算时,所有以八进制和十六进制表示的数值最终都将被转换成十进制数值。
-
浮点数值的最高精度是17位小数,但在进行算术计算时其精确度远远不如整数。例如,0.1加0.2的结果不是0.3,而是0.30000000000000004。这个小小的舍入误差会导致无法测试特定的浮点数值。例如:
if(a + b == 0.3){ //不要做这样的测试! alert("You got 0.3."); }
永远不要测试某个特定的浮点数值。这是使用基于IEEE754数值的浮点计算的通病。
-
由于内存的限制,ECMAScript并不能保存世界上所有的数值。ECMAScript能够表示的最小数值保存在Number.MIN_VALUE中——在大多数浏览器中,这个值是5e-324;能够表示的最大数值保存在Number.MAX_VALUE中——在大多数浏览器中,这个值是1.7976931348623157e+308。如果某次计算的结果得到了一个超出JavaScript数值范围的值,那么这个数值将被自动转换成Infinity值。具体来说,如果这个数值是负数,则会被转换成-Infinity(负无穷),如果这个数值是正数,则会被转换成Infinity(正无穷)。
-
NaN,即非数值(NotaNumber)是一个特殊的数值,这个数值用于表示一个本来要返回数值的操作数未返回数值的情况(这样就不会抛出错误了)。NaN有两个特点。首先,任何涉及NaN的操作(例如NaN/10)都会返回NaN,这个特点在多步计算中有可能导致问题。其次,NaN与任何值都不相等,包括NaN本身。例如,下面的代码会返回false:
alert(NaN == NaN); //false -
针对NaN的这两个特点,ECMAScript定义了isNaN()函数。这个函数接受一个参数,该参数可以是任何类型,而函数会帮我们确定这个参数是否“不是数值”。例如:
alert(isNaN(NaN)); //true alert(isNaN(10)); //false(10是一个数值) alert(isNaN("10")); //false(可以被转换成数值10) alert(isNaN("blue"));//true(不能转换成数值) alert(isNaN(true)); //false(可以被转换成数值1)
使用parseInt()进行转换时,应当在第二个参数指定基数。
3.4.6 String类型
- 在不知道要转换的值是不是是不是null或undefined的情况下,还可以使用转型函数String(),这个函数能够将任何类型的值转换为字符串。String()函数遵循下列转换规则:
- 如果值有toString()方法,则调用该方法(没有参数)并返回相应的结果;
- 如果值是null,则返回"null";
- 如果值是undefined,则返回"undefined"。
3.4.7 Object类型
-
仅仅创建Object的实例并没有什么用处,但关键是要理解一个重要的思想:即在ECMAScript中,(就像Java中的java.lang.Object对象一样)Object类型是所有它的实例的基础。换句话说,Object类型所具有的任何属性和方法也同样存在于更具体的对象中。
-
Object的每个实例都具有下列属性和方法。
- Constructor:保存着用于创建当前对象的函数。
- hasOwnProperty(propertyName):用于检查给定的属性在当前对象实例中(而不是在实例的原型中)是否存在。其中,作为参数的属性名(propertyName)必须以字符串形式指定(例如:o.hasOwnProperty("name"))。
- isPrototypeOf(object):用于检查传入的对象是否是另一个对象的原型。
- propertyIsEnumerable(propertyName):用于检查给定的属性是否能够使用for-in语句来枚举。
- toLocaleString():返回对象的字符串表示,该字符串与执行环境的地区对应。
- toString():返回对象的字符串表示。
- valueOf():返回对象的字符串、数值或布尔值表示。通常与toString()方法的返回值相同。
3.5 操作符
- 左移/右移(<</>>):以符号位填充。
- 无符号左移/右移(<<</>>>):以0填充。负数会变成无符号数(出现大整数的错误结果)。
- 在涉及Infinity、-Infinity、NaN等数值的运算时要倍加小心。
- 字符串比较时,比较的是字符编码(如
B>a为真,"23" < "3"为真),最好避免隐式转换。 - 尽量使用全等
===和不全等!==操作符,避免隐式转换带来的问题。
3.6 语句
- with语句:大量使用with语句会导致性能下降,同时也会给调试代码造成困难,因此在开发大型应用程序时,不建议使用with语句。
- for-in语句:用于枚举对象的所有属性。
3.7 函数
-
关于返回值:推荐的做法是要么让函数始终都返回一个值,要么永远都不要返回值。否则,如果函数有时候返回值,有时候有不返回值,会给调试代码带来不便。
-
严格模式对函数有一些限制:
- 不能把函数命名为eval或arguments;
- 不能把参数命名为eval或arguments;
- 不能出现两个命名参数同名的情况。
对参数的理解
- ECMAScript函数的参数与大多数其他语言中函数的参数有所不同。ECMAScript函数不介意传递进来多少个参数,也不在乎传进来参数是什么数据类型。也就是说,即便你定义的函数只接收两个参数,在调用这个函数时也未必一定要传递两个参数。可以传递一个、三个甚至不传递参数,而解析器永远不会有什么怨言。之所以会这样,原因是ECMAScript中的参数在内部是用一个数组来表示的。函数接收到的始终都是这个数组,而不关心数组中包含哪些参数(如果有参数的话)。如果这个数组中不包含任何元素,无所谓;如果包含多个元素,也没有问题。实际上,在函数体内可以通过
arguments对象来访问这个参数数组,从而获取传递给函数的每一个参数。
其实,
arguments对象只是与数组类似(它并不是Array的实例),因为可以使用方括号语法访问它的每一个元素(即第一个元素是arguments[0],第二个元素是arguments[1],以此类推),使用length属性来确定传递进来多少个参数。ECMAScript不支持重载,但利用这一属性,可以模仿方法的重载。
function sayHi() {
alert("Hello" + arguments[0] + "," + arguments[1]);
}
这个重写后的函数中不包含命名的参数。虽然没有使用name和message标识符,但函数的功能依旧。这个事实说明了ECMAScript函数的一个重要特点:命名的参数只提供便利,但不是必需的。
第4章 变量、作用域和内存问题
4.1 基本类型和引用类型的值
-
第3章讨论了5种基本数据类型:Undefined、Null、Boolean、Number和String。这5种基本数据类型是按值访问的,因为可以操作保存在变量中的实际的值。
-
引用类型的值是保存在内存中的对象(Object)。与其他语言不同,JavaScript不允许直接访问内存中的位置,也就是说不能直接操作对象的内存空间。在操作对象时,实际上是在操作对象的引用而不是实际的对象。为此,引用类型的值是按引用访问的。
思考:
function setName( obj) {
obj. name = "Nicholas";
obj = new Object();
obj.name = "Greg";
}
var person = new Object();
setName( person);
alert( person. name); //"Nicholas"
//函数结束后,函数内创建的引用被销毁,只有对原引用的修改生效。
-
类型检测:判断基本数据类型使用typeof,判断对象类型用instanceof。
alert( person instanceof Object);
4.2 执行环境和作用域
- JavaScript没有块级作用域,函数是最小的执行环境。执行环境是其中声明变量的作用域。
4.3 垃圾收集
- 大多数现代浏览器在变量离开执行环境时就会进行内存清除工作。
- 频繁调用垃圾收集会产生性能问题(不建议使用
window. CollectGarbage()或类似的函数)。 - 优化内存占用的方式:
- 一旦数据不再有用,将其值设置为
null,即解引用(主要针对全局变量)。 - 局部变量离开执行环境时会被自动解引用。
- 一旦数据不再有用,将其值设置为
第五章 引用类型
5.2 Array类型
- length属性并非只读,可以通过length修改长度。
