人类在进化的过程中,创造了数字、文字、符号等来进行数据的记录,但是承受着认知能力和创造能力的提升,数据量越来越大,对于数据的记录和准确查找,成为了一个重大难题。
数据库的优势:实现数据持久化,使用完整的管理系统统一管理,易于查询 。
计算机诞生后,数据开始在计算机中存储并计算,并设计出了数据库系统。
数据库系统解决的问题:持久化存储,优化读写,保证数据的有效性。
二、数据库的常见概念
1、DB:数据库,存储数据的容器
2、DBMS:数据库管理系统,又称为数据库软件或数据库产品,用于创建或管理DB
3、SQL:结构化查询语言,用于和数据库通信的语言,不是某个数据库软件特有的,而是几乎所有的主流数据库软件通用的语言
当前使用的数据库,主要分为两类:
文档型,如sqlite,就是一个文件,通过对文件的复制完成数据库的复制。
服务型,如mysql、postgre,数据存储在一个物理文件中,但是需要使用终端以tcp/ip协议连接,进行数据库的读写操作。
当前物理的数据库都是按照E-R模型进行设计的(E表示entry,实体,R表示relationship,关系)。
三范式
经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式。
第一范式(1NF):列不可拆分;
第二范式(2NF):唯一标识;
第三范式(3NF):引用主键。
说明:后一个范式,都是在前一个范式的基础上建立的。
mysql的用户及用户组,是否安装成功

MySQL服务的启动和停止
停止mysql服务
PS C:Windowssystem32> net stop mysql mysql 服务正在停止. mysql 服务已成功停止。
开启mysql服务
PS C:Windowssystem32> net start mysql mysql 服务正在启动 .. mysql 服务已经启动成功。
注:Linux中的mysql开启与关闭使用service mysql start和service mysql stop。
数据库操作
1、显示数据库
切记在数据库的操作语句的末尾一定要加一个分号来结束,否则即使回车命令不会执行需要补一个分号才是完整的命令。
SHOW DATABASES;
默认数据库有三个他们的作用分别是:
mysql - 用户权限相关数据
test - 用于用户测试数据
information_schema - MySQL本身架构相关数据


+--------------------+ | Database | +--------------------+ | information_schema | | db1 | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.02 sec)
2、创建删除数据库
也就是创建删除文件夹
create database db2 default charset utf8;
默认数据库名称使用utf8编码格式,这样数据库是中文也可以正常显示使用。
删除数据库时使用drop命令。
drop database db2;
3、使用数据库
mysql> use db1 Database changed
4.显示当前数据库中所有的表
mysql> show tables; +---------------+ | Tables_in_db1 | +---------------+ | t1 | | t2 | +---------------+ 2 rows in set (0.00 sec)
5、用户管理
create user 'alex'@'192.168.1.1' identified by '123123';#只能在这台ip上登陆 create user 'alex'@'192.168.1.%' identified by '123123'; create user 'alex'@'%' identified by '123123';#%表示任意网段
创建完的用户是没有任何权限操作的,必须要使用grant授权以后,用户才有权限,并且后增用户是无法拥有grant的权限的,grant操作只有root用户可以使用。
grant select,insert,update on db1.t1 to 'alex'@'%'; grant all privileges on db1.t1 to 'alex'@'%';#所有权限除了grant grant 权限 on 数据库 show grants for '用户'@'IP地址' -- 查看权限 grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权 revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限 库与表可以是*,表示所有
drop user '用户名'@'IP地址';
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';; #注意这里的分号
set password for '用户名'@'IP地址' = Password('新密码')
用户权限相关数据保存在mysql数据库的user表中,所以也可以直接对其进行操作,但是不建议直接操作user表。
对于目标数据库以及内部其他: 数据库名.* 数据库中的所有 数据库名.表 指定数据库中的某张表 数据库名.存储过程 指定数据库中的存储过程 *.* 所有数据库
注:数据库本质是socket链接的。
用户名@IP地址 用户只能在改IP下才能访问 用户名@192.168.1.% 用户只能在改IP段下才能访问(通配符%表示任意) 用户名@% 用户可以再任意IP下访问(默认IP地址为%)
flush privileges,将数据读取到内存中,从而立即生效。
在mysql中忘记密码怎么办?
# 启动免授权服务端 mysqld --skip-grant-tables # 客户端 mysql -u root -p # 修改用户名密码 update mysql.user set authentication_string=password('666') where user='root'; flush privileges;
数据表操作
1、创建表
create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空 )ENGINE=InnoDB DEFAULT CHARSET=utf8
innodb支持事务,原子性操作,例:一方数据转账到另一方,如果一方扣款成功,另一方未收到就违反了事务操作,事务操作就是如果另一方收款失败那么这次交易不成立,扣款也不会发生。
null表示可以为空,not null表示不可以为空。
mysql> create table t3(id int null,name char(10))engine=innodb default charset=utf8; Query OK, 0 rows affected (0.34 sec) mysql> insert into t3(name) value('jeff'); Query OK, 1 row affected (0.08 sec) mysql> select * from t3; +------+------+ | id | name | +------+------+ | NULL | jeff | +------+------+ 1 row in set (0.00 sec)
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值 create table tb1(nid int not null defalut 2,num int not null)
mysql> create table t4(id int auto_increment primary key,name char(10))engine=innodb default charset=utf8; Query OK, 0 rows affected (0.25 sec) mysql> insert into t4(name) value('jeff'); Query OK, 1 row affected (0.03 sec) mysql> insert into t4(name) value('frank'); Query OK, 1 row affected (0.03 sec) mysql> insert into t4(name) value('egon'); Query OK, 1 row affected (0.02 sec) mysql> insert into t4(name) value('alex'); Query OK, 1 row affected (0.02 sec) mysql> select * from t4; +----+-------+ | id | name | +----+-------+ | 1 | jeff | | 2 | frank | | 3 | egon | | 4 | alex | +----+-------+ 4 rows in set (0.00 sec)
还有一种方法也可以做到自增:
create table tb1(nid int not null auto_increment,num int null,index(nid))
注意:1、对于自增列,必须是索引(含主键)。 2、对于自增可以设置步长和起始值
show session variables like 'auto_inc%'; set session auto_increment_increment=2; set session auto_increment_offset=10; shwo global variables like 'auto_inc%'; set global auto_increment_increment=2; set global auto_increment_offset=10;
主键是一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。
对于自增还有几点需要补充:
mysql> desc t7; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(10) | YES | | NULL | | +-------+----------+------+-----+---------+----------------+ 2 rows in set (0.00 sec)#查看每个字段的意思。
查看AUTO_INCREMENT字段可以知道创建的下一个行的自增id是多少。
mysql> select * from t7; +----+------+ | id | name | +----+------+ | 1 | alex | | 2 | egon | | 3 | fu | +----+------+ 3 rows in set (0.00 sec) mysql> show create table t7 G; *************************** 1. row *************************** Table: t7 Create Table: CREATE TABLE `t7` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` char(10) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 1 row in set (0.00 sec) #所以下一个行的id从4开始,即使delete还是从4开始,truncate会从1从新计数。
mysql> alter table t7 AUTO_INCREMENT=20; Query OK, 0 rows affected (0.18 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show create table t7 G; *************************** 1. row *************************** Table: t7 Create Table: CREATE TABLE `t7` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` char(10) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8 1 row in set (0.00 sec) mysql> insert into t7(name) values('jeff'); Query OK, 1 row affected (0.08 sec) mysql> select * from t7; +----+------+ | id | name | +----+------+ | 1 | alex | | 2 | egon | | 3 | fu | | 20 | jeff | +----+------+ 4 rows in set (0.00 sec)
关于MySQL的自增与步长分为两种,一种是基于会话的0,只在这个会话有效果,在别的窗口或者下一次登陆都无效了。另一种是基于全局的。
这里的会话的概念就是一次登陆就是一次会话。
show session variables like 'auto_inc%'; 查看全局变量 +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+
set session auto_increment_increment=2; 设置会话步长 set session auto_increment_offset=10; show global variables like 'auto_inc%'; 查看全局变量 set global auto_increment_increment=2; 设置会话步长 set global auto_increment_offset=10;
注: 如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值被忽略。
mysql> insert into t7(name) values('frank'); Query OK, 1 row affected (0.08 sec) mysql> select * from t7; +----+-------+ | id | name | +----+-------+ | 1 | alex | | 2 | egon | | 3 | fu | | 20 | jeff | | 30 | frank | +----+-------+ 5 rows in set (0.00 sec) mysql> show session variables like 'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 20 | | auto_increment_offset | 10 | +--------------------------+-------+ 2 rows in set, 1 warning (0.00 sec)
sql的自增步长在创建的时候都有字段规定,这样基于表的起始与步长更合理。
CREATE TABLE `t5` ( `nid` int(11) NOT NULL AUTO_INCREMENT, `pid` int(11) NOT NULL, `num` int(11) DEFAULT NULL, PRIMARY KEY (`nid`,`pid`) ) ENGINE=InnoDB AUTO_INCREMENT=4, 步长=2 DEFAULT CHARSET=utf8
create table tb1(nid int not null auto_increment primary key,num int null) create table tb1(nid int not null,num int not null,primary key(nid,num))
drop table 表名
delete from 表名#删除再添加还是从删除时的主键自增 truncate table 表名#删除后再创建从1开始自增
添加列:alter table 表名 add 列名 类型 删除列:alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键:alter table 表名 drop foreign key 外键名称 修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;
