装饰器
从一个简单的计时功能来了解装饰器的功能与基本概念。
import time def foo(): time.sleep(2) print("Hello world!") foo()
这是一个简单的打印延时程序,现在想要计算出程序运行的过程用了多长时间,并且不改动源代码,这时候就需要使用装饰器来完成需求了。
import time def timmer(func): def wrapper(): """计时功能""" time_start=time.time() func() time_end=time.time() print("Run time is %s "%(time_end-time_start)) return wrapper @timmer def foo(): time.sleep(2) print("Hello world!") foo()
在这个函数中,只是加入了一个@timmer就使得没有更改原程序代码而直接增加了一个计时的功能,这真的是有些神奇呢,那这个所谓的装饰器是怎样工作的呢?
@timmer其实是调用装饰器的语法,在调用前我们必须遵守先定义再调用的原则,@timmer其实相当于foo=timmer(foo),程序运行timmer函数,将foo作为参数func,定义函数wrapper并返回wrapper的地址空间,运行foo()其实就是运行了wrapper,而wrapper中的func()就是foo(),运行前后的时间差打印出来,就是我们要的计时功能了。
因为这里我们定义的foo()是一个无参函数,无需传递参数,当我们需要传递参数时,则需要将wrapper后加入动态参数*args,**kwargs来接收传入的参数。
有参装饰器
def auth(func): def wrapper(*args, **kwargs): username = input("Please input your username:") passwd = input("Please input your password:") if passwd == '123' and username == 'jeff': print("Login successful") func() else: print("login error!") return wrapper @auth def index(): print("Welcome to China") index()
这里有一个登录的装饰器,当我们需要使函数中认证的信息存放在多种途径,并且再认证前确认认证信息,那么我们这个函数主体就需要加入一个参数存放认证途径,并且装饰器也需要传递参数,这个时候,我们把函数改为
def auth(filetype): def auth2(func): def wrapper(*args,**kwargs): if filetype == "file": username=input("Please input your username:") passwd=input("Please input your password:") if passwd == '123' and username == 'jeff': print("Login successful") func() else: print("login error!") if filetype == 'SQL': print("No SQL") return wrapper return auth2 @auth(filetype='file') def index(): print("welcome") index()
@auth(filetype='file') 就是运行auth函数,将filetype参数传进auth的参数,并且运行auth返回auth2的地址,函数等同运行index=auth2(index),并且附带了外层filetype的参数,auth2(index)返回wrapper后执行wrapper,判断filetype,然后登陆。
这样就是的参数传进了装饰器内部。这就是有参装饰器。
当一个函数有多个装饰器时,
@ccc @bbb @aaa def func() pass func=ccc(bbb(aaa(func)))
# @ccc('c')
# @bbb('b')
# @aaa('a')
# def func():
# pass
#
# func=ccc('c')(bbb('b')(aaa('a')(func)))
迭代器
在了解迭代器之前,首先要知道可迭代对象的概念,在python中可以调用__iter__()对象那就是可迭代对象,调用iter方法就变成一个迭代器,可以调用__next__()就是一个迭代器,__next__()用于迭代器取值。
当next超出迭代器的范围时,python解释器会提示stopiteration,可以使用以下方式解决。
try: pass expect StopIteration: break
或者我们还可以使用for循环遍历迭代器,for循环其实就是将对象转化为迭代器再遍历,并且自动完成不会提示stopiteration。
迭代器的优缺点:
优点:
迭代器提供了一种不依赖于索引的取值方式,这样就可以遍历那些没有索引的可迭代对象了(字典,集合,文件),
迭代器是惰性计算,每next一次就出一个值,这样更节省内存空间。
缺点:
在运行完以前无法获取迭代器的长度,没有列表灵活,
只能往后取值,不能倒着取值。
可以使用内置函数isinstance来判断是否可迭代。
from collections import Iterable,Iterator isinstance(*,iterable) isinstance(*,iterator)
生成器
函数体中有yield就是一个生成器。
生成器的本质是一个迭代器,所以迭代器的操作也适用于生成器。
yield与return不同的是,return返回第一个值(元组也是一个整体)函数就结束了,但是yield可以返回多个值,在生成器函数中,每次执行到yield函数就暂停了,需要使用next去触发执行下一步。yield保留了暂停的状态,收到next触发会运行直到下一个yield停下,保留当前位置状态。


def test(): print('one') yield 1 #return 1 print('two') yield 2 #return 2 print('three') yield 3 #return 2 print('four') yield 4 #return 2 print('five') yield 5 #return 2 g=test() for i in g: print(i)
生成器的小应用
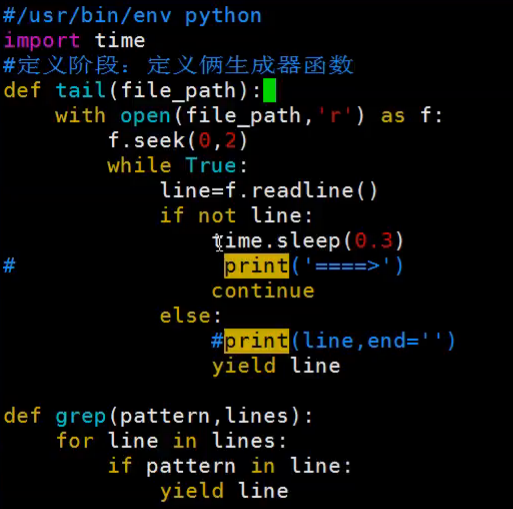