- 检测对象是否Array:
- 如果使用instanceof操作符,在包含多个全局执行环境的情况下可能出错。
- 应使用isArray()。
- Array提供了栈、队列、排序、连接、查找等方法。重点掌握:
-
splice():基于当前数组的一个或多个项创建数组。var colors = ["red", "green", "blue", "yellow", "purple"]; var colors2 = colors. slice( 1); var colors3 = colors. slice( 1, 4); alert( colors2); //green, blue, yellow, purple alert( colors3); //green, blue, yellow -
splice():对数组指定项执行删除/插入/替换操作。array.splice(start[, deleteCount[, item1[, item2[, ...]]]]) // start:开始位置 deleteCount:删除项的数量 item1...:插入的项 -
迭代方法:
every(),forEach(),filter(),map(),some()
传入的参数为迭代函数,该函数接受item, index, array三个量。var numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; var everyResult = numbers.every(function(item, index, array){ return (item > 2); }); alert( everyResult); -
缩小方法:
reduce(), reduceRight()与上类似,常用于累加等操作。
-
5.3 Date类型
- 创建Date对象:
- 无参数:取当前日期和时间
- 使用
Date.parse("datestring")作为参数:注意非法日期返回值 - 使用
Date.UTC(year,month,day,hrs,min,sec,msec)作为参数(月份从0开始)
- 继承的方法:
toString()和toLocaleString()有格式差别。valueOf()返回日期的毫秒表示。
5.4 RegExp类型
- 三种标志:
- g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止;
- i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写;
- m:表示多行(multiline)模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项。
- 两种构建形式:
- 使用字面量构建:
var pattern1 = /[bc]at/i; - 使用RegExp构造函数构建:
var pattern2 = new RegExp("[bc]at", "i"); - 使用RegExp构造函数,转义字符需要双重转义。
- 使用字面量构建:
5.5 Function类型
- 没有重载
- 内部属性:
arguments和thisarguments有callee属性,该指针指向拥有该arguments的函数。callee属性用于函数递归可以降低函数的耦合程度。this引用的是函数据以执行的环境对象。- 函数有
caller属性,该指针指向调用该当前函数的引用。
- 函数属性:
length和prototypelength定义了函数希望接受的命名参数的个数。prototype与函数继承的实现有关,之后详述。
- 函数方法:
apply()和call()-
apply()相当于设置函数体内this对象的值。function sum(num1, num2){ return num1 + num2; } function callSum1(num1,num2){ return sum.apply( this, arguments); //传入arguments对象 } function callSum2(num1, num2){ return sum.apply( this, [num1, num2]); // 传入数组 } alert( callSum1( 10, 10)); //20 alert( callSum2( 10, 10)); //20 -
call()与apply()作用相同,但传递参数的方式不同。function sum(num1, num2){ return num1 + num2; } function callSum(num1, num2){ return sum. call( this, num1, num2); } alert( callSum( 10, 10)); //20 -
apply()和call()真正强大的地方是能够扩充函数赖以运行的作用域。使用call()或apply()来扩充作用域的最大最大好处,就是对象不需要与方法有任何耦合关系。 -
ECMAScript 5还定义了一个方法:
bind()。这个方法会创建一个函数的实例,其this值会被绑定到传给bind()函数的值。window. color = "red"; var o = { color: "blue" }; function sayColor(){ alert(this. color); } var objectSayColor = sayColor. bind(o); objectSayColor(); //blue
-
5.6 基本包装类型
-
为了便于操作基本类型值,ECMAScript还提供了3个特殊的引用类型:Boolean、Number和String。每当读取一个基本类型值的时候,后台就会创建一个对应的基本包装类型的对象,从而让我们能够调用一些方法来操作这些数据。如String的
substring()方法等。 -
实际处理过程如下:
-
创建String类型的一个实例;
-
在实例上调用指定的方法;
-
销毁这个实例。
思考: var s1 = "some text"; s1. color = "red"; alert(s1.color); //undefined. why?
-
-
实践中永远不使用Boolean对象
第六章 面向对象的程序设计
6.2 创建对象
ECMAScript 通过原型来实现面向对象的程序设计,而非类或接口。
- 不推荐在产品化的程序中修改原生对象的原型。如果因某个实现中缺少某个方法,就在原生对象的原型中添加这个方法,那么当在另一个支持该方法的实现中运行代码时,就可能会导致命名冲突。而且,这样做也可能会意外地重写原生方法。
原型模式的问题:对于包含引用类型属性的类而言,修改其中一个对象的引用类型属性会导致其他共享同一原型的对象也发生变化。
例:person1,person2共享同一原型,原型包含Array类型的friend属性,执行person1.friend.push_back("Jacob"); alert(person2.friend); // Jacob
-
创建自定义类型的最常见方式,就是组合使用构造函数模式与原型模式。构造函数模式用于定义实例属性,而原型模式用于定义方法和共享的属性。例:
function Person( name, age, job){ this. name = name; this. age = age; this. job = job; this. friends = ["Shelby", "Court"]; } Person. prototype = { constructor : Person, sayName : function(){ alert( this. name); } }
其他创建方式:动态原型模式、寄生构造函数模式、稳妥构造函数模式(需要时查询)。
6.3 继承
-
JavaScript使用原型链实现继承,其本质是重写原型对象,代之以一个新类型的示例。
-
当以读取模式访问一个实例属性时,首先会在实例中搜索该属性。如果没有找到该属性,则会继续搜索实例的原型。在通过原型链实现继承的情况下,搜索过程就得以沿着原型链继续向上。在找不到属性或方法的情况下,搜索过程总是要一环一环地前行到原型链末端才会停下来。
-
可以通过两种方式来确定原型和实例之间的关系。第一种方式是使用
instanceof操作符,第二种方式是使用isPrototypeOf()方法。 -
原型链的第二个问题是:在创建子类型的实例时,不能向超类型的构造函数中传递参数。实际上,应该说是没有办法在不影响所有对象实例的情况下,给超类型的构造函数传递参数。
-