示例: 1. 修改存储引擎 mysql> alter table service -> engine=innodb; 2. 添加字段 mysql> alter table student10 -> add name varchar(20) not null, -> add age int(3) not null default 22; mysql> alter table student10 -> add stu_num varchar(10) not null after name; //添加name字段之后 mysql> alter table student10 -> add sex enum('male','female') default 'male' first; //添加到最前面 3. 删除字段 mysql> alter table student10 -> drop sex; mysql> alter table service -> drop mac; 4. 修改字段类型modify mysql> alter table student10 -> modify age int(3); mysql> alter table student10 -> modify id int(11) not null primary key auto_increment; //修改为主键 5. 增加约束(针对已有的主键增加auto_increment) mysql> alter table student10 modify id int(11) not null primary key auto_increment; ERROR 1068 (42000): Multiple primary key defined mysql> alter table student10 modify id int(11) not null auto_increment; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 6. 对已经存在的表增加复合主键 mysql> alter table service2 -> add primary key(host_ip,port); 7. 增加主键 mysql> alter table student1 -> modify name varchar(10) not null primary key; 8. 增加主键和自动增长 mysql> alter table student1 -> modify id int not null primary key auto_increment; 9. 删除主键 a. 删除自增约束 mysql> alter table student10 modify id int(11) not null; b. 删除主键 mysql> alter table student10 -> drop primary key;
复制表结构+记录 (key不会复制: 主键、外键和索引) mysql> create table new_service select * from service; 只复制表结构 mysql> select * from service where 1=2; //条件为假,查不到任何记录 Empty set (0.00 sec) mysql> create table new1_service select * from service where 1=2; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> create table t4 like employees;
基本数据类型:
MySQL的数据类型大致分为:数值、时间和字符串。
bit[(M)] 二进制位(101001),m表示二进制位的长度(1-64),默认m=1 tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127. 无符号: 0 ~ 255 特别的: MySQL中无布尔值,使用tinyint(1)构造。 int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号: 0 ~ 4294967295 特别的:整数类型中的m仅用于显示,对存储范围无限制。例如: int(5),当插入数据2时,select 时数据显示为: 00002 bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号: -9223372036854775808 ~ 9223372036854775807 无符号: 0 ~ 18446744073709551615 decimal[(m[,d])] [unsigned] [zerofill] 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。 特别的:对于精确数值计算时需要用此类型 decaimal能够存储精确值的原因在于其内部按照字符串存储。 FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] 单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。 无符号: -3.402823466E+38 to -1.175494351E-38, 0 1.175494351E-38 to 3.402823466E+38 有符号: 0 1.175494351E-38 to 3.402823466E+38 **** 数值越大,越不准确 **** DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。 无符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 0 2.2250738585072014E-308 to 1.7976931348623157E+308 有符号: 0 2.2250738585072014E-308 to 1.7976931348623157E+308 **** 数值越大,越不准确 ****
char (m) char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。其中m代表字符串的长度。 PS: 即使数据小于m长度,也会占用m长度 varchar(m) varchars数据类型用于变长的字符串,可以包含最多达255个字符。其中m代表该数据类型所允许保存的字符串的最大长度,只要长度小于该最大值的字符串都可以被保存在该数据类型中。 注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡 text text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 mediumtext A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters. longtext A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters. PS:比longtxt还大的文件直接存入硬盘然后把路径写到数据库中。 enum 枚举类型, An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.) 示例: CREATE TABLE shirts ( name VARCHAR(40), size ENUM('x-small', 'small', 'medium', 'large', 'x-large') ); INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small'); 只能从枚举中取出一个值 set 集合类型 A SET column can have a maximum of 64 distinct members. 示例: CREATE TABLE myset (col SET('a', 'b', 'c', 'd')); INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d'); 从集合中取出任意个值。
DATE YYYY-MM-DD(1000-01-01/9999-12-31) TIME HH:MM:SS('-838:59:59'/'838:59:59') YEAR YYYY(1901/2155) DATETIME YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) TIMESTAMP YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时) #datatime是使用最多的
char(10)不满10位也强制占位成10位,这样在查找时速度更快,varchar(10)不定长但是最多10位,这样做更节省空间,在操作时有些情况比如ip本来就是定长,所以使用char()更好,创建数据表或在优化的时候也应该把char()放到前面这样会更高效更快。
使用now函数插入当前的时间和日期。
insert into table values(now(),now(),now()); --可查当前时间,格式自己设置 create table t8(d date,t time,dt datetime); insert into t8 values(now(),now(),now()); select * from t8; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2017-09-17 | 21:06:59 | 2017-09-17 21:06:59 | +------------+----------+---------------------+
单条件where的使用。
#1:单条件查询 SELECT name FROM employee WHERE post='sale'; #2:多条件查询 SELECT name,salary FROM employee WHERE post='teacher' AND salary>10000; #3:关键字BETWEEN AND SELECT name,salary FROM employee WHERE salary BETWEEN 10000 AND 20000; SELECT name,salary FROM employee WHERE salary NOT BETWEEN 10000 AND 20000; #4:关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS) SELECT name,post_comment FROM employee WHERE post_comment IS NULL; SELECT name,post_comment FROM employee WHERE post_comment IS NOT NULL; SELECT name,post_comment FROM employee WHERE post_comment=''; 注意''是空字符串,不是null ps: 执行 update employee set post_comment='' where id=2; 再用上条查看,就会有结果了 #5:关键字IN集合查询 SELECT name,salary FROM employee WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ; SELECT name,salary FROM employee WHERE salary IN (3000,3500,4000,9000) ; SELECT name,salary FROM employee WHERE salary NOT IN (3000,3500,4000,9000) ; #6:关键字LIKE模糊查询 通配符’%’ SELECT * FROM employee WHERE name LIKE 'eg%'; 通配符’_’ SELECT * FROM employee WHERE name LIKE 'al__';
表的操作
insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表 (列名,列名...) select (列名,列名...) from 表
delete from 表 delete from 表 where id=1 and name='alex'
update 表 set name = 'alex' where id>1
select * from 表 select * from 表 where id > 1 select nid,name,gender as gg from 表 where id > 1
create table tb12( id int auto_increment primary key, name varchar(32), age int )engine=innodb default charset=utf8; 增 insert into tb11(name,age) values('alex',12); insert into tb11(name,age) values('alex',12),('root',18); insert into tb12(name,age) select name,age from tb11;tb11的所有都复制到tb12 删 delete from tb12; delete from tb12 where id !=2 delete from tb12 where id =2 delete from tb12 where id > 2 delete from tb12 where id >=2 and name=‘alex’ delete from tb12 where id >=2 or name='alex' 改 update tb12 set name='alex' where id>12 and name='xx' update tb12 set name='alex',age=19 where id>12 and name='xx' 查 select * from tb12; select id,name from tb12; select id,name from tb12 where id > 10 or name ='xxx'; select id,name as cname from tb12 where id > 10 or name ='xxx'; select name,age,11 from tb12; 其他: select * from tb12 where id != 1 select * from tb12 where id in (1,5,12);只拿1,5,12 select * from tb12 where id not in (1,5,12);除了都拿 select * from tb12 where id in (select id from tb11)只能拿一列 select * from tb12 where id between 5 and 12;闭区间 通配符: select * from tb12 where name like "a%"%任意字符 select * from tb12 where name like "a_"_只是一个字符 分页: select * from tb12 limit 10;前10条 select * from tb12 limit 0,10; select * from tb12 limit 10,10; select * from tb12 limit 20,10; 两个值从第几条开始取,向后取多少条 select * from tb12 limit 10 offset 20; 从20开始取10条 # page = input('请输入要查看的页码') # page = int(page) # (page-1) * 10 # select * from tb12 limit 0,10; 1 # select * from tb12 limit 10,10;2 排序: select * from tb12 order by id desc; id大到小 select * from tb12 order by id asc; id小到大 select * from tb12 order by age desc,id desc; 取后10条数据(倒序取) select * from tb12 order by id desc limit 10; 分组: select count(id),max(id),part_id from userinfo5 group by part_id; count max min sum avg **** 如果对于聚合函数结果进行二次筛选时?必须使用having **** select count(id),part_id from userinfo5 group by part_id having count(id) > 1; select count(id),part_id from userinfo5 where id > 0 group by part_id having count(id) > 1; where不能加聚合函数 连表操作: select * from userinfo5,department5#这个是不对的 select * from userinfo5,department5 where userinfo5.part_id = department5.id select * from userinfo5 left join department5 on userinfo5.part_id = department5.id select * from department5 left join userinfo5 on userinfo5.part_id = department5.id # userinfo5左边全部显示 select * from userinfo5 innder join department5 on userinfo5.part_id = department5.id 将出现null时一行隐藏 select * from department5 left join userinfo5 on userinfo5.part_id = department5.id left join userinfo6 on userinfo5.part_id = department5.id select score.sid, student.sid from score left join student on score.student_id = student.sid left join course on score.course_id = course.cid left join class on student.class_id = class.cid left join teacher on course.teacher_id=teacher.tid select count(id) from userinfo5;
