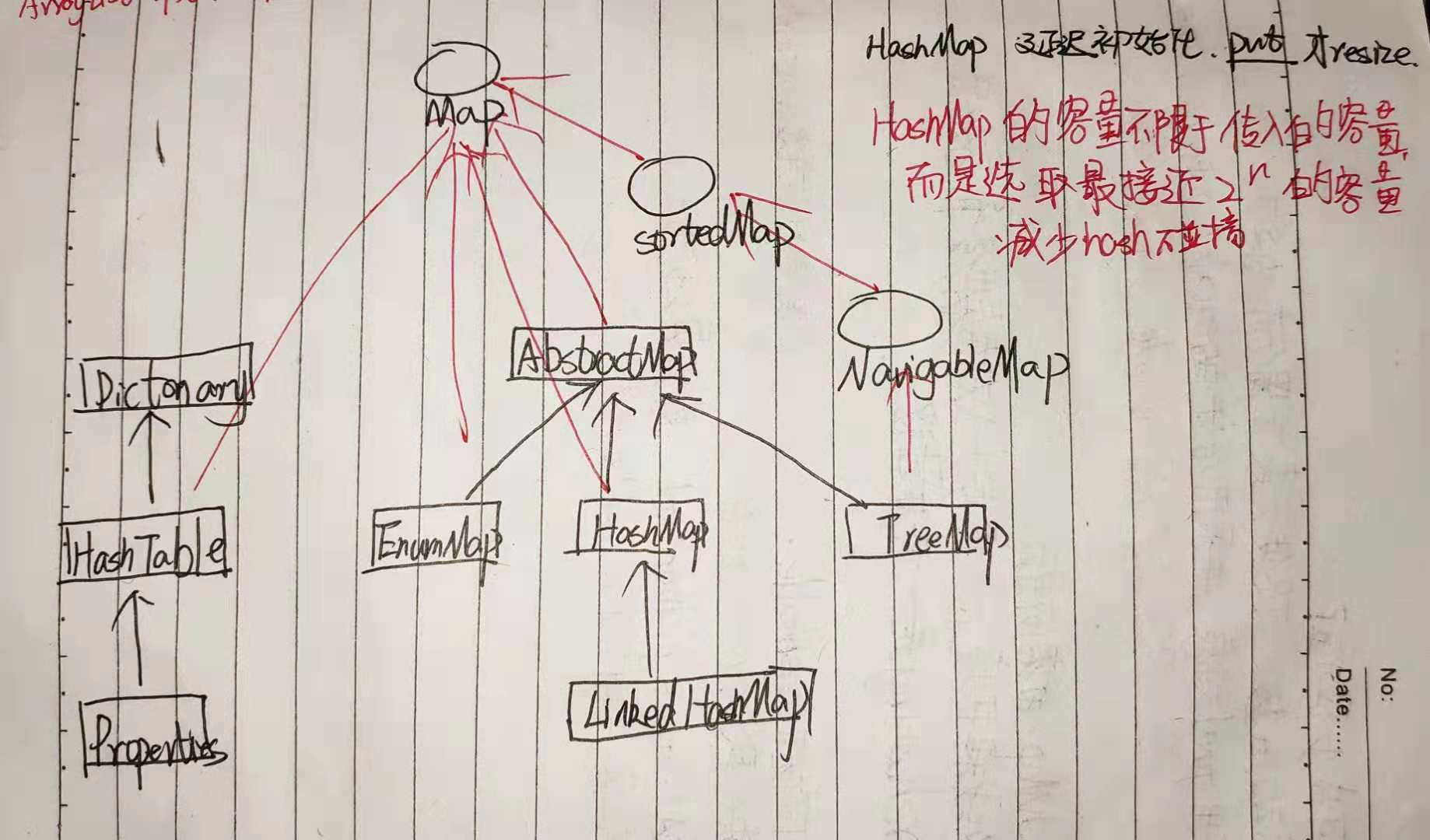
java集合框架---Map体系
HashMap层次体系:
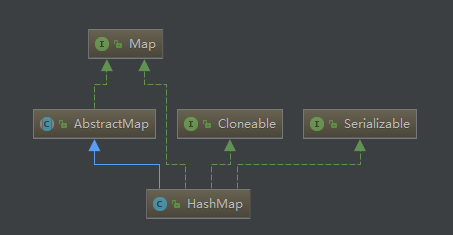
1.实现了Cloneable,可以被克隆
2.实现了Serializable,可以被序列化
3.继承AbstractMap,实现了Map接口,具有Map的所有功能。
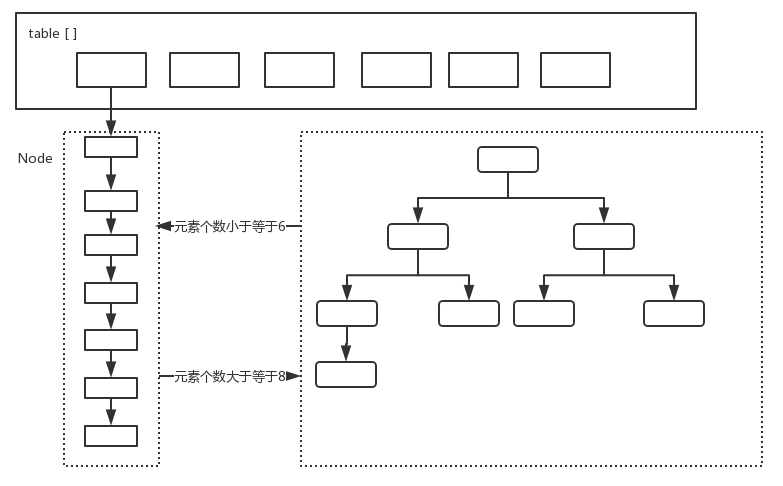
HashMap的底层结构为 数组+链表或红黑树,当链表的数量达到一定数量的时候,会转换成红黑树。红黄树的节点树remove到一定数量的时候,会重新转换成链表。
数组的查询效率为O(1),链表的查询效率是O(k),红黑树的查询效率是O(log n),n为一个桶中的元素个数,当元素数量非常多的时候,转化为红黑树能极大地提高效率。
put(K key, V value)方法
public V put(K key, V value) { // 调用hash(key)计算出key的hash值(hash发散) return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 如果table数量为0,初始化 if ((tab = table) == null || (n = tab.length) == 0) //使用resize()进行初始化 n = (tab = resize()).length; // 如果桶没有元素 if ((p = tab[i = (n - 1) & hash]) == null) // 新建一个Node放在第一个位置 tab[i] = newNode(hash, key, value, null); else { // 桶中已经有元素了 Node<K,V> e; K k; // 如果桶中第一个元素的key与待插入元素的key相同,保存到e中用于后续修改value值 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果第一个元素是树节点,则调用树节点的putTreeVal插入元素 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 遍历这个桶对应的链表,binCount用于存储链表中元素的个数 for (int binCount = 0; ; ++binCount) { // 如果链表遍历完了都没有找到相同key的元素,说明该key对应的元素不存在,则在链表最后插入一个新节点 