import time def tail(file_path): with open(file_path,'r') as f: f.seek(0,2) while True: line=f.readline() if not line: time.sleep(0.3) continue else: # print(line) yield line g=tail('/tmp/a.txt') for line in g: print(line)

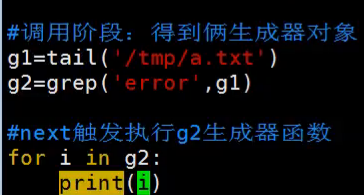
协程函数
def eater(name): print('%s start to eat food'%name) while True: food=yield print('%s get %s ,to start eat'%(name,food)) print('done') e=eater('xx') next(e) e.send('egg') e.send('food')
先定义一个协程函数,将yield作为参数赋值给food,next()协程函数就是初始化此函数,将函数运行到yield处停止住,然后使用send方法将值传给变量food,并同时执行一次next()。
也就是说yield如果是表达式形式,执行前必定先next(),send与next当可以让函数在上一次暂停的位置继续运行,但是只有send可以在触发运行前给yield传一个值。
总结一下yield的功能,1.相当于将__iter__和__next__方法封装到函数内部,2.与return相比,yield可返回多次值,3.函数暂停已经继续运行的状态是通过yield保存的。
协程函数每次使用前都要初始化,所以可以使用装饰器完成初始化。
def init(func): def wrapper(*args,**kwargs): res=func(*args,**kwargs) next(res) return res return wrapper @init #eater=init(eater) def eater(name): print('%s start to eat' % name) food_list=[] while True: food = yield food_list print('%s eat %s' % (name, food)) food_list.append(food) e = eater('zhejiangF4') #wrapper('zhengjiangF4') print(e.send('123')) print(e.send('123'))
from urllib.request import urlopen def get(): while True: url=yield res=urlopen(url).read() print(res) g=get() next(g) g.send('http://www.python.org')
#找出目录下所有文件里写有python的文件名 #grep -rl 'python' C:egon #-*-coding=utf-8-*- import os,time def init(func): def wrapper(*args,**kwargs): res=func(*args,**kwargs) next(res) return res return wrapper #找到一个绝对路径,往下一个阶段发一个 @init def search(target): '找到文件的绝对路径' while True: dir_name=yield #dir_name='C:\egon' print('车间search开始生产产品:文件的绝对路径') time.sleep(2) g = os.walk(dir_name) for i in g: # print(i) for j in i[-1]: file_path = '%s\%s' % (i[0], j) target.send(file_path) @init def opener(target): '打开文件,获取文件句柄' while True: file_path=yield print('车间opener开始生产产品:文件句柄') time.sleep(2) with open(file_path) as f: target.send((file_path,f)) @init def cat(target): '读取文件内容' while True: file_path,f=yield print('车间cat开始生产产品:文件的一行内容') time.sleep(2) for line in f: target.send((file_path,line)) @init def grep(pattern,target): '过滤一行内容中有无python' while True: file_path,line=yield print('车间grep开始生产产品:包含python这一行内容的文件路径') time.sleep(0.2) if pattern in line: target.send(file_path) @init def printer(): '打印文件路径' while True: file_path=yield print('车间printer开始生产产品:得到最终的产品') time.sleep(2) print(file_path) g=search(opener(cat(grep('py',printer())))) g.send('C:\egon') g.send('D:\dir1') g.send('E:\dir2')
import os g=os.walk('C:\egon') for i in g: # print(i) for j in i[-1]: file_path='%s\%s' %(i[0],j) print(file_path)
g=os.walk('C:\egon') l1=['%s\%s' %(i[0],j) for i in g for j in i[-1]] print(l1)
列表解析一次性将所有值都读取到列表。
l=['egg%s' %i for i in range(100)] print(l)
使用生成器可以减少内存一次只拿一个值。
g=l=('egg%s' %i for i in range(10000000000000000000)) print(g) for i in g: print(i)
读大文件时使用这种方法很节约空间。
总的来说:
1、把列表解析的[]换成()得到的就是生成器表达式,
2、列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存,
3、Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和。
迭代器转化为列表:
l=list(g)#g是迭代器 print(l)