#1.查询表中的单个字段 SELECT last_name(字段) FROM employees(表); #2.查询表中的多个字段 SELECT last_name,salary,email(查询字段) FROM employees(表); #3.查询表中的所有字段 #方式一(与查询多字段一致,不会这么用): SELECT `employee_id`, `first_name`, `last_name`, `phone_number`, `last_name`, `job_id`, `phone_number`, `job_id`, `salary`, `commission_pct`, `manager_id`, `department_id`, `hiredate` FROM employees ; #方式二: SELECT * FROM employees; #4.查询常量值 SELECT 100; SELECT 'john'; #5.查询表达式 SELECT 100%98; #6.查询函数 SELECT VERSION(); #7.起别名 /* ①便于理解 ②如果要查询的字段有重名的情况,使用别名可以区分开来 */ #方式一:使用as SELECT 100%98 AS 结果; SELECT last_name AS 姓,first_name AS 名 FROM employees; #方式二:使用空格 SELECT last_name 姓,first_name 名 FROM employees; #案例:查询salary,显示结果为 out put SELECT salary AS "out put" FROM employees; #8.去重 #案例:查询员工表中涉及到的所有的部门编号 SELECT DISTINCT department_id FROM employees; #9.+号的作用 /* java中的+号: ①运算符,两个操作数都为数值型 ②连接符,只要有一个操作数为字符串 mysql中的+号: 仅仅只有一个功能:运算符 select 100+90; 两个操作数都为数值型,则做加法运算 select '123'+90;只要其中一方为字符型,试图将字符型数值转换成数值型 如果转换成功,则继续做加法运算 select 'john'+90; 如果转换失败,则将字符型数值转换成0 select null+10; 只要其中一方为null,则结果肯定为null */ #案例:查询员工名和姓连接成一个字段,并显示为 姓名 SELECT CONCAT('a','b','c') AS 结果; SELECT CONCAT(last_name,first_name) AS 姓名 FROM employees;
/* 语法: select 查询列表 from 表名 where 筛选条件; 分类: 一、按条件表达式筛选 简单条件运算符:> < = != <> >= <= 二、按逻辑表达式筛选 逻辑运算符: 作用:用于连接条件表达式 && || ! and or not &&和and:两个条件都为true,结果为true,反之为false ||或or: 只要有一个条件为true,结果为true,反之为false !或not: 如果连接的条件本身为false,结果为true,反之为false 三、模糊查询 like between and in is null */ #一、按条件表达式筛选 #案例1:查询工资>12000的员工信息 SELECT * FROM employees WHERE salary>12000; #案例2:查询部门编号不等于90号的员工名和部门编号 SELECT last_name, department_id FROM employees WHERE department_id<>90; #二、按逻辑表达式筛选 #案例1:查询工资z在10000到20000之间的员工名、工资以及奖金 SELECT last_name, salary, commission_pct FROM employees WHERE salary>=10000 AND salary<=20000; #案例2:查询部门编号不是在90到110之间,或者工资高于15000的员工信息 SELECT * FROM employees WHERE NOT(department_id>=90 AND department_id<=110) OR salary>15000; #三、模糊查询 /* like between and in is null|is not null */ #1.like /* 特点: ①一般和通配符搭配使用 通配符: % 任意多个字符,包含0个字符 _ 任意单个字符 *、 #案例1:查询员工名中包含字符a的员工信息 select * from employees where last_name like '%a%';#abc #案例2:查询员工名中第三个字符为e,第五个字符为a的员工名和工资 select last_name, salary FROM employees WHERE last_name LIKE '__n_l%'; #案例3:查询员工名中第二个字符为_的员工名 SELECT last_name FROM employees WHERE last_name LIKE '_\_%'; last_name LIKE '_$_%' ESCAPE '$';不一定是这个符号 #2.between and /* ①使用between and 可以提高语句的简洁度 ②包含临界值 ③两个临界值不要调换顺序 */ #案例1:查询员工编号在100到120之间的员工信息 SELECT * FROM employees WHERE employee_id >= 120 AND employee_id<=100; #---------------------- SELECT * FROM employees WHERE employee_id BETWEEN 120 AND 100; #3.in /* 含义:判断某字段的值是否属于in列表中的某一项 特点: ①使用in提高语句简洁度 ②in列表的值类型必须一致或兼容 ③in列表中不支持通配符 */ #案例:查询员工的工种编号是 IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号 SELECT last_name, job_id FROM employees WHERE job_id = 'IT_PROT' OR job_id = 'AD_VP' OR JOB_ID ='AD_PRES'; #------------------ SELECT last_name, job_id FROM employees WHERE job_id IN( 'IT_PROT' ,'AD_VP','AD_PRES');#不支持通配符 #4、is null /* =或<>不能用于判断null值 is null或is not null 可以判断null值 */ #案例1:查询没有奖金的员工名和奖金率 SELECT last_name, commission_pct FROM employees WHERE commission_pct IS NULL; #案例1:查询有奖金的员工名和奖金率 SELECT last_name, commission_pct FROM employees WHERE commission_pct IS NOT NULL; #----------以下为× SELECT last_name, commission_pct FROM employees WHERE salary IS 12000; #安全等于 <=> #案例1:查询没有奖金的员工名和奖金率(可以判断null值) SELECT last_name, commission_pct FROM employees WHERE commission_pct <=>NULL; #案例2:查询工资为12000的员工信息 SELECT last_name, salary FROM employees WHERE salary <=> 12000; #is null 与 <=> IS NULL:仅仅可以判断NULL值,可读性较高,建议使用 <=> :既可以判断NULL值,又可以判断普通的数值,可读性较低
SELECT CONCAT(`first_name`,',',`last_name`,',',`job_id`,',',IFNULL(commission_pct,0)) AS out_put FROM employees; concat就是连接号可以字符串拼接,ifnull就是不存在时取元祖下标为1的值。
#进阶3:排序查询 /* 语法: select 查询列表 from 表名 【where 筛选条件】 order by 排序的字段或表达式; 特点: 1、asc代表的是升序,可以省略 desc代表的是降序 2、order by子句可以支持 单个字段、别名、表达式、函数、多个字段 3、order by子句在查询语句的最后面,除了limit子句 4、排序的字段不是必须为查询的字段 */ #1、按单个字段排序 SELECT * FROM employees ORDER BY salary DESC; #2、添加筛选条件再排序 #案例:查询部门编号>=90的员工信息,并按员工编号降序 SELECT * FROM employees WHERE department_id>=90 ORDER BY employee_id DESC; #3、按表达式排序 #案例:查询员工信息 按年薪降序 SELECT *,salary*12*(1+IFNULL(commission_pct,0)) FROM employees ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC; #4、按别名排序 #案例:查询员工信息 按年薪升序 SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪 FROM employees ORDER BY 年薪 ASC; #5、按函数排序 #案例:查询员工名,并且按名字的长度降序 SELECT LENGTH(last_name),last_name FROM employees ORDER BY LENGTH(last_name) DESC; #6、按多个字段排序 #案例:查询员工信息,要求先按工资降序,再按employee_id升序 SELECT * FROM employees ORDER BY salary DESC,employee_id ASC;
/* 功能:用作统计使用,又称为聚合函数或统计函数或组函数 分组函数作用于一组数据,并对一组数据返回一个值。 分类: sum 求和、avg 平均值、max 最大值 、min 最小值 、count 计算个数 特点: 1、sum、avg一般用于处理数值型 max、min、count可以处理任何类型 2、以上分组函数都忽略null值 3、可以和distinct搭配实现去重的运算 4、count函数的单独介绍 一般使用count(*)用作统计行数 5、和分组函数一同查询的字段要求是group by后的字段 */ #1、简单 的使用 SELECT SUM(salary) FROM employees; SELECT AVG(salary) FROM employees; SELECT MIN(salary) FROM employees; SELECT MAX(salary) FROM employees; SELECT COUNT(salary) FROM employees; SELECT SUM(salary) 和,AVG(salary) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数 FROM employees; SELECT SUM(salary) 和,ROUND(AVG(salary),2) 平均,MAX(salary) 最高,MIN(salary) 最低,COUNT(salary) 个数 FROM employees; #2、参数支持哪些类型 SELECT SUM(last_name) ,AVG(last_name) FROM employees; SELECT SUM(hiredate) ,AVG(hiredate) FROM employees; SELECT MAX(last_name),MIN(last_name) FROM employees; SELECT MAX(hiredate),MIN(hiredate) FROM employees; SELECT COUNT(commission_pct) FROM employees; SELECT COUNT(last_name) FROM employees; #3、是否忽略null SELECT SUM(commission_pct) ,AVG(commission_pct),SUM(commission_pct)/35,SUM(commission_pct)/107 FROM employees; SELECT MAX(commission_pct) ,MIN(commission_pct) FROM employees; SELECT COUNT(commission_pct) FROM employees; SELECT commission_pct FROM employees; #4、和distinct搭配 SELECT SUM(DISTINCT salary),SUM(salary) FROM employees; SELECT COUNT(DISTINCT salary),COUNT(salary) FROM employees; #5、count函数的详细介绍 SELECT COUNT(salary) FROM employees; SELECT COUNT(*) FROM employees; SELECT COUNT(1) FROM employees; 效率: MYISAM存储引擎下 ,COUNT(*)的效率高 INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)要高一些 #6、和分组函数一同查询的字段有限制 SELECT AVG(salary),employee_id FROM employees;
注:在SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中。
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id ;
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中 。
SELECT AVG(salary) FROM employees GROUP BY department_id ;
在GROUP BY 子句中可以GROUP BY 多个列。并且不可以在where里使用组函数但是可以在having中使用组函数。