继承方式:最常用的是组合继承,指的是将原型链和借用构造函数的技术组合到一块,从而发挥二者之长的一种继承模式。其背后的思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。例:
//组合使用构造函数模式和原型模式 function SuperType(name){ this. name = name; this. colors = ["red", "blue", "green"]; } SuperType.prototype.sayName = function(){ alert( this. name); }; function SubType(name, age){ //继承属性 SuperType.call(this, name); this. age = age; } //继承方法 SubType.prototype = new SuperType(); SubType.prototype.sayAge = function(){ alert( this. age); }; var instance1 = new SubType(" Nicholas", 29); instance1. colors. push("black"); alert( instance1. colors); //"red, blue, green, black" instance1. sayName(); //"Nicholas"; instance1. sayAge(); //29 var instance2 = new SubType(" Greg", 27); alert( instance2. colors); //"red, blue, green" instance2. sayName(); //"Greg"; instance2. sayAge(); //27
第7章 函数表达式
- 关于函数声明:函数声明提升:是在执行代码之前会先读取函数声明。这就意味着可以把函数声明放在调用它的语句后面。
7.1 递归实现
-
使用arguments.callee
-
在严格模式下不能通过脚本访问arguments.callee,则可以使用匿名函数。如:
var factorial = (function f(num){ if (num <= 1){ return 1; } else { return num * f(num- 1); } });
7.2 闭包
-
闭包是指有权访问另一个函数作用域中的变量的函数。创建闭包的常见方式,就是在一个函数内部创建另一个函数。
-
在匿名函数从上一级函数中被返回后,它的作用域链被初始化为包含上一级函数的活动对象和全局变量对象。这样,匿名函数就可以访问在上一级函数中定义的所有变量。
-
更为重要的是,上一级函数在执行完毕后,其活动对象也不会被销毁,因为匿名函数的作用域链仍然在引用这个活动对象。换句话说,当上一级函数返回后,其执行环境的作用域链会被销毁,但它的活动对象仍然会留在内存中;直到匿名函数被销毁后,上级函数的活动对象才会被销毁。
过度使用闭包会导致内存占用过多,请只在绝对必要时考虑使用闭包。
-
作用域链的副作用:闭包只能取得包含函数中任何变量的最后一个值。例如:
function createFunctions(){ var result = new Array(); for (var i= 0; i < 10; i++){ result[ i] = function(){ return i; }; } return result; } // 执行 var a = createFunctions(); a[0](); // 10 -
原因:result中每一项都是匿名函数,这些匿名函数返回了
createFunctions()中声明的i。createF1unctions()运行结束时,i的值为10,由于因此调用所有的匿名函数返回的值都是10。另外,这些匿名函数不销毁,createFunctions()中的变量也不会释放。 -
解决办法:创建另一个匿名函数,并传入对应的参数。
function createFunctions(){ var result = new Array(); for (var i = 0; i < 10; i++){ result[i] = function(num){ return function(){ return num; }; }(i); } return result; } -
this对象的问题:匿名函数的执行环境具有全局性,因此其this对象通常指向window。
-
解决办法:使用闭包,可以让匿名函数的this对象指向特定的对象。例如:
var object = { name : "My Object", getNameFunc : function(){ var that = this; return function(){ return that. name; }; } }; alert( object. getNameFunc()()); //"My Object" -
使用
that获取目标对象的this,然后在匿名函数使用that。
7.3 块级作用域
-
使用匿名函数模拟块级作用域:
(function(){ //这里是块级作用域 })(); // or var someFunction = function(){ //这里是块级作用域}; someFunction(); -
ECMAScript6以上的版本,使用
let取代var来声明变量,即可实现块级作用域变量的声明。
7.4 私有变量
- 严格来讲,JavaScript中没有私有成员的概念;所有对象属性都是公有的。不过,倒是有一个私有变量的概念。任何在函数中定义的变量,都可以认为是私有变量,因为不能在函数的外部访问这些变量。私有变量包括函数的参数、局部变量和在函数内部定义的其他函数。
简单来说就是通过作用域链的特性来隐藏不应该被直接修改的数据,例如:
function Person(name){
this. getName = function(){
return name;
};
this. setName = function (value) {
name = value;
};
}
var person = new Person(" Nicholas");
alert( person. getName()); //"Nicholas"
person. setName(" Greg");
alert( person. getName()); //"Greg"
此外还支持使用闭包来实现单例模式,需要时浏览 7.4.3 模块模式。
第8章 BOM
8.1 window对象
-
window对象也是ECMAScript的global对象,全局作用域中的变量、函数都会变成window对象的属性和方法。通过查询window对象,可以知道某个可能未声明的变量是否存在,例如:
//这里会抛出错误,因为oldValue未定义 var newValue = oldValue; //这里不会抛出错误,因为这是一次属性查询 //newValue的值是undefined var newValue = window. oldValue;
8.1.6 超时调用和间歇调用
- 一般认为,使用超时调用来模拟间歇调用的是一种最佳模式。在开发环境下,很少使用真正的间歇调用,原因是后一个间歇调用可能会在前一个间歇调用结束之前启动。而像前面示例中那样使用超时调用,则完全可以避免这一点。所以,最好不要使用间歇调用。
本章个人认为不是重点。
第9章 客户端检测
9.1 能力检测
-
最常用也最为人们广泛接受的客户端检测形式是能力检测(又称特性检测)。能力检测的目标不是识别特定的浏览器,而是识别浏览器的能力。采用这种方式不必顾及特定的浏览器如何如何,只要确定浏览器支持特定的能力,就可以给出解决方案。
-
要理解能力检测,首先必须理解两个重要的概念。如前所述,第一个概念就是先检测达成目的的最常用的特性。对前面的例子来说,就是要先检测document.getElementById(),后检测document.all。先检测最常用的特性可以保证代码最优化,因为在多数情况下都可以避免测试多个条件。第二个重要的概念就是必须测试实际要用到的特性。一个特性存在,不一定意味着另一个特性也存在。即:不要通过一个特性是否存在来判断浏览器类型。
-
一般来说,使用
typeof操作符来进行能力检测(判断方法是不是函数),但因为typeof在IE中存在行为不标准的情况,因此建议使用下面的函数来测试任何对象的某个特性是否存在://作者: Peter Michaux function isHostMethod(object, property) { var t = typeof object[property]; return t==' function' || (!!(t==' object' && object[property])) || t==' unknown'; }
