前言:很多文章描述过于复杂故整理之。
1C# Dictionary设计思想:
1.1 数据结构
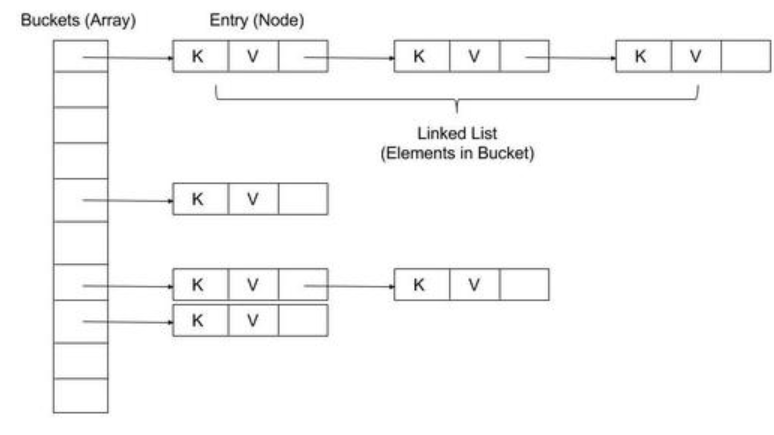
- 创建大小为size的数组entries(用来存放字典元素--以下称:entry)
- 创建桶buckets数组记录entry的index(大小和entries保持一致)
- entry结构体:hash、nextIndex(下个entry的index)、key、value
1.2 数据维护(逻辑)
- 添加entry时,计算该entry hashCode落在桶的位置(规则是hashCode对桶求余)
- 当出现落在的位置(桶)里已经有别的“index”了,那么这些冲突的index根据先来后到建立单链表(即链地址法--开放地址法、链地址法、建立溢出区、再哈希法4大方法之一) 可以发现,最理想的状态是,每个entry一一对应的落在buckets数组上是最划算的(查询等消耗最低)。
- 当entries数组长度不够用时扩容,buckets也需要同步扩容。
- 记录freeCount,freeCount == count(entries的)-Count(字典的)
- 字典有个版本字段,增删改都会导致+1。(意义:比如遍历的过程是否版本被修改--增删)(freeList;//记录最近一次remove的实体的idx)
1.3 链地址图示--桶冲突
1.4 部分源码例子
private void Resize(int newSize, bool forceNewHashCodes) {
Contract.Assert(newSize >= entries.Length);
//创建新的桶数组
int[] newBuckets = new int[newSize];
for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1;
//创建新的实体数组
Entry[] newEntries = new Entry[newSize];
//拷贝实体数组
Array.Copy(entries, 0, newEntries, 0, count);
//强制重新计算hashCode
if(forceNewHashCodes) {
for (int i = 0; i < count; i++) {
if(newEntries[i].hashCode != -1) {
newEntries[i].hashCode = (comparer.GetHashCode(newEntries[i].key) & 0x7FFFFFFF);
}
}
}
for (int i = 0; i < count; i++) {
if (newEntries[i].hashCode >= 0) {
//当hashCode大于-1(该元素有值),赋值桶的值
int bucket = newEntries[i].hashCode % newSize;
newEntries[i].next = newBuckets[bucket];
newBuckets[bucket] = i;
}
}
buckets = newBuckets;
entries = newEntries;
}
Find操作
private int FindEntry(TKey key) {
...
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
//对应的桶拿到该桶位置最近一次的实体的idx, 遍历桶位置的单链表,如果对应的key和参数key相等,则return
for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
}
...
return -1;
}
建议查看源码深入理解