/* 语法: select 查询列表 from 表 【where 筛选条件】 group by 分组的字段 【order by 排序的字段】; 特点: 1、和分组函数一同查询的字段必须是group by后出现的字段 2、筛选分为两类:分组前筛选和分组后筛选 针对的表 位置 连接的关键字 分组前筛选 原始表 group by前 where 分组后筛选 group by后的结果集 group by后 having 问题1:分组函数做筛选能不能放在where后面 答:不能 问题2:where——group by——having 一般来讲,能用分组前筛选的,尽量使用分组前筛选,提高效率 3、分组可以按单个字段也可以按多个字段 4、可以搭配着排序使用 */ #引入:查询每个部门的员工个数 SELECT COUNT(*) FROM employees WHERE department_id=90; #1.简单的分组 #案例1:查询每个工种的员工平均工资 SELECT AVG(salary),job_id FROM employees GROUP BY job_id; #案例2:查询每个位置的部门个数 SELECT COUNT(*),location_id FROM departments GROUP BY location_id; #2、可以实现分组前的筛选 #案例1:查询邮箱中包含a字符的 每个部门的最高工资 SELECT MAX(salary),department_id FROM employees WHERE email LIKE '%a%' GROUP BY department_id; #案例2:查询有奖金的每个领导手下员工的平均工资 SELECT AVG(salary),manager_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY manager_id; #3、分组后筛选 #案例:查询哪个部门的员工个数>5 #①查询每个部门的员工个数 SELECT COUNT(*),department_id FROM employees GROUP BY department_id; #② 筛选刚才①结果 SELECT COUNT(*),department_id FROM employees GROUP BY department_id HAVING COUNT(*)>5; #案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资 SELECT job_id,MAX(salary) FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id HAVING MAX(salary)>12000; #案例3:领导编号>102的每个领导手下的最低工资大于5000的领导编号和最低工资 manager_id>102 SELECT manager_id,MIN(salary) FROM employees GROUP BY manager_id HAVING MIN(salary)>5000; #4.添加排序 #案例:每个工种有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序 SELECT job_id,MAX(salary) m FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id HAVING m>6000 ORDER BY m ; #5.按多个字段分组 #案例:查询每个工种每个部门的最低工资,并按最低工资降序 SELECT MIN(salary),job_id,department_id FROM employees GROUP BY department_id,job_id ORDER BY MIN(salary) DESC;
/* 含义:又称多表查询,当查询的字段来自于多个表时,就会用到连接查询 笛卡尔乘积现象:表1 有m行,表2有n行,结果=m*n行 发生原因:没有有效的连接条件 如何避免:添加有效的连接条件 分类: 按年代分类: sql92标准:仅仅支持内连接 sql99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接 按功能分类: 内连接: 等值连接 非等值连接 自连接 外连接: 左外连接 右外连接 全外连接 交叉连接 */ SELECT * FROM beauty; SELECT * FROM boys; SELECT NAME,boyName FROM boys,beauty WHERE beauty.boyfriend_id= boys.id; #一、sql92标准 #1、等值连接 /* ① 多表等值连接的结果为多表的交集部分 ②n表连接,至少需要n-1个连接条件 ③ 多表的顺序没有要求 ④一般需要为表起别名 ⑤可以搭配前面介绍的所有子句使用,比如排序、分组、筛选 */ #案例1:查询女神名和对应的男神名 SELECT NAME,boyName FROM boys,beauty WHERE beauty.boyfriend_id= boys.id; #案例2:查询员工名和对应的部门名 SELECT last_name,department_name FROM employees,departments WHERE employees.`department_id`=departments.`department_id`; #2、为表起别名 /* ①提高语句的简洁度 ②区分多个重名的字段 注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定 */ #查询员工名、工种号、工种名 SELECT e.last_name,e.job_id,j.job_title FROM employees e,jobs j WHERE e.`job_id`=j.`job_id`; #3、两个表的顺序是否可以调换 #查询员工名、工种号、工种名 SELECT e.last_name,e.job_id,j.job_title FROM jobs j,employees e WHERE e.`job_id`=j.`job_id`; #4、可以加筛选 #案例:查询有奖金的员工名、部门名 SELECT last_name,department_name,commission_pct FROM employees e,departments d WHERE e.`department_id`=d.`department_id` AND e.`commission_pct` IS NOT NULL; #案例2:查询城市名中第二个字符为o的部门名和城市名 SELECT department_name,city FROM departments d,locations l WHERE d.`location_id` = l.`location_id` AND city LIKE '_o%'; #5、可以加分组 #案例1:查询每个城市的部门个数 SELECT COUNT(*) 个数,city FROM departments d,locations l WHERE d.`location_id`=l.`location_id` GROUP BY city; #案例2:查询有奖金的每个部门的部门名和部门的领导编号和该部门的最低工资 SELECT department_name,d.`manager_id`,MIN(salary) FROM departments d,employees e WHERE d.`department_id`=e.`department_id` AND commission_pct IS NOT NULL GROUP BY department_name,d.`manager_id`; #6、可以加排序 #案例:查询每个工种的工种名和员工的个数,并且按员工个数降序 SELECT job_title,COUNT(*) FROM employees e,jobs j WHERE e.`job_id`=j.`job_id` GROUP BY job_title ORDER BY COUNT(*) DESC; #7、可以实现三表连接? #案例:查询员工名、部门名和所在的城市 SELECT last_name,department_name,city FROM employees e,departments d,locations l WHERE e.`department_id`=d.`department_id` AND d.`location_id`=l.`location_id` AND city LIKE 's%' ORDER BY department_name DESC; #2、非等值连接 #案例1:查询员工的工资和工资级别 SELECT salary,grade_level FROM employees e,job_grades g WHERE salary BETWEEN g.`lowest_sal` AND g.`highest_sal` AND g.`grade_level`='A'; #3、自连接 #案例:查询 员工名和上级的名称 SELECT e.employee_id,e.last_name,m.employee_id,m.last_name FROM employees e,employees m WHERE e.`manager_id`=m.`employee_id`;
/* 语法: select 查询列表 from 表1 别名 【连接类型】 join 表2 别名 on 连接条件 【where 筛选条件】 【group by 分组】 【having 筛选条件】 【order by 排序列表】 分类: 内连接(★):inner 外连接 左外(★):left 【outer】 右外(★):right 【outer】 全外:full【outer】 交叉连接:cross */ #一)内连接 /* 语法: select 查询列表 from 表1 别名 inner join 表2 别名 on 连接条件; 分类: 等值 非等值 自连接 特点: ①添加排序、分组、筛选 ②inner可以省略 ③ 筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读 ④inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集 */ #1、等值连接 #案例1.查询员工名、部门名 SELECT last_name,department_name FROM departments d JOIN employees e ON e.`department_id` = d.`department_id`; #案例2.查询名字中包含e的员工名和工种名(添加筛选) SELECT last_name,job_title FROM employees e INNER JOIN jobs j ON e.`job_id`= j.`job_id` WHERE e.`last_name` LIKE '%e%'; #3. 查询部门个数>3的城市名和部门个数,(添加分组+筛选) #①查询每个城市的部门个数 #②在①结果上筛选满足条件的 SELECT city,COUNT(*) 部门个数 FROM departments d INNER JOIN locations l ON d.`location_id`=l.`location_id` GROUP BY city HAVING COUNT(*)>3; #案例4.查询哪个部门的员工个数>3的部门名和员工个数,并按个数降序(添加排序) #①查询每个部门的员工个数 SELECT COUNT(*),department_name FROM employees e INNER JOIN departments d ON e.`department_id`=d.`department_id` GROUP BY department_name #② 在①结果上筛选员工个数>3的记录,并排序 SELECT COUNT(*) 个数,department_name FROM employees e INNER JOIN departments d ON e.`department_id`=d.`department_id` GROUP BY department_name HAVING COUNT(*)>3 ORDER BY COUNT(*) DESC; #5.查询员工名、部门名、工种名,并按部门名降序(添加三表连接) SELECT last_name,department_name,job_title FROM employees e INNER JOIN departments d ON e.`department_id`=d.`department_id` INNER JOIN jobs j ON e.`job_id` = j.`job_id` ORDER BY department_name DESC; #二)非等值连接 #查询员工的工资级别 SELECT salary,grade_level FROM employees e JOIN job_grades g ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`; #查询工资级别的个数>20的个数,并且按工资级别降序 SELECT COUNT(*),grade_level FROM employees e JOIN job_grades g ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal` GROUP BY grade_level HAVING COUNT(*)>20 ORDER BY grade_level DESC; #三)自连接 #查询员工的名字、上级的名字 SELECT e.last_name,m.last_name FROM employees e JOIN employees m ON e.`manager_id`= m.`employee_id`; #查询姓名中包含字符k的员工的名字、上级的名字 SELECT e.last_name,m.last_name FROM employees e JOIN employees m ON e.`manager_id`= m.`employee_id` WHERE e.`last_name` LIKE '%k%'; #二、外连接 /* 应用场景:用于查询一个表中有,另一个表没有的记录 特点: 1、外连接的查询结果为主表中的所有记录 如果从表中有和它匹配的,则显示匹配的值 如果从表中没有和它匹配的,则显示null 外连接查询结果=内连接结果+主表中有而从表没有的记录 2、左外连接,left join左边的是主表 右外连接,right join右边的是主表 3、左外和右外交换两个表的顺序,可以实现同样的效果 4、全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的 */ #引入:查询男朋友 不在男神表的的女神名 SELECT * FROM beauty; SELECT * FROM boys; #左外连接 SELECT b.*,bo.* FROM boys bo LEFT OUTER JOIN beauty b ON b.`boyfriend_id` = bo.`id` WHERE b.`id` IS NULL; #案例1:查询哪个部门没有员工 #左外 SELECT d.*,e.employee_id FROM departments d LEFT OUTER JOIN employees e ON d.`department_id` = e.`department_id` WHERE e.`employee_id` IS NULL; #右外 SELECT d.*,e.employee_id FROM employees e RIGHT OUTER JOIN departments d ON d.`department_id` = e.`department_id` WHERE e.`employee_id` IS NULL; #全外 USE girls; SELECT b.*,bo.* FROM beauty b FULL OUTER JOIN boys bo ON b.`boyfriend_id` = bo.id; #交叉连接 SELECT b.*,bo.* FROM beauty b CROSS JOIN boys bo;
七种数据库的外连接模型:

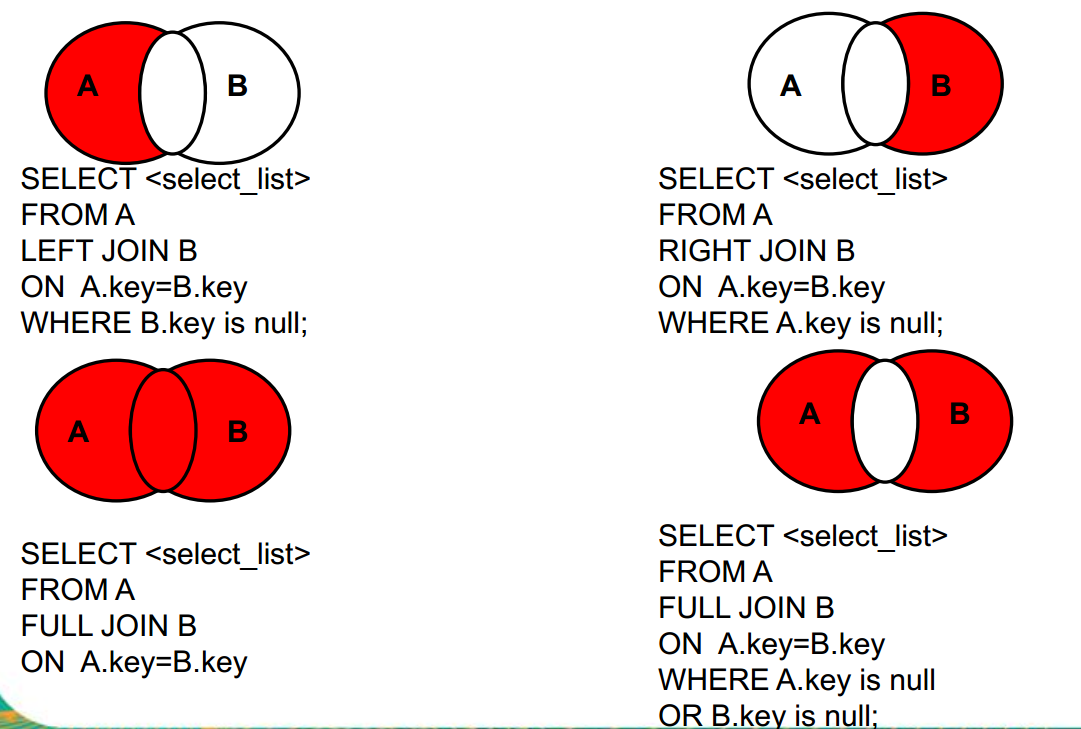
最后两种的full join语法不是我们mysql的语法,在mysql中使用union①与②为全集,⑤与⑥联合为AB特有部分。
/* union 联合 合并:将多条查询语句的结果合并成一个结果 语法: 查询语句1 union 查询语句2 union ... 应用场景: 要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时 特点:★ 1、要求多条查询语句的查询列数是一致的! 2、要求多条查询语句的查询的每一列的类型和顺序最好一致 3、union关键字默认去重,如果使用union all 可以包含重复项 */ #引入的案例:查询部门编号>90或邮箱包含a的员工信息 SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;; SELECT * FROM employees WHERE email LIKE '%a%' UNION SELECT * FROM employees WHERE department_id>90; #案例:查询中国用户中男性的信息以及外国用户中年男性的用户信息 SELECT id,cname FROM t_ca WHERE csex='男' UNION ALL SELECT t_id,tname FROM t_ua WHERE tGender='male';