9.2 怪癖检测
- 与能力检测类似,怪癖检测(quirksdetection)的目标是识别浏览器的特殊行为。但与能力检测确认浏览器支持什么能力不同,怪癖检测是想要知道浏览器存在什么缺陷(“怪癖”也就是bug)。一般来说,“怪癖”都是个别浏览器所独有的,且通常被归为bug。
建议仅检测那些对你有直接影响的“怪癖”,而且最好在脚本一开始就执行此类检测,以便尽早解决问题。
第10章 DOM
-
本章主要讲述什么是DOM,如何用Javascript访问、操作DOM。上课已经涉及,此部分略读。
-
DOM由各种节点构成,简要总结如下。
- 最基本的节点类型是Node,用于抽象地表示文档中一个独立的部分;所有其他类型都继承自Node。
- Document类型表示整个文档,是一组分层节点的根节点。在JavaScript中,document对象是Document的一个实例。使用document对象,有很多种方式可以查询和取得节点。
- Element节点表示文档中的所有HTML或XML元素,可以用来操作这些元素的内容和特性。
- 另外还有一些节点类型,分别表示文本内容、注释、文档类型、CDATA区域和文档片段。
-
理解DOM的关键,就是理解DOM对性能的影响。DOM操作往往是JavaScript程序中开销最大的部分,而因访问NodeList导致的问题为最多。NodeList对象都是“动态的”,这就意味着每次访问NodeList对象,都会运行一次查询。有鉴于此,最好的办法就是尽量减少DOM操作。
第11章 DOM扩展
- 对DOM的两种主要扩展:Selectors API和HTML5
11.1 Selectors API
- 根据CSS选择符选择与某个模式匹配的DOM元素。jQuery的核心就是通过CSS选择符查询DOM文档取得元素的引用,从而抛开
getElementById()和getElementByTagName()。 - Selectors API是W3C开发制定的一个标准,致力于让浏览器原生支持CSS查询,从而改善性能。
- Selectors API Level 1 的核心是两个方法:
querySelector()和querySelectorAll()。在兼容的浏览器中,可以通过Document及Element类型的实例调用它们。
11.1.1 querySelector()
-
querySelector()方法接收一个CSS选择符,返回与该模式匹配的第一个元素,如果没有找到匹配的元素,返回null。例://取得body元素 var body = document.querySelector(" body"); //取得ID为"myDiv"的元素 var myDiv = document.querySelector("# myDiv"); //取得类为"selected"的第一个元素 var selected = document.querySelector(". selected"); -
通过Doument类型调用
querySelector()方法时,会在文档元素的范围内查找匹配的元素。而通过Element类型调用querySelector()方法时,只会在该元素后代元素的范围内查找匹配的元素。
11.1.2 querySelectorAll()
-
querySelectorAll()同样接受CSS选择符,但返回匹配该选择符的所有元素(一个NodeList实例)。如果没有匹配的元素,NodeList为空。取得这些元素可以通过item()方法,也可以使用方括号访问。 -
与
querySelector()类似,能够调用querySelectorAll()方法的类型包括Document、DocumentFragment和Element。
11.2 元素遍历
-
对于元素间的空格,IE9及之前版本不会返回文本节点,而其他所有浏览器都会返回文本节点。这样,就导致了在使用childNodes和firstChild等属性时的行为不一致。为了弥补这一差异,而同时又保持DOM规范不变,ElementTraversal规范新定义了一组属性。
-
Element Traversal API 为DOM元素添加了以下5个属性。
- childElementCount:返回子元素(不包括文本节点和注释)的个数。
- firstElementChild:指向第一个子元素;firstChild的元素版。
- lastElementChild:指向最后一个子元素;lastChild的元素版。
- previousElementSibling:指向前一个同辈元素;previousSibling的元素版。
- nextElementSibling:指向后一个同辈元素;nextSibling的元素版。
11.3 HTML5
- 因为HTML5涉及的面非常广,本节只讨论与DOM节点相关的内容。HTML5的其他相关内容将在本书其他章节中穿插介绍。
11.3.1 与类相关的扩充
getElementByClassName():返回带有指定类的所有元素的NodeList,只有位于调用元素子树中的元素才会返回。- classList属性:方便管理元素的class属性(原来是字符串,修改字符串相对不方便)。使用classList属性的
add(value), contains(value), remove(value), toggle(value)即可非常方便地管理class属性。
11.3.2 焦点管理
- 相关方法和属性:
focus():获得焦点,document.activeElement:获取document中的焦点元素,hasFocus()判断元素是否获得焦点。
11.3.3 HTMLDocument的变化
readyState属性:使用document.readyState来确认文档是否已经加载完。- 插入标记:
- innerHTML:DOM子树,可读可写。并不是所有元素都支持innerHTML属性。不支持innerHTML的元素有:
<col>、<colgroup>、<frameset>、<head>、<html>、<style>、<table>、<tbody>、<thead>、<tfoot>和<tr>。此外,在IE8及更早版本中,<title>元素也没有innerHTML属性。 - outerHTML:返回元素自身及其子树,可读可写。支持outerHTML属性的浏览器有IE4+、Safari4+、Chrome和Opera8+。Firefox7及之前版本都不支持outerHTML属性。
- insertAdjacentHTML():第一个参数必须为下列参数之一,第二个参数为要插入的元素。
- "beforebegin",在当前元素之前插入一个紧邻的同辈元素;
- "afterbegin",在当前元素之下插入一个新的子元素或在第一个子元素之前再插入新的子元素;
- "beforeend",在当前元素之下插入一个新的子元素或在最后一个子元素之后再插入新的子元素;
- "afterend",在当前元素之后插入一个紧邻的同辈元素。
- 性能问题:在使用上述插入标记时,最好先手工删除要被替换的元素的所有事件处理程序和JavaScript对象属性(会有内存占用问题);尽量减少赋值次数,修改DOM耗费大量性能。
- innerHTML:DOM子树,可读可写。并不是所有元素都支持innerHTML属性。不支持innerHTML的元素有:
scrollIntoView()方法:可以在所有HTML元素上调用。传入true或不传参数时,该元素会通过滚动尽量出现在窗口顶部,传入false时,该元素会通过滚动尽量出现在窗口底部。
11.4 专有扩展
11.4.2 children属性
- 由于IE9之前的版本与其他浏览器在处理文本节点中的空白符时有差异,因此就出现了children属性。children属性只包含元素子节点,而childNodes则包含节点之间的空白符。
11.4.3 contains()方法
-
判断某个节点是不是另一个节点的后代,调用方法:
ancestorElement.contains(childElement);支持contains()方法的浏览器有IE、Firefox9+、Safari、Opera和Chrome。 -
使用DOMLevel3的