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 如果插入新节点后链表长度大于8,则判断是否需要树化,因为第一个元素没有加到binCount中,所以这里-1 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // 如果待插入的key在链表中找到了,则退出循环 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // 如果找到了对应key的元素 if (e != null) { // existing mapping for key // 记录下旧值 V oldValue = e.value; // 判断是否需要替换旧值 if (!onlyIfAbsent || oldValue == null) // 替换旧值为新值 e.value = value; afterNodeAccess(e); // 返回旧值 return oldValue; } } // 到这里了说明没有找到元素,修改次数加1 ++modCount; // 元素数量加1,判断是否需要扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); // 没找到元素返回null return null; }
HashMap的 put方法主要逻辑:
1.Node[] 数组未初始化,则初始化
2.对key求hash值,计算下标
3.如果没有碰撞,直接放桶里
4.如果碰撞了,判断链表中存在该元素,存在则替换,不存在则插到链表的后面
5.如果链表的长度大于8,则转换成红黑树
6.判断桶是否已经满了,满了则需要扩容
ConcurrentHashMap层次体系:
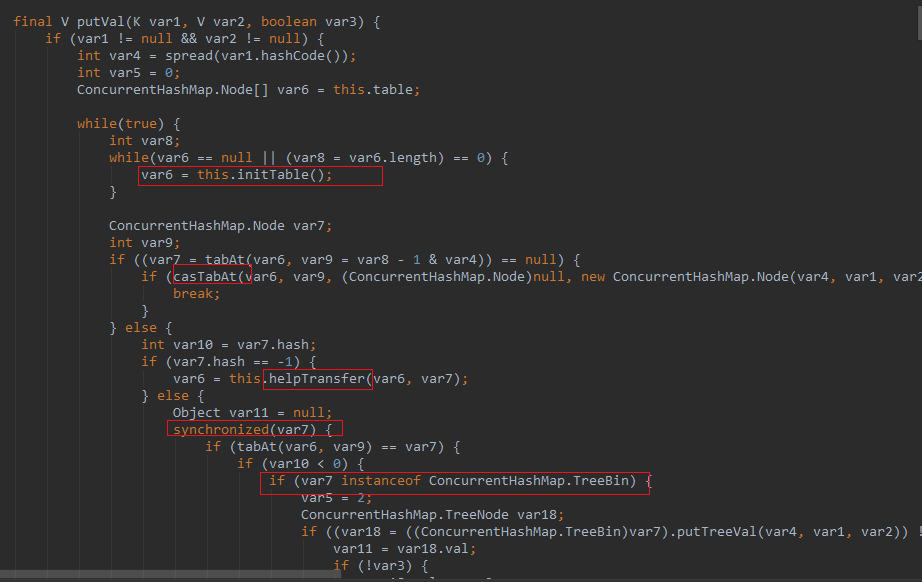
ConcurrentHashMap的put方法主要逻辑:
1.判断Node[]是否初始化,没有初始化则初始化
2.通过Hash定位数组的索引坐标,是否有节点存在,
没有则使用CAS进行节点的添加(链表头节点),失败进入下一层循环
3.检查内部是否正在进行扩容,如果正在扩容,协助扩容(。。。)
4. if var7 != null ,则使用synchronized锁住元素
a.如果是链表,添加
b.如果是红黑树,添加
5.判断链表的长度 >=8 ,超过临界值,就把链表转换成红黑树
总结:
HashMap:线程不安全,数组+链表,红黑树
HashTable:锁住整个对象,线程安全,数组+链表
ConcurrentHashMap:CAS判断对应的坐标是否有节点,有节点,用同步锁锁住,数组+链表+红黑树