/* 概念:类似于java的方法,将一组逻辑语句封装在方法体中,对外暴露方法名 好处:1、隐藏了实现细节 2、提高代码的重用性 调用:select 函数名(实参列表) 【from 表】; 特点: ①叫什么(函数名) ②干什么(函数功能) 分类: 1、单行函数 如 concat、length、ifnull等 2、分组函数 功能:做统计使用,又称为统计函数、聚合函数、组函数 常见函数: 一、单行函数 字符函数: length:获取字节个数(utf-8一个汉字代表3个字节,gbk为2个字节) concat substr instr trim upper lower lpad rpad replace 数学函数: round ceil floor truncate mod 日期函数: now curdate curtime year month monthname day hour minute second str_to_date date_format 其他函数: version database user 控制函数 if case */ #一、字符函数 #1.length 获取参数值的字节个数 SELECT LENGTH('john'); SELECT LENGTH('张三丰hahaha'); SHOW VARIABLES LIKE '%char%' #2.concat 拼接字符串 SELECT CONCAT(last_name,'_',first_name) 姓名 FROM employees; #3.upper、lower SELECT UPPER('john'); SELECT LOWER('joHn'); #示例:将姓变大写,名变小写,然后拼接 SELECT CONCAT(UPPER(last_name),LOWER(first_name)) 姓名 FROM employees; #4.substr、substring 注意:索引从1开始 #截取从指定索引处后面所有字符 SELECT SUBSTR('李莫愁爱上了陆展元',7) out_put; #截取从指定索引处指定字符长度的字符 SELECT SUBSTR('李莫愁爱上了陆展元',1,3) out_put; #案例:姓名中首字符大写,其他字符小写然后用_拼接,显示出来 SELECT CONCAT(UPPER(SUBSTR(last_name,1,1)),'_',LOWER(SUBSTR(last_name,2))) out_put FROM employees; #5.instr 返回子串第一次出现的索引,如果找不到返回0 SELECT INSTR('杨不殷六侠悔爱上了殷六侠','殷八侠') AS out_put; #6.trim SELECT LENGTH(TRIM(' 张翠山 ')) AS out_put; SELECT TRIM('aa' FROM 'aaaaaaaaa张aaaaaaaaaaaa翠山aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa') AS out_put; #7.lpad 用指定的字符实现左填充指定长度 SELECT LPAD('殷素素',2,'*') AS out_put; #8.rpad 用指定的字符实现右填充指定长度 SELECT RPAD('殷素素',12,'ab') AS out_put; #9.replace 替换 SELECT REPLACE('周芷若周芷若周芷若周芷若张无忌爱上了周芷若','周芷若','赵敏') AS out_put; 全都替换 #二、数学函数 #round 四舍五入 SELECT ROUND(-1.55); SELECT ROUND(1.567,2); #ceil 向上取整,返回>=该参数的最小整数 SELECT CEIL(-1.02); #floor 向下取整,返回<=该参数的最大整数 SELECT FLOOR(-9.99); #truncate 截断 SELECT TRUNCATE(1.69999,1); #mod取余 /* mod(a,b) : a-a/b*b mod(-10,-3):-10- (-10)/(-3)*(-3)=-1 */ SELECT MOD(10,-3); SELECT 10%3; #三、日期函数 #now 返回当前系统日期+时间 SELECT NOW(); #curdate 返回当前系统日期,不包含时间 SELECT CURDATE(); #curtime 返回当前时间,不包含日期 SELECT CURTIME(); #可以获取指定的部分,年、月、日、小时、分钟、秒 SELECT YEAR(NOW()) 年; SELECT YEAR('1998-1-1') 年; SELECT YEAR(hiredate) 年 FROM employees; SELECT MONTH(NOW()) 月; SELECT MONTHNAME(NOW()) 月; #str_to_date 将字符通过指定的格式转换成日期 SELECT STR_TO_DATE('1998-3-2','%Y-%c-%d') AS out_put; #查询入职日期为1992--4-3的员工信息 SELECT * FROM employees WHERE hiredate = '1992-4-3'; SELECT * FROM employees WHERE hiredate = STR_TO_DATE('4-3 1992','%c-%d %Y'); #date_format 将日期转换成字符 SELECT DATE_FORMAT(NOW(),'%y年%m月%d日') AS out_put; #查询有奖金的员工名和入职日期(xx月/xx日 xx年) SELECT last_name,DATE_FORMAT(hiredate,'%m月/%d日 %y年') 入职日期 FROM employees WHERE commission_pct IS NOT NULL; #四、其他函数 SELECT VERSION(); SELECT DATABASE(); SELECT USER(); #五、流程控制函数 #1.if函数: if else 的效果 SELECT IF(10<5,'大','小'); SELECT last_name,commission_pct,IF(commission_pct IS NULL,'没奖金,呵呵','有奖金,嘻嘻') 备注 FROM employees; #2.case函数的使用一: switch case 的效果 /* java中 switch(变量或表达式){ case 常量1:语句1;break; ... default:语句n;break; } mysql中 case 要判断的字段或表达式 when 常量1 then 要显示的值1或语句1; when 常量2 then 要显示的值2或语句2; ... else 要显示的值n或语句n; end */ /*案例:查询员工的工资,要求 部门号=30,显示的工资为1.1倍 部门号=40,显示的工资为1.2倍 部门号=50,显示的工资为1.3倍 其他部门,显示的工资为原工资 */ SELECT salary 原始工资,department_id, CASE department_id WHEN 30 THEN salary*1.1 WHEN 40 THEN salary*1.2 WHEN 50 THEN salary*1.3 ELSE salary END AS 新工资 FROM employees; #3.case 函数的使用二:类似于 多重if /* java中: if(条件1){ 语句1; }else if(条件2){ 语句2; } ... else{ 语句n; } mysql中: case when 条件1 then 要显示的值1或语句1 when 条件2 then 要显示的值2或语句2 。。。 else 要显示的值n或语句n end */ #案例:查询员工的工资的情况 如果工资>20000,显示A级别 如果工资>15000,显示B级别 如果工资>10000,显示C级别 否则,显示D级别 SELECT salary, CASE WHEN salary>20000 THEN 'A' WHEN salary>15000 THEN 'B' WHEN salary>10000 THEN 'C' ELSE 'D' END AS 工资级别 FROM employees;
/* 应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求 语法: select 查询列表 from 表 【join type join 表2 on 连接条件 where 筛选条件 group by 分组字段 having 分组后的筛选 order by 排序的字段】 limit 【offset,】size; offset要显示条目的起始索引(起始索引从0开始) size 要显示的条目个数 特点: ①limit语句放在查询语句的最后 ②公式 要显示的页数 page,每页的条目数size select 查询列表 from 表 limit (page-1)*size,size; size=10 page 1 0 2 10 3 20 */ #案例1:查询前五条员工信息 SELECT * FROM employees LIMIT 0,5; SELECT * FROM employees LIMIT 5; #案例2:查询第11条——第25条 SELECT * FROM employees LIMIT 10,15; #案例3:有奖金的员工信息,并且工资较高的前10名显示出来 SELECT * FROM employees WHERE commission_pct IS NOT NULL ORDER BY salary DESC LIMIT 10 ;
如果再增加表时未设置字符编码,插入中文时会出现编码错误无法插入的情况。
alter table t1 charset utf8; #修改表t1的编码 --此时任然无法插入中文,因为表的编码改变了,但是name字段还需要重新定义才可以 alter table t1 modify name varchar(20); 这样就可以插入中文了。
为避免这种现象的出现,最好把数据库的编码改成utf8,这样在这个数据库下创建表时,都默认utf8编码了。
查询的补充:
关键字distinct可以查询不重复的记录。
select distinct xxx from table;查询结果去重
聚合:
语法:select [column_name1,colun_name2,...] fun_name from tablename [where condition] [group by column_name1,colun_name2,...[with rollup] [having where condition]] fun_name:表示聚合操作,也就是聚合函数,常用的有sum(求和),count(计数),max(最大值),min(最小值) group by:要进行分类聚合的字段 with rollup:表明是否对分类聚合后的结果进行再汇总 having:表示对分类后的结果再进行过滤
子查询:
子查询的关键字:in、not in、=、!=、exists、not exists、between ... and ...;
比较运算符
mysql> select * from students; +----+-----------+----------+ | id | name | class_id | +----+-----------+----------+ | 1 | jeff | 1 | | 2 | franklike | 3 | | 4 | xixilove | 16 | +----+-----------+----------+ mysql> select * from students where id>3; +----+----------+----------+ | id | name | class_id | +----+----------+----------+ | 4 | xixilove | 16 | +----+----------+----------+ mysql> select * from students where id<=3; +----+-----------+----------+ | id | name | class_id | +----+-----------+----------+ | 1 | jeff | 1 | | 2 | franklike | 3 | +----+-----------+----------+ mysql> select * from students where name!='jeff'; +----+-----------+----------+ | id | name | class_id | +----+-----------+----------+ | 2 | franklike | 3 | | 4 | xixilove | 16 | +----+-----------+----------+
除此之外还有逻辑运算符(and,or,not),模糊查询like,%(任意多字符),_(任意一个字符)。
and比or先运算,如果同时出现并希望先算or,需要结合()使用
/* 含义: 出现在其他语句中的select语句,称为子查询或内查询 外部的查询语句,称为主查询或外查询 分类: 按子查询出现的位置: select后面: 仅仅支持标量子查询 from后面: 支持表子查询 where或having后面:★ 标量子查询(单行) √ 列子查询 (多行) √ 行子查询 exists后面(相关子查询) 表子查询 按结果集的行列数不同: 标量子查询(结果集只有一行一列) 列子查询(结果集只有一列多行) 行子查询(结果集有一行多列) 表子查询(结果集一般为多行多列) */ #一、where或having后面 /* 1、标量子查询(单行子查询) 2、列子查询(多行子查询) 3、行子查询(多列多行) 特点: ①子查询放在小括号内 ②子查询一般放在条件的右侧 ③标量子查询,一般搭配着单行操作符使用 > < >= <= = <> 列子查询,一般搭配着多行操作符使用 in、any/some、all ④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果 */ #1.标量子查询★ #案例1:谁的工资比 Abel 高? #①查询Abel的工资 SELECT salary FROM employees WHERE last_name = 'Abel' #②查询员工的信息,满足 salary>①结果 SELECT * FROM employees WHERE salary>( SELECT salary FROM employees WHERE last_name = 'Abel' ); #案例2:返回job_id与141号员工相同,salary比143号员工多的员工 姓名,job_id 和工资 #①查询141号员工的job_id SELECT job_id FROM employees WHERE employee_id = 141 #②查询143号员工的salary SELECT salary FROM employees WHERE employee_id = 143 #③查询员工的姓名,job_id 和工资,要求job_id=①并且salary>② SELECT last_name,job_id,salary FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 ) AND salary>( SELECT salary FROM employees WHERE employee_id = 143 ); #案例3:返回公司工资最少的员工的last_name,job_id和salary #①查询公司的 最低工资 SELECT MIN(salary) FROM employees #②查询last_name,job_id和salary,要求salary=① SELECT last_name,job_id,salary FROM employees WHERE salary=( SELECT MIN(salary) FROM employees ); #案例4:查询最低工资大于50号部门最低工资的部门id和其最低工资 #①查询50号部门的最低工资 SELECT MIN(salary) FROM employees WHERE department_id = 50 #②查询每个部门的最低工资 SELECT MIN(salary),department_id FROM employees GROUP BY department_id #③ 在②基础上筛选,满足min(salary)>① SELECT MIN(salary),department_id FROM employees GROUP BY department_id HAVING MIN(salary)>( SELECT MIN(salary) FROM employees WHERE department_id = 50 ); #非法使用标量子查询 SELECT MIN(salary),department_id FROM employees GROUP BY department_id HAVING MIN(salary)>( SELECT salary FROM employees WHERE department_id = 250 ); #2.