compareDocumentPosition()也能够确定节点间的关系。支持这个方法的浏览器有IE9+、Firefox、Safari、Opera9.5+和Chrome。如前所述,这个方法用于确定两个节点间的关系,返回一个表示该关系的位掩码(bitmask)。下表列出了这个位掩码的值。掩码 节点关系 1 无关(给定的节点不在当前文档中) 2 居前(给定的节点在DOM树中位于参考节点之前) 4 居后(给定的节点在DOM树中位于参考节点之后) 8 包含(给定的节点是参考节点的祖先) 16 被包含(给定的节点是参考节点的后代)
第12章 DOM2和DOM3
- 涉及较多目前不熟悉的知识,打算另开一篇博客专门写这一块。
第13章 事件
- JavaScript与HTML之间的交互是通过事件实现的。事件,就是文档或浏览器窗口中发生的一些特定的交互瞬间。可以使用侦听器(或处理程序)来预订事件,以便事件发生时执行相应的代码。这种在传统软件工程中被称为观察员模式的模型,支持页面的行为(JavaScript代码)与页面的外观(HTML和CSS代码)之间的松散耦合。
13.1 事件流
- 事件冒泡(Event Bubbling):事件从下到上传播,如
<div> -> <body> -> <html> -> document; - 事件捕获(Event Capturing):事件从上到下传播,如
document -> <html> -> <body> -> <div>; - “DOM2级事件”规定的事件流包括三个阶段:事件捕获阶段、处于目标阶段和事件冒泡阶段。首先发生的是事件捕获,为截获事件提供了机会。然后是实际的目标接收到事件。最后一个阶段是冒泡阶段,可以在这个阶段对事件做出响应。以前面简单的HTML页面为例,单击
<div>元素会按照下图所示顺序触发事件。
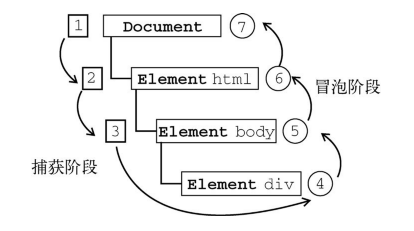
- 在DOM事件流中,实际的目标(
<div>元素)在捕获阶段不会接收到事件。这意味着在捕获阶段,事件从document到<html>再到<body>后就停止了。下一个阶段是“处于目标”阶段,于是事件在<div>上发生,并在事件处理(后面将会讨论这个概念)中被看成冒泡阶段的一部分。然后,冒泡阶段发生,事件又传播回文档。
13.2 事件处理程序
13.2.2 DOM0级事件处理程序
var btn = document.getElementById("myBtn");
btn.onclick = function(){
alert(" Clicked");
};
- 在此,我们通过文档对象取得了一个按钮的引用,然后为它指定了onclick事件处理程序。以这种方式添加的事件处理程序会在事件流的冒泡阶段被处理。删除事件处理程序的方式为将
onclick事件设置为null。
13.2.3 DOM2级事件处理程序
-
“DOM2级事件”定义了两个方法,用于处理指定和删除事件处理程序的操作:addEventListener()和removeEventListener()。
-
所有DOM节点中都包含这两个方法,并且它们都接受3个参数:要处理的事件名、作为事件处理程序的函数和一个布尔值。最后这个布尔值参数如果是true,表示在捕获阶段调用事件处理程序;如果是false,表示在冒泡阶段调用事件处理程序。例如:
var btn = document. getElementById(" myBtn"); btn. addEventListener(" click", function(){ alert( this. id); }, false); -
通过addEventListener()添加的事件处理程序只能使用removeEventListener()来移除;移除时传入的参数与添加处理程序时使用的参数相同。这也意味着通过addEventListener()添加的匿名函数将无法移除。
大多数情况下,都是将事件处理程序添加到事件流的冒泡阶段,这样可以最大限度地兼容各种浏览器。最好只在需要在事件到达目标之前截获它的时候将事件处理程序添加到捕获阶段。如果不是特别需要,我们不建议在事件捕获阶段注册事件处理程序。
13.2.5 跨浏览器的事件处理程序
- 为了以跨浏览器的方式处理事件,不少开发人员会使用能够隔离浏览器差异的JavaScript库,还有一些开发人员会自己开发最合适的事件处理的方法。自己编写代码其实也不难,只要恰当地使用能力检测即可(能力检测在第9章介绍过)。要保证处理事件的代码能在大多数浏览器下一致地运行,只需关注冒泡阶段。
13.3 事件对象
- 触发DOM上的事件时,兼容DOM的浏览器会将一个event对象传入到事件处理程序中。无论指定事件处理程序时使用什么方法(DOM0级或DOM2级),都会传入event对象。
- event对象包含的属性和方法:
bubbles, cancelBubble, cancelable, composed, currentTarget, defaultPrevented, eventPhase, target, timeStamp, type, isTrusted, initEvent(), preventDefault(), stopImmediatePropagation(), stopPropagation(),详细使用查询:MDN web docs - Event。
13.4 事件类型
-
“DOM3级事件”规定了以下几类事件。
- UI(UserInterface,用户界面)事件,当用户与页面上的元素交互时触发;
- 焦点事件,当元素获得或失去焦点时触发;
- 鼠标事件,当用户通过鼠标在页面上执行操作时触发;
- 滚轮事件,当使用鼠标滚轮(或类似设备)时触发;
- 文本事件,当在文档中输入文本时触发;
- 键盘事件,当用户通过键盘在页面上执行操作时触发;
- 合成事件,当为IME(InputMethodEditor,输入法编辑器)输入字符时触发;
- 变动(mutation)事件,当底层DOM结构发生变化时触发。
-
DOM事件类型非常多,使用时查询:MDN web docs - 事件类型一览表
-
除了DOM事件,还有HTML5事件、设备事件、触摸与手势事件。需要用到时再查询。
13.5 内存和性能
- 如果给页面中每一个可点击对象都添加事件,性能损失会比较严重。
- 事件委托:在高层次的DOM树节点上添加事件处理程序,通过event.target来判断点击位置,使得多个节点共用同一事件处理程序。最适合采用事件委托技术的事件包括click、mousedown、mouseup、keydown、keyup和keypress。
- 移除事件处理程序:在不需要的时候移除事件处理程序。
- 使用innerHTML从文档中移除带有事件处理程序的元素时,事件处理程序仍会保持引用关系,仍然被保存在内存中,应先置空再删除。
- IE8及更早版本卸载页面前需先使用onunload事件移除所有事件处理程序。
13.6 模拟事件
- 也可以使用JavaScript在任意时刻来触发特定的事件,而此时的事件就如同浏览器创建的事件一样。也就是说,这些事件该冒泡还会冒泡,而且照样能够导致浏览器执行已经指定的处理它们的事件处理程序。在测试Web应用程序,模拟触发事件是一种极其有用的技术。DOM2级规范为此规定了模拟特定事件的方式,IE9、Opera、Firefox、Chrome和Safari都支持这种方式。IE有它自己模拟事件的方式。
- 可以在document对象上使用createEvent()方法创建event对象。这个方法接收一个参数,即表示要创建的事件类型的字符串。在DOM2级中,所有这些字符串都使用英文复数形式,而在DOM3级中都变成了单数。这个字符串可以是下列几字符串之一:
UIEvents, MouseEvents, MutationEvents, HTMLEvents,具体使用时查询MDN web docs - Event
第16章 HTML5脚本编程
16.1 跨文档消息传递
- 跨文档消息传送(cross-documentmessaging),有时候简称为XDM,指的是在来自不同域的页面间传递消息。例如,www.wrox.com域中的页面与位于一个内嵌框架中的p2p.wrox.com域中的页面通信。XDM把这种机制规范化,让我们能既稳妥又简单地实现跨文档通信。
- XDM的核心是postMessage()方法。在HTML5规范中,除了XDM部分之外的其他部分也会提到这个方法名,但都是为了同一个目的:向另一个地方传递数据。
- postMessage()方法接收两个参数:一条消息和一个表示消息接收方来自哪个域的字符串。第二个参数对保障安全通信非常重要,可以防止浏览器把消息发送到不安全的地方。
- 接收到XDM消息时,会触发window对象的message事件。这个事件是以异步形式触发的,因此从发送消息到接收消息(触发接收窗口的message事件)可能要经过一段时间的延迟。触发message事件后,传递给onmessage处理程序的事件对象包含以下三方面的重要信息。
- data:作为postMessage()第一个参数传入的字符串数据。
- origin:发送消息的文档所在的域,例如"http://www.wrox.com"。(检测消息来源很有安全上的必要性)
- source:发送消息的文档的window对象的代理。这个代理对象主要用于在发送上一条消息的窗口中调用postMessage()方法。如果发送消息的窗口来自同一个域,那这个对象就是window。
16.2 原生拖放
16.2.1 拖放事件
-
拖动某元素时,将依次触发下列事件:
- dragstart(按下鼠标并开始移动时触发)
- drag(鼠标移动期间持续触发)
- dragend(松开鼠标时触发,无论是否放置到有效目标上)
-
当某个元素被拖动到一个有效的放置目标上时,下列事件会依次发生:
- dragenter(元素被拖动到放置目标上时触发)
- dragover(被拖动元素还在放置目标范围内时持续触发)
- dragleave或drop(元素拖出放置目标,或元素被放置时触发)
16.2.2 自定义放置目标
- 所有元素默认不允许放置。
- 可以把任何元素变成有效的放置目标。方法是重写dragenter和dragover事件的默认行为。
- 在Firefox3.5+中,放置事件的默认行为是打开被放到放置目标上的URL。换句话说,如果是把图像拖放到放置目标上,页面就会转向图像文件;而如果是把文本拖放到放置目标上,则会导致无效URL错误。因此,为了让Firefox支持正常的拖放,还要取消drop事件的默认行为,阻止它打开URL。
16.2.3 dataTransfer对象
-
为了在拖放操作时实现数据交换,IE5引入了dataTransfer对象,它是事件对象的一个属性,用于从被拖动元素向放置目标传递字符串格式的数据。因为它是事件对象的属性,所以只能在拖放事件的事件处理程序中访问dataTransfer对象。在事件处理程序中,可以使用这个对象的属性和方法来完善拖放功能。目前,HTML5规范草案也收入了dataTransfer对象。
-
dataTransfer对象有两个主要方法:getData()和setData()。不难想象,getData()可以取得由setData()保存的值。setData()方法的第一个参数,也是getData()方法唯一的一个参数,是一个字符串,表示保存的数据类型,取值为"text"或"URL"。
-
IE只定义了"text"和"URL"两种有效的数据类型,而HTML5则对此加以扩展,允许指定各种MIME类型。考虑到向后兼容,HTML5也支持"text"和"URL",但这两种类型会被映射为"text/plain"和"text/uri-list"。
-
在拖动文本框中的文本时,浏览器会调用setData()方法,将拖动的文本以"text"格式保存在dataTransfer对象中。类似地,在拖放链接或图像时,会调用setData()方法并保存URL。然后,在这些元素被拖放到放置目标时,就可以通过getData()读到这些数据。当然,作为开发人员,你也可以在dragstart事件处理程序中调用setData(),手工保存自己要传输的数据,以便将来使用。
-
将数据保存为文本和保存为URL是有区别的。如果将数据保存为文本格式,那么数据不会得到任何特殊处理。而如果将数据保存为URL,浏览器会将其当成网页中的链接。换句话说,如果你把它放置到另一个浏览器窗口中,浏览器就会打开该URL。
-
Firefox在其第5个版本之前不能正确地将"url"和"text"映射为"text/uri-list"和"text/plain"。但是却能把"Text"(T大写)映射为"text/plain"。为了更好地在跨浏览器的情况下从dataTransfer对象取得数据,最好在取得URL数据时检测两个值,而在取得文本数据时使用"Text"。
16.2.4 dropEffect与effectAllowed
-
利用dataTransfer对象,可不光是能够传输数据,还能通过它来确定被拖动的元素以及作为放置目标的元素能够接收什么操作。为此,需要访问dataTransfer对象的两个属性:dropEffect和effectAllowed。
-
其中,通过dropEffect属性可以知道被拖动的元素能够执行哪种放置行为。这个属性有下列4个可能的值:
- "none":不能把拖动的元素放在这里。这是除文本框之外所有元素的默认值。
- "move":应该把拖动的元素移动到放置目标。
- "copy":应该把拖动的元素复制到放置目标。
- "link":表示放置目标会打开拖动的元素(但拖动的元素必须是一个链接,有URL)。
-
要使用dropEffect属性,必须在ondragenter事件处理程序中针对放置目标来设置它。
-
dropEffect属性只有搭配effectAllowed属性才有用。effectAllowed属性表示允许拖动元素的哪种dropEffect,effectAllowed属性可能的值如下。
- "uninitialized":没有给被拖动的元素设置任何放置行为。
- "none":被拖动的元素不能有任何行为。
- "copy":只允许值为"copy"的dropEffect。
- "link":只允许值为"link"的dropEffect。
- "move":只允许值为"move"的dropEffect。
- "copyLink":允许值为"copy"和"link"的dropEffect。
- "copyMove":允许值为"copy"和"move"的dropEffect。
- "linkMove":允许值为"link"和"move"的dropEffect。
- "all":允许任意dropEffect。
-
必须在ondragstart事件处理程序中设置effectAllowed属性。
16.2.5 可拖动
- 默认情况下,图像、链接和文本是可以拖动的,也就是说,不用额外编写代码,用户就可以拖动它们。文本只有在被选中的情况下才能拖动,而图像和链接在任何时候都可以拖动。
- 让其他元素可以拖动也是可能的。HTML5为所有HTML元素规定了一个draggable属性,表示元素是否可以拖动。图像和链接的draggable属性自动被设置成了true,而其他元素这个属性的默认值都是false。要想让其他元素可拖动,或者让图像或链接不能拖动,都可以设置这个属性。
- 支持draggable属性的浏览器有IE10+、Firefox4+、Safari5+和Chrome。Opera11.5及之前的版本都不支持HTML5的拖放功能。另外,为了让Firefox支持可拖动属性,还必须添加一个ondragstart事件处理程序,并在dataTransfer对象中保存一些信息。
16.3 媒体元素
-
HTML5 新增了两个与媒体相关的标签,让开发人员不必依赖任何插件就能在网页中嵌入跨浏览器的音频和视频内容。这两个标签就是
<audio>和<video>。 -
这两个标签除了能让开发人员方便地嵌入媒体文件之外,都提供了用于实现常用功能的JavaScriptAPI,允许为媒体创建自定义的控件。这两个元素的用法如下。
<!--嵌入视频--> <video src="conference.mpg" id="myVideo">Video player not available.</video> <!--嵌入音频--> <audio src="song.mp3" id="myAudio">Audio player not available.</audio> -
使用这两个元素时,至少要在标签中包含src属性,指向要加载的媒体文件。还可以设置width和height属性以指定视频播放器的大小,而为poster属性指定图像的URI可以在加载视频内容期间显示一幅图像。另外,如果标签中有controls属性,则意味着浏览器应该显示UI控件,以便用户直接操作媒体。位于开始和结束标签之间的任何内容都将作为后备内容,在浏览器不支持这两个媒体元素的情况下显示。
由于这一部分内容较多,在此仅粗略介绍,需要时再查询
<audio>和<video>标签的使用方法。(或者有空另开一篇博客介绍)
16.4 历史状态管理
-
历史状态管理是现代Web应用开发中的一个难点。在现代Web应用中,用户的每次操作不一定会打开一个全新的页面,因此“后退”和“前进”按钮也就失去了作用,导致用户很难在不同状态间切换。要解决这个问题,首选使用hashchange事件(第13章曾讨论过)。HTML5通过更新history对象为管理历史状态提供了方便。
-