列子查询(多行子查询)★ #案例1:返回location_id是1400或1700的部门中的所有员工姓名 #①查询location_id是1400或1700的部门编号 SELECT DISTINCT department_id FROM departments WHERE location_id IN(1400,1700) #②查询员工姓名,要求部门号是①列表中的某一个 SELECT last_name FROM employees WHERE department_id <>ALL( SELECT DISTINCT department_id FROM departments WHERE location_id IN(1400,1700) ); #案例2:返回其它工种中比job_id为‘IT_PROG’工种任一工资低的员工的员工号、姓名、job_id 以及salary #①查询job_id为‘IT_PROG’部门任一工资 SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' #②查询员工号、姓名、job_id 以及salary,salary<(①)的任意一个 SELECT last_name,employee_id,job_id,salary FROM employees WHERE salary<ANY( SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' ) AND job_id<>'IT_PROG'; #或 SELECT last_name,employee_id,job_id,salary FROM employees WHERE salary<( SELECT MAX(salary) FROM employees WHERE job_id = 'IT_PROG' ) AND job_id<>'IT_PROG'; #案例3:返回其它部门中比job_id为‘IT_PROG’部门所有工资都低的员工 的员工号、姓名、job_id 以及salary SELECT last_name,employee_id,job_id,salary FROM employees WHERE salary<ALL( SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' ) AND job_id<>'IT_PROG'; #或 SELECT last_name,employee_id,job_id,salary FROM employees WHERE salary<( SELECT MIN( salary) FROM employees WHERE job_id = 'IT_PROG' ) AND job_id<>'IT_PROG'; #3、行子查询(结果集一行多列或多行多列) #案例:查询员工编号最小并且工资最高的员工信息 SELECT * FROM employees WHERE (employee_id,salary)=( SELECT MIN(employee_id),MAX(salary) FROM employees ); #①查询最小的员工编号 SELECT MIN(employee_id) FROM employees #②查询最高工资 SELECT MAX(salary) FROM employees #③查询员工信息 SELECT * FROM employees WHERE employee_id=( SELECT MIN(employee_id) FROM employees )AND salary=( SELECT MAX(salary) FROM employees ); #二、select后面 /* 仅仅支持标量子查询 */ #案例:查询每个部门的员工个数 SELECT d.*,( SELECT COUNT(*) FROM employees e WHERE e.department_id = d.`department_id` ) 个数 FROM departments d; #案例2:查询员工号=102的部门名 SELECT ( SELECT department_name,e.department_id FROM departments d INNER JOIN employees e ON d.department_id=e.department_id WHERE e.employee_id=102 ) 部门名; #三、from后面 /* 将子查询结果充当一张表,要求必须起别名 */ #案例:查询每个部门的平均工资的工资等级 #①查询每个部门的平均工资 SELECT AVG(salary),department_id FROM employees GROUP BY department_id SELECT * FROM job_grades; #②连接①的结果集和job_grades表,筛选条件平均工资 between lowest_sal and highest_sal SELECT ag_dep.*,g.`grade_level` FROM ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep INNER JOIN job_grades g ON ag_dep.ag BETWEEN lowest_sal AND highest_sal; #四、exists后面(相关子查询) /* 语法: exists(完整的查询语句) 结果: 1或0 */ SELECT EXISTS(SELECT employee_id FROM employees WHERE salary=300000); #案例1:查询有员工的部门名 #in SELECT department_name FROM departments d WHERE d.`department_id` IN( SELECT department_id FROM employees ) #exists SELECT department_name FROM departments d WHERE EXISTS( SELECT * FROM employees e WHERE d.`department_id`=e.`department_id` ); #案例2:查询没有女朋友的男神信息 #in SELECT bo.* FROM boys bo WHERE bo.id NOT IN( SELECT boyfriend_id FROM beauty ) #exists SELECT bo.* FROM boys bo WHERE NOT EXISTS( SELECT boyfriend_id FROM beauty b WHERE bo.`id`=b.`boyfriend_id` );
# 1. 查询工资最低的员工信息: last_name, salary #①查询最低的工资 SELECT MIN(salary) FROM employees #②查询last_name,salary,要求salary=① SELECT last_name,salary FROM employees WHERE salary=( SELECT MIN(salary) FROM employees ); # 2. 查询平均工资最低的部门信息 #方式一: #①各部门的平均工资 SELECT AVG(salary),department_id FROM employees GROUP BY department_id #②查询①结果上的最低平均工资 SELECT MIN(ag) FROM ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep #③查询哪个部门的平均工资=② SELECT AVG(salary),department_id FROM employees GROUP BY department_id HAVING AVG(salary)=( SELECT MIN(ag) FROM ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep ); #④查询部门信息 SELECT d.* FROM departments d WHERE d.`department_id`=( SELECT department_id FROM employees GROUP BY department_id HAVING AVG(salary)=( SELECT MIN(ag) FROM ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ) ag_dep ) ); #方式二: #①各部门的平均工资 SELECT AVG(salary),department_id FROM employees GROUP BY department_id #②求出最低平均工资的部门编号 SELECT department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) LIMIT 1; #③查询部门信息 SELECT * FROM departments WHERE department_id=( SELECT department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) LIMIT 1 ); # 3. 查询平均工资最低的部门信息和该部门的平均工资 #①各部门的平均工资 SELECT AVG(salary),department_id FROM employees GROUP BY department_id #②求出最低平均工资的部门编号 SELECT AVG(salary),department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) LIMIT 1; #③查询部门信息 SELECT d.*,ag FROM departments d JOIN ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) LIMIT 1 ) ag_dep ON d.`department_id`=ag_dep.department_id; # 4. 查询平均工资最高的 job 信息 #①查询最高的job的平均工资 SELECT AVG(salary),job_id FROM employees GROUP BY job_id ORDER BY AVG(salary) DESC LIMIT 1 #②查询job信息 SELECT * FROM jobs WHERE job_id=( SELECT job_id FROM employees GROUP BY job_id ORDER BY AVG(salary) DESC LIMIT 1 ); # 5. 查询平均工资高于公司平均工资的部门有哪些? #①查询平均工资 SELECT AVG(salary) FROM employees #②查询每个部门的平均工资 SELECT AVG(salary),department_id FROM employees GROUP BY department_id #③筛选②结果集,满足平均工资>① SELECT AVG(salary),department_id FROM employees GROUP BY department_id HAVING AVG(salary)>( SELECT AVG(salary) FROM employees ); # 6. 查询出公司中所有 manager 的详细信息. #①查询所有manager的员工编号 SELECT DISTINCT manager_id FROM employees #②查询详细信息,满足employee_id=① SELECT * FROM employees WHERE employee_id =ANY( SELECT DISTINCT manager_id FROM employees ); # 7. 各个部门中 最高工资中最低的那个部门的 最低工资是多少 #①查询各部门的最高工资中最低的部门编号 SELECT department_id FROM employees GROUP BY department_id ORDER BY MAX(salary) LIMIT 1 #②查询①结果的那个部门的最低工资 SELECT MIN(salary) ,department_id FROM employees WHERE department_id=( SELECT department_id FROM employees GROUP BY department_id ORDER BY MAX(salary) LIMIT 1 ); # 8. 查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary #①查询平均工资最高的部门编号 SELECT department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) DESC LIMIT 1 #②将employees和departments连接查询,筛选条件是① SELECT last_name, d.department_id, email, salary FROM employees e INNER JOIN departments d ON d.manager_id = e.employee_id WHERE d.department_id = (SELECT department_id FROM employees GROUP BY department_id ORDER BY AVG(salary) DESC LIMIT 1) ;
外键是一个特殊的索引,只能是指定内容。
create table userinfo( uid bigint auto_increment primary key, name varchar(32), department_id int, constraint fk_user_depar foreign key (department_id) references department(id) )engine=innodb default charset=utf8; create table department( id bigint auto_increment primary key, title char(15))engine=innodb default charset=utf8;
唯一索引,索引的目的都是为了加快查找,唯一索引的引入一方面是为了约束不能重复,另一方面就是加速查找,与主键不同的是,唯一索引虽然不能重复但是可以为空,但是主键不能为空。
unique 唯一索引名称 (列名,列名),
外键的变种,表与表之间的关系可以是一对多,一对一,多对一和多对多。
示例:
create table userinfo1( id int auto_increment primary key, name char(10), gender char(10), email varchar(64) )engine=innodb default charset=utf8; create table admin( id int not null auto_increment primary key, username varchar(64) not null, password VARCHAR(64) not null, user_id int not null, unique uq_u1 (user_id), CONSTRAINT fk_admin_u1 FOREIGN key (user_id) REFERENCES userinfo1(id) )engine=innodb default charset=utf8;
create table userinfo2(
id int auto_increment primary key,
name char(10),
gender char(10),
email varchar(64)
)engine=innodb default charset=utf8;--这里是操作电脑的用户的表
create table host(
id int auto_increment primary key,
hostname char(64)
)engine=innodb default charset=utf8;--这里是存在的电脑的表
create table user2host(
id int auto_increment primary key,
userid int not null,
hostid int not null,
unique uq_user_host (userid,hostid),--每个人对一台电脑的操作权都只需要出现一次,所以加上唯一索引
CONSTRAINT fk_u2h_user FOREIGN key (userid) REFERENCES userinfo2(id),--外键约束
CONSTRAINT fk_u2h_host FOREIGN key (hostid) REFERENCES host(id)
)engine=innodb default charset=utf8;
补充一个临时表。临时表只暂存在内存中。
mysql> select cid from (select * from course left join teacher on course.teach_id = teacher.tid) as n; +-----+ | cid | +-----+ | 1 | | 2 | | 3 | +-----+
在这里还要补充一下关键字优先级。
from>where>group by>having>select>distinct>order by>limit。
1.找到表:from;
2.按条件过滤表记录:where(过滤的结果是一条条记录);
3.将查出的结果按条件分组:group by;
4.将分组的结果再次过滤:having(与where相同之处是都可以进行过滤,不同之处是having是基于分组之后的结果进行过滤,过滤的结果也是一个个的组);
5.查出结果:select;
6.去重;
7.将6的结果按条件排序:order by;
8.将7的结果限制显示条数。
外键:
节省空间,方便修改(相对于枚举来说)
create table userinfo( uid bigint auto_increment primary key, name varchar(32), department_id int, xx_id int,--这个id就是外键,他指向另外一张表 constraint fk_user_depar foreign key (department_id) references color(id)--这个是约束关系,外键只能是另一张表的id )engine=innodb default charset=utf8; create table department( id bigint auto_increment primary key, title char(15) )engine=innodb default charset=utf8;
pymysql模块
我们可以使用pymysql来MySQL数据库的连接,并实现数据库的各种操作。
首先我们要知道怎么使用pymysql来连接我们的数据库。
create database dbforpymysql; create table userinfo(id int not null auto_increment primary key,username varchar(10),passwd varchar(10))engine=innodb default charset=utf8; insert into userinfo(username,passwd) values('frank','123'),('rose','321'),('jeff','666'); mysql> select * from userinfo; +----+----------+--------+ | id | username | passwd | +----+----------+--------+ | 1 | frank | 123 | | 2 | rose | 321 | | 3 | jeff | 666 | +----+----------+--------+
#-*-coding=utf-8-*- import pymysql #连接数据库db就是conn db = pymysql.connect("localhost","jeff","jeff@123","dbforpymysql") #使用cursor()方法创建一个游标对象 cursor = db.cursor() #使用execute()方法执行SQL语句 cursor.execute("SELECT * FROM userinfo;") #使用fetall()获取全部数据 data = cursor.fetchall() #打印获取到的数据 print(data) #关闭游标和数据库的连接 cursor.close() db.close()
def __init__(self, host=None, user=None, password="", database=None, port=0, unix_socket=None, charset='', sql_mode=None, read_default_file=None, conv=None, use_unicode=None, client_flag=0, cursorclass=Cursor, init_command=None, connect_timeout=10, ssl=None, read_default_group=None, compress=None, named_pipe=None, no_delay=None, autocommit=False, db=None, passwd=None, local_infile=False, max_allowed_packet=16*1024*1024, defer_connect=False, auth_plugin_map={}, read_timeout=None, write_timeout=None, bind_address=None): #参数解释: host: Host where the database server is located #主机名或者主机地址 user: Username to log in as #用户名 password: Password to use. #密码 database: Database to use, None to not use a particular one. #指定的数据库 port: MySQL port to use, default is usually OK. (default: 3306) #端口,默认是3306 bind_address: When the client has multiple network interfaces, specify the interface from which to connect to the host. Argument can be a hostname or an IP address. #当客户端有多个网络接口的时候,指点连接到数据库的接口,可以是一个主机名或者ip地址 unix_socket: Optionally, you can use a unix socket rather than TCP/IP. charset: Charset you want to use. #指定字符编码 sql_mode: Default SQL_MODE to use. read_default_file: Specifies my.cnf file to read these parameters from under the [client] section. conv: Conversion dictionary to use instead of the default one. This is used to provide custom marshalling and unmarshaling of types. See converters. use_unicode: Whether or not to default to unicode strings. This option defaults to true for Py3k. client_flag: Custom flags to send to MySQL. Find potential values in constants.CLIENT. cursorclass: Custom cursor class to use. init_command: Initial SQL statement to run when connection is established. connect_timeout: Timeout before throwing an exception when connecting. (default: 10, min: 1, max: 31536000) ssl: A dict of arguments similar to mysql_ssl_set()'s parameters. For now the capath and cipher arguments are not supported. read_default_group: Group to read from in the configuration file. compress; Not supported named_pipe: Not supported autocommit: Autocommit mode. None means use server default. (default: False) local_infile: Boolean to enable the use of LOAD DATA LOCAL command. (default: False) max_allowed_packet: Max size of packet sent to server in bytes. (default: 16MB) Only used to limit size of "LOAD LOCAL INFILE" data packet smaller than default (16KB). defer_connect: Don't explicitly connect on contruction - wait for connect call. (default: False) auth_plugin_map: A dict of plugin names to a class that processes that plugin. The class will take the Connection object as the argument to the constructor. The class needs an authenticate method taking an authentication packet as an argument. For the dialog plugin, a prompt(echo, prompt) method can be used (if no authenticate method) for returning a string from the user. (experimental) db: Alias for database. (for compatibility to MySQLdb) passwd: Alias for password. (for compatibility to MySQLdb)
#-*-coding=utf-8-*- import pymysql user = input("username:") pwd = input("password:") conn = pymysql.connect(host="localhost",user='jeff',password='jeff@123',database="dbforpymysql") cursor = conn.cursor()#操作数据需要使用这个,链接是通道,他就是操作的手 sql = "select * from userinfo where username='%s' and passwd='%s'" %(user,pwd,)#这个方法是错误的,会造成sql注入 # select * from userinfo where username='uu' or 1=1 -- ' and password='%s' cursor.execute(sql) result = cursor.fetchone()#只拿第一条的查询结果 cursor.close() conn.close() if result: print('登录成功') else: print('登录失败')
#-*-coding=utf-8-*- import pymysql user = input("username:") pwd = input("password:") conn = pymysql.connect(host="localhost",user='jeff',password='jeff@123',database="dbforpymysql") cursor = conn.cursor()#操作数据需要使用这个,链接是通道,他就是操作的手 sql = "select * from userinfo where username= %s and passwd= %s" #这里的字符串占位符不需要加引号 # select * from userinfo where username='uu' or 1=1 -- ' and password='%s' cursor.execute(sql,[user,pwd])#这里的excute只能接受2或3个参数,所以账户信息需要使用列表传入 result = cursor.fetchone()#只拿第一条的查询结果 cursor.close() conn.close() if result: print('登录成功') else: print('登录失败')
使用pymysql进行增删改查
在pymysql的操作中增删改对数据库进行了改动操作,我们必须要进行提交的操作。
commit()方法:在数据库里增、删、改的时候,必须要进行提交,否则插入的数据不生效。
import pymysql config={ "host":"127.0.0.1", "user":"jeff", "password":"jeff@123", "database":"dbforpymysql" } db = pymysql.connect(**config) cursor = db.cursor() sql = "INSERT INTO userinfo(username,passwd) VALUES('jack','123')" cursor.execute(sql) db.commit() #提交数据 cursor.close() db.close() #或者在execute提供插入的数据 import pymysql config={ "host":"127.0.0.1", "user":"jeff", "password":"jeff@123", "database":"dbforpymysql" } db = pymysql.connect(**config) cursor = db.cursor() sql = "INSERT INTO userinfo(username,passwd) VALUES(%s,%s)" cursor.execute(sql,("bob","123")) db.commit() #提交数据 cursor.close() db.close() #再或者添加多行信息 import pymysql config={ "host":"127.0.0.1", "user":"jeff", "password":"jeff@123", "database":"dbforpymysql" } db = pymysql.connect(**config) cursor = db.cursor() sql = "INSERT INTO userinfo(username,passwd) VALUES(%s,%s)" cursor.executemany(sql,[("tom","123"),('tony','123')]) db.commit() #提交数据 cursor.close() db.close()
execute()和executemany()都会返回受影响的行数:
import pymysql config={ "host":"127.0.0.1", "user":"jeff", "password":"jeff@123", "database":"dbforpymysql" } db = pymysql.connect(**config) cursor = db.cursor() sql = "delete from userinfo where username=%s" r=cursor.executemany(sql,("toff",'ton')) print(r) db.commit() #提交数据 print(r) cursor.close() db.close() #这两个r都是2
调用游标的lastrowid可以获取最后一次自增的ID。
print("the last rowid is ",cursor.lastrowid) #the last rowid is 10
pymysql的查操作
查操作主要是三种绑定方法。
fetchone():获取下一行数据,第一次为首行;
fetchall():获取所有行数据源
fetchmany(4):获取下4行数据
fetchone和python中的迭代器取值很相似每次都取出一行数据。
fetchall类似于文件的读取操作,一次取出所有数据,第二次执行取不到值。
默认情况下,我们获取到的返回值是元组,只能看到每行的数据,却不知道每一列代表的是什么,这个时候可以使用以下方式来返回字典,每一行的数据都会生成一个字典:
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) #在实例化的时候,将属性cursor设置为pymysql.cursors.DictCursor
使用fetchall获取所有行的数据,每一行都被生成一个字典放在列表里面:
import pymysql config={ "host":"127.0.0.1", "user":"jeff", "password":"jeff@123", "database":"dbforpymysql" } db = pymysql.connect(**config) cursor = db.cursor(cursor=pymysql.cursors.DictCursor) #在实例化的时候,将属性cursor设置为pymysql.cursors.DictCursor sql = "select * from userinfo" cursor.execute(sql) data=cursor.fetchall() print(data) cursor.close() db.close() 输出结果: [{'id': 1, 'username': 'frank', 'passwd': '123'}, {'id': 2, 'username': 'rose', 'passwd': '321'}, 。。。
和读取文件时的seek一样,取值的时候也可以移动取值位置。
cursor.scroll(1,mode='relative') # 相对当前位置移动 cursor.scroll(2,mode='absolute') # 相对绝对位置移动 第一个值为移动的行数,整数为向下移动,负数为向上移动,mode指定了是相对当前位置移动,还是相对于首行移动
数据库的操作也可以使用上下文管理:
with db.cursor(cursor=pymysql.cursors.DictCursor) as cursor: #获取数据库连接的对象 sql = "SELECT * FROM userinfo" cursor.execute(sql) res = cursor.fetchone() print(res) cursor.scroll(2,mode='relative') res = cursor.fetchone() print(res) cursor.close() db.close()