通过hashchange事件,可以知道URL的参数什么时候发生了变化,即什么时候该有所反应。而通过状态管理API,能够在不加载新页面的情况下改变浏览器的URL。为此,需要使用history.pushState()方法,该方法可以接收三个参数:状态对象、新状态的标题和可选的相对URL。例如:
history.pushState({name:" Nicholas"}, "Nicholas' page", "nicholas.html"); -
其他相关方法和属性有:
window.popstate(), history.replaceState(), event.state
在使用HTML5的状态管理机制时,请确保使用pushState()创造的每一个“假”URL,在Web服务器上都有一个真的、实际存在的URL与之对应。否则,单击“刷新”按钮会导致404错误。
第17章 错误处理与调试
17.2 错误处理
17.2.1 try-catch语句
-
try - catch:如果try块中的任何代码发生了错误,就会立即退出代码执行过程,然后接着执行catch块。此时,catch块会接收到一个包含错误信息的对象。与在其他语言中不同的是,即使你不想使用这个错误对象,也要给它起个名字。这个对象中包含的实际信息会因浏览器而异,但共同的是有一个保存着错误消息的message属性。ECMA-262还规定了一个保存错误类型的name属性;当前所有浏览器都支持这个属性(Opera9之前的版本不支持这个属性)。因此,在发生错误时,就可以就可以像下面这样实事求是地显示浏览器给出的消息。
try { window.someNonexistentFunction(); } catch (error){ alert(error.message); } -
这个例子在向用户显示错误消息时,使用了错误对象的message属性。这个message属性是唯一一个能够保证所有浏览器都支持的属性,除此之外,不同的浏览器都为事件对象添加了其他相关信息。当然,在跨浏览器编程时,最好还是只使用message属性。
-
finally子句:无论如何也会执行,甚至不受return影响。
-
错误类型:
- Error:Error是基类型,其他错误类型都继承自该类型。因此,所有错误类型共享了一组相同的属性(错误对象中的方法全是默认的对象方法)。Error类型的错误很少见,如果有也是浏览器抛出的;这个基类型的主要目的是供开发人员抛出自定义错误。
- EvalError:EvalError类型的错误会在使用eval()函数而发生异常时被抛出。
- RangeError:RangeError类型的错误会在数值超出相应范围时触发。例如,在定义数组时,如果指定了数组不支持的项数(如?20或Number.MAX_VALUE),就会触发这种错误。
- ReferenceError :在找不到对象的情况下,会发生ReferenceError(这种情况下,会直接导致人所共知的"object expected"浏览器错误)。通常,在访问不存在的变量时,就会发生这种错误。
- SyntaxError:至于SyntaxError,当我们把语法错误的JavaScript字符串传入eval()函数时,就会导致此类错误。如果语法错误的代码出现在eval()函数之外,则不太可能使用SyntaxError,因为此时的语法错误会导致JavaScript代码立即停止执行。
- TypeError:由于在执行特定于类型的操作时,变量的类型并不符合要求所致。最常发生类型错误的情况,就是传递给函数的参数事先未经检查,结果传入类型与预期类型不相符。
- URIError:在使用encodeURI()或decodeURI(),而URI格式不正确时,就会导致URIError错误。这种错误也很少见,因为前面说的这两个函数的容错性非常高。
-
利用不同的错误类型,可以获悉更多有关异常的信息,从而有助于对错误作出恰当的处理。要想知道错误的类型,可以在try-catch语句的catch语句中使用instanceof操作符。
-
合理使用try-catch:当try-catch语句中发生错误时,浏览器会认为错误已经被处理了,因而不会通过本章前面讨论的机制记录或报告错误。try-catch能够让我们实现自己的错误处理机制。使用try-catch最适合处理那些我们无法控制的错误。假设你在使用一个大型JavaScript库中的函数,该函数可能会有意无意地抛出一些错误。由于我们不能修改这个库的源代码,所以大可将对该函数的调用放在try-catch语句当中,万一有什么错误发生,也好恰当地处理它们。在明明白白地知道自己的代码会发生错误时,再使用try-catch语句就不太合适了。例如,如果传递给函数的参数是字符串而非数值,就会造成函数出错,那么就应该先检查参数的类型,然后再决定如何去做。在这种情况下,不应用使用try-catch语句。
17.2.2 抛出错误
-
throw操作符,用于随时抛出自定义错误。抛出错误时,必须要给throw操作符指定一个值,这个值是什么类型,没有要求。
-
在遇到throw操作符时,代码会立即停止执行。仅当有try-catch语句捕获到被抛出的值时,代码才会继续执行。通过使用内置错误类型,可以更真实地模拟浏览器错误。每种错误类型的构造函数接收一个参数,即实际的错误消息。下面是一个例子。
throw new Error("Something bad happened."); throw new TypeError("What type of variable do you take me for?"); -
在创建自定义错误消息时最常用的错误类型是Error、RangeError、ReferenceError和TypeError。
我们认为只应该捕获那些你确切地知道该如何处理的错误。捕获错误的目的在于避免浏览器以默认方式处理它们;而抛出错误的目的在于提供错误发生具体原因的消息。
第18章 JavaScript与XML
第20章 JSON
20.1 语法
-
关于JSON,最重要的是要理解它是一种数据格式,不是一种编程语言。虽然具有相同的语法形式,但JSON并不从属于JavaScript。而且,并不是只有JavaScript才使用JSON,毕竟JSON只是一种数据格式。很多编程语言都有针对JSON的解析器和序列化器。
-
JSON的语法可以表示以下三种类型的值。
- 简单值:使用与JavaScript相同的语法,可以在JSON中表示字符串、数值、布尔值和null。但JSON不支持JavaScript中的特殊值undefined。
- 对象:对象作为一种复杂数据类型,表示的是一组有序的键值对儿。而每个键值对儿中的值可以是简单值,也可以是复杂数据类型的值。
- 数组:数组也是一种复杂数据类型,表示一组有序的值的列表,可以通过数值索引来访问其中的值。数组的值也可以是任意类型——简单值、对象或数组。
-
JSON不支持变量、函数或对象实例,它就是一种表示结构化数据的格式,虽然与JavaScript中表示数据的某些语法相同,但它并不局限于JavaScript的范畴。
一个JSON对象的示例: { "name": "Nicholas", "age": 29 } -
与JavaScript不同,JSON中对象的属性名任何时候都必须加双引号。手工编写JSON时,忘了给对象属性名加双引号或者把双引号写成单引号都是常见的错误。
-
JSON数组使用
[]表示。
20.2 解析与序列化
- JSON对象有两个方法:
stringify()和parse()。在最简单的情况下,这两个方法分别用于把JavaScript对象序列化为JSON字符串和把JSON字符串解析为原生JavaScript值。 - 默认情况下,
JSON.stringify()输出的JSON字符串不包含任何空格字符或缩进。 - 在序列化JavaScript对象时,所有函数及原型成员都会被有意忽略,不体现在结果中。此外,值为undefined的任何属性也都会被跳过。结果中最终都是值为有效JSON数据类型的实例属性。
20.2.2 序列化选项
-
JSON.stringify()除了要序列化的JavaScript对象外,还可以接收另外两个参数,这两个参数用于指定以不同的方式序列化JavaScript对象。第一个参数是个过滤器,可以是一个数组,也可以是一个函数;第二个参数是一个选项,表示是否在JSON字符串中保留缩进。单独或组合使用这两个参数,可以更全面深入地控制JSON的序列化。 -
如果过滤器参数是数组,那么
JSON.stringify()的结果中将只包含数组中列出的属性。 -
如果第二个参数是函数,行为会稍有不同。传入的函数接收两个参数,属性(键)名和属性值。根据属性(键)名可以知道应该如何处理要序列化的对象中的属性。属性名只能是字符串,而在值并非键值对儿结构的值时,键名可以是空字符串。为了改变序列化对象的结果,函数返回的值就是相应键的值。不过要注意,如果函数返回了undefined,那么相应的属性会被忽略。