MySQL多表查询
创建测试数据库。
#建表 create table department( id int, name varchar(20) ); create table employee( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into department values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into employee(name,sex,age,dep_id) values ('egon','male',18,200), ('alex','female',48,201), ('wupeiqi','male',38,201), ('yuanhao','female',28,202), ('liwenzhou','male',18,200), ('jingliyang','female',18,204) ; #查看表结构和数据 mysql> desc department; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ mysql> desc employee; +--------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | sex | enum('male','female') | NO | | male | | | age | int(11) | YES | | NULL | | | dep_id | int(11) | YES | | NULL | | +--------+-----------------------+------+-----+---------+----------------+ mysql> select * from department; +------+--------------+ | id | name | +------+--------------+ | 200 | 技术 | | 201 | 人力资源 | | 202 | 销售 | | 203 | 运营 | +------+--------------+ mysql> select * from employee; +----+------------+--------+------+--------+ | id | name | sex | age | dep_id | +----+------------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | liwenzhou | male | 18 | 200 | | 6 | jingliyang | female | 18 | 204 | +----+------------+--------+------+--------+
多表连接查询。
外链接语法 SELECT 字段列表 FROM 表1 INNER|LEFT|RIGHT JOIN 表2 ON 表1.字段 = 表2.字段;
交叉连接:不适用任何匹配条件。生成笛卡尔积。
mysql> select * from employee,department; +----+------------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+------------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 1 | egon | male | 18 | 200 | 201 | 人力资源 | | 1 | egon | male | 18 | 200 | 202 | 销售 | | 1 | egon | male | 18 | 200 | 203 | 运营 | | 2 | alex | female | 48 | 201 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 2 | alex | female | 48 | 201 | 202 | 销售 | | 2 | alex | female | 48 | 201 | 203 | 运营 | | 3 | wupeiqi | male | 38 | 201 | 200 | 技术 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 202 | 销售 | | 3 | wupeiqi | male | 38 | 201 | 203 | 运营 | | 4 | yuanhao | female | 28 | 202 | 200 | 技术 | | 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 4 | yuanhao | female | 28 | 202 | 203 | 运营 | | 5 | liwenzhou | male | 18 | 200 | 200 | 技术 | | 5 | liwenzhou | male | 18 | 200 | 201 | 人力资源 | | 5 | liwenzhou | male | 18 | 200 | 202 | 销售 | | 5 | liwenzhou | male | 18 | 200 | 203 | 运营 | | 6 | jingliyang | female | 18 | 204 | 200 | 技术 | | 6 | jingliyang | female | 18 | 204 | 201 | 人力资源 | | 6 | jingliyang | female | 18 | 204 | 202 | 销售 | | 6 | jingliyang | female | 18 | 204 | 203 | 运营 | +----+------------+--------+------+--------+------+--------------+
内连接:只连接匹配的行,找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出了正确的结果。
mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id; +----+-----------+------+--------+--------------+ | id | name | age | sex | name | +----+-----------+------+--------+--------------+ | 1 | egon | 18 | male | 技术 | | 2 | alex | 48 | female | 人力资源 | | 3 | wupeiqi | 38 | male | 人力资源 | | 4 | yuanhao | 28 | female | 销售 | | 5 | liwenzhou | 18 | male | 技术 | +----+-----------+------+--------+--------------+ #上述sql等同于 mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id;
外链接之左连接:优先显示左表全部记录,以左表为准,即找出所有员工信息,当然包括没有部门的员工。本质就是:在内连接的基础上增加左边有右边没有的结果。
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id; +----+------------+--------------+ | id | name | depart_name | +----+------------+--------------+ | 1 | egon | 技术 | | 5 | liwenzhou | 技术 | | 2 | alex | 人力资源 | | 3 | wupeiqi | 人力资源 | | 4 | yuanhao | 销售 | | 6 | jingliyang | NULL | +----+------------+--------------+
同理可得右连接,通常知道左连接就可以了,要使用右连接把两张表倒置就可以得到一样的结果了。
全外连接:显示左右两个表全部记录,在内连接的基础上增加左边有右边没有的和右边有左边没有的结果。在MySQL中使用union完成全外连接。
select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id ; #查看结果 +------+------------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+------------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 5 | liwenzhou | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 6 | jingliyang | female | 18 | 204 | NULL | NULL | | NULL | NULL | NULL | NULL | NULL | 203 | 运营 | +------+------------+--------+------+--------+------+--------------+ #注意 union与union all的区别:union会去掉相同的纪录
子查询相关
关于子查询的几个概念:
1.子查询是将一个查询语句嵌套在另一个查询语句中。
2.内层查询语句的查询结果,可以为外层查询语句提供查询条件。
3.子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字。
4.还可以包含比较运算符:= 、 !=、> 、<等。
#查询employee表,但dep_id必须在department表中出现过 select * from employee where dep_id in (select id from department);
#比较运算符:=、!=、>、>=、<、<=、<> #查询平均年龄在25岁以上的部门名 select id,name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25); #查看技术部员工姓名 select name from employee where dep_id in (select id from department where name='技术'); #查看不足1人的部门名 select name from department where id in (select dep_id from employee group by dep_id having count(id) <=1);
#EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。 而是返回一个真假值。True或False #当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询 #department表中存在dept_id=203,Ture mysql> select * from employee -> where exists -> (select id from department where id=200); +----+------------+--------+------+--------+ | id | name | sex | age | dep_id | +----+------------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | liwenzhou | male | 18 | 200 | | 6 | jingliyang | female | 18 | 204 | +----+------------+--------+------+--------+ #department表中存在dept_id=205,False mysql> select * from employee -> where exists -> (select id from department where id=204); Empty set (0.00 sec)
mysql的数据类型
/* 数值型: 整型 小数: 定点数 浮点数 字符型: 较短的文本:char、varchar 较长的文本:text、blob(较长的二进制数据) 日期型: */ #一、整型 /* 分类: tinyint、smallint、mediumint、int/integer、bigint 1 2 3 4 8 特点: ① 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加unsigned关键字 ② 如果插入的数值超出了整型的范围,会报out of range异常,并且插入临界值 ③ 如果不设置长度,会有默认的长度 长度代表了显示的最大宽度,如果不够会用0在左边填充,但必须搭配zerofill使用! */ #1.如何设置无符号和有符号 DROP TABLE IF EXISTS tab_int; CREATE TABLE tab_int( t1 INT(7) ZEROFILL, t2 INT(7) ZEROFILL ); DESC tab_int; INSERT INTO tab_int VALUES(-123456); INSERT INTO tab_int VALUES(-123456,-123456); INSERT INTO tab_int VALUES(2147483648,4294967296); INSERT INTO tab_int VALUES(123,123); SELECT * FROM tab_int; #二、小数 /* 分类: 1.浮点型 float(M,D) double(M,D) 2.定点型 dec(M,D) decimal(M,D) 特点: ① M:整数部位+小数部位 D:小数部位 如果超过范围,则插入临界值 ② M和D都可以省略 如果是decimal,则M默认为10,D默认为0 如果是float和double,则会根据插入的数值的精度来决定精度 ③定点型的精确度较高,如果要求插入数值的精度较高如货币运算等则考虑使用 */ #测试M和D DROP TABLE tab_float; CREATE TABLE tab_float( f1 FLOAT, f2 DOUBLE, f3 DECIMAL ); SELECT * FROM tab_float; DESC tab_float; INSERT INTO tab_float VALUES(123.4523,123.4523,123.4523); INSERT INTO tab_float VALUES(123.456,123.456,123.456); INSERT INTO tab_float VALUES(123.4,123.4,123.4); INSERT INTO tab_float VALUES(1523.4,1523.4,1523.4); #原则: /* 所选择的类型越简单越好,能保存数值的类型越小越好 */ #三、字符型 /* 较短的文本: char varchar 其他: binary和varbinary用于保存较短的二进制 enum用于保存枚举 set用于保存集合 较长的文本: text blob(较大的二进制) 特点: 写法 M的意思 特点 空间的耗费 效率 char char(M) 最大的字符数,可以省略,默认为1 固定长度的字符 比较耗费 高 varchar varchar(M) 最大的字符数,不可以省略 可变长度的字符 比较节省 低 */ CREATE TABLE tab_char( c1 ENUM('a','b','c') ); INSERT INTO tab_char VALUES('a'); INSERT INTO tab_char VALUES('b'); INSERT INTO tab_char VALUES('c'); INSERT INTO tab_char VALUES('m'); INSERT INTO tab_char VALUES('A'); SELECT * FROM tab_set; CREATE TABLE tab_set( s1 SET('a','b','c','d') ); INSERT INTO tab_set VALUES('a'); INSERT INTO tab_set VALUES('A,B'); INSERT INTO tab_set VALUES('a,c,d'); #四、日期型 /* 分类: date只保存日期 time 只保存时间 year只保存年 datetime保存日期+时间 timestamp保存日期+时间 特点: 字节 范围 时区等的影响 datetime 8 1000——9999 不受 timestamp 4 1970-2038 受 */ CREATE TABLE tab_date( t1 DATETIME, t2 TIMESTAMP ); INSERT INTO tab_date VALUES(NOW(),NOW()); SELECT * FROM tab_date; SHOW VARIABLES LIKE 'time_zone'; SET time_zone='+9:00';