-
JSON.stringify()方法的第三个参数用于控制结果中的缩进和空白符。如果这个参数是一个数值,那它表示的是每个级别缩进的空格数。最大缩进空格数为10,所有大于10的值都会自动转换为10。只要传入有效的控制缩进的参数值,结果字符串就会包含换行符。 例如,要在每个级别缩进4个空格,可以这样写代码:var jsonText = JSON.stringify(book, null, 4); // 得到结果如下 { "title": "Professional JavaScript", "authors": [ "Nicholas C. Zakas" ], "edition": 3, "year": 2011 } -
如果缩进参数是一个字符串而非数值,则这个字符串将在JSON字符串中被用作缩进字符(不再使用空格)。在使用字符串的情况下,可以将缩进字符设置为制表符,或者两个短划线之类的任意字符。
-
toJSON()可以作为函数过滤器的补充,因此理解序列化的内部顺序十分重要。假设把一个对象传入JSON.stringify(),序列化该对象的顺序如下。- 如果存在
toJSON()方法而且能通过它取得有效的值,则调用该方法。否则,按默认顺序执行序列化。 - 如果提供了第二个参数,应用这个函数过滤器。传入函数过滤器的值是第1步返回的值。
- 对第2步返回的每个值进行相应的序列化。
- 如果提供了第三个参数,执行相应的格式化。
- 如果存在
-
无论是考虑定义
toJSON()方法,还是考虑使用函数过滤器,亦或需要同时使用两者,理解这个顺序都是至关重要的。
20.2.3 解析选项
-
JSON.parse()方法也可以接收另一个参数,该参数是一个函数,将在每个键值对儿上调用。在将日期字符串转换为Date对象时,经常要用到还原函数。例如:
var book = { "title": "Professional JavaScript", "authors": [ "Nicholas C. Zakas" ], edition: 3, year: 2011, releaseDate: new Date( 2011, 11, 1) }; var jsonText = JSON. stringify(book); var bookCopy = JSON. parse(jsonText, function(key, value){ if (key == "releaseDate"){ return new Date( value); } else { return value; } }); alert(bookCopy.releaseDate.getFullYear()); // bookCopy.releaseDate被解析为Date类型的对象,因此能够调用getFullYear()方法
第21章 AJAX和Comet
-
AJAX:通过XMLHttpRequest(XHR)对象以异步方式与服务器进行通信,意味着无需刷新页面即可取得新数据。
-
实践中使用jQuery的ajax函数较多,此笔记为了解背后的机制。
-
IE7+、Firefox、Opera、Chrome和Safari都支持原生的XHR对象,在这些浏览器中创建XHR对象要像下面这样使用XMLHttpRequest构造函数。
var xhr = new XMLHttpRequest();
XMLHTTPRequest对象
21.1.1 XHR的用法
-
在使用XHR对象时,要调用的第一个方法是
open(),它接受3个参数:要发送的请求的类型("get"、"post"等)、请求的URL(相对路径或绝对路径)和表示是否异步发送请求的布尔值。xhr.open("get", "example.php", false); -
只能向同一个域中使用相同端口和协议的URL发送请求。如果URL与启动请求的页面有任何差别,都会引发安全错误。需使用CORS。
xhr. open("get", "example.txt", false); xhr.send(null); -
这里的
send()方法接收一个参数,即要作为请求主体(body)发送的数据。如果不需要通过请求主体发送数据,则必须传入null,因为这个参数对有些浏览器来说是必需的。调用send()之后,请求就会被分派到服务器。 -
异步发送请求时,可以通过readestatechange事件来监听readyState属性的变化,从而确认是否收到响应。当readyState为4的时候,说明已经接收到全部响应数据,而且已经可以在客户端使用了。
-
在收到响应后,响应的数据会自动填充XHR对象的属性,相关的属性简介如下。
- responseText:作为响应主体被返回的文本。
- responseXML:如果响应的内容类型是"text/xml"或"application/xml",这个属性中将保存包含着响应数据的XMLDOM文档。
- status:响应的HTTP状态。收到响应后第一步应该检查status。
- statusText:HTTP状态的说明。
-
默认情况下,XHR还会发送相关的头部信息。要自定义头部信息,在
open()之后,send()之前使用SetRequestHeader()方法。 -
获取响应头部信息,使用
getResponseHeader()。
21.1.3 GET请求
-
传入
open()函数的URL必须使用encodeURIComponent()进行编码。 -
下面是一个添加参数的辅助函数示例:
function addURLParam(url, name, value) { url += (url.indexOf("?") == -1 ? "?" : "&"); url += encodeURIComponent(name) + "=" + encodeURIComponent(value); return url; }
21.1.4 POST请求
- 如要使用XHR模仿表单提交,需要将Content-type头部信息设置为
application/x-www-form-urlencoded。 - POST数据的格式与querystring相同。
21.2 XMLHTTPRequest 2级
21.2.1 FormData
-
由于表单序列化非常常用,XMLHTTPRequest2级定义了FormData类型,为序列化提供了便利。其用法一目了然。
var data = new FormData(); data.append("name", "Nicholas"); -
创建后的FormData实例可以直接传给XHR的send()方法。
21.2.3 overrideMimeType() 方法
overrideMimeType()方法可以重写响应的MIME类型,从而更加恰当地处理响应。
21.3 进度事件
21.3.1 load事件
- 与onReadyStateChange监听器类似,监听是否完成加载。
21.3.2 progress事件
- 这个事件会在浏览器接收新数据期间周期性地触发。而onprogress事件处理程序会接收到一个event对象,其target属性是XHR对象,但包含着三个额外的属性:lengthComputable、position和totalSize。其中,lengthComputable是一个表示进度信息是否可用的布尔值,position表示已经接收的字节数,totalSize表示根据Content-Length响应头部确定的预期字节数。有了这些信息,我们就可以为用户创建一个进度指示器了。
21.4 跨域资源共享
- Firefox3.5+、Safari4+、Chrome、iOS版Safari和Android平台中的WebKit都通过XMLHttpRequest对象实现了对CORS的原生支持。在尝试打开不同来源的资源时,无需额外编写代码就可以触发这个行为。要请求位于另一个域中的资源,使用标准的XHR对象并在open()方法中传入绝对URL即可。IE浏览器需要使用XDR对象,需要时查询。
- 跨浏览器支持:检测XHR是否支持CORS的最简单方式,就是检查是否存在withCredentials属性。再结合检测XDomainRequest对象是否存在,就可以兼顾所有浏览器了。
21.5 其他跨域技术
- 图像Ping:使用
<img>标签,实现浏览器到服务器的单向通信。 - JSONP:使用
<script>标签请求加载一个脚本,服务器返回JS函数调用形式的数据。更多请看说说JSON和JSONP。 - Comet:Ajax是一种从页面向服务器请求数据的技术,而Comet则是一种服务器向页面推送数据的技术。