上万页大数据量的分页查询方案
背景
数据量:五万页。
一、方案1
SELECT
*
FROM
t_view_log AS t
ORDER BY
t.create_time DESC
LIMIT 50000 OFFSET 10;
-- 耗时76秒,不可接受。
在create_time字段添加索引后,没有改观,通过分析执行计划,走的全表扫描,因为MySQL预判,在create_time上没有条件,故走索引不如全表扫描来的快。
聚集索引(主键索引是一种聚集索引)和非聚集索引图示:
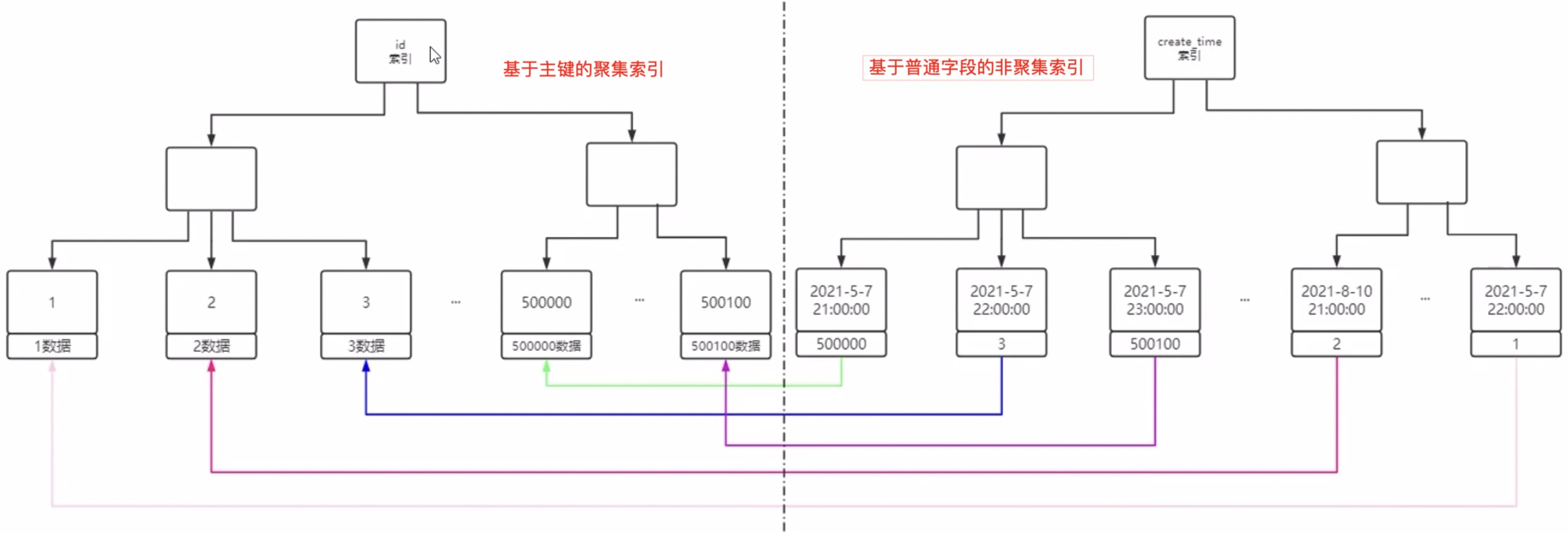
二、方案二
现在,我们要想办法让create_time索引生效,就是create_time成为查询条件。
SELECT
t.*
FROM
t_view_log AS t
WHERE
t.create_time >= (
SELECT t.create_time FROM t_view_log AS iv ORDER BY iv.create_time DESC LIMIT 50000 OFFSET 1
)
ORDER BY
t.create_time DESC
LIMIT 10;
-- 耗时2秒
- 先利用索引覆盖,通过子查询,查出第50000条数据的的创建时间
索引覆盖:查询结果只包含索引字段的查询,将直接从索引结构获取数据,不会反查数据表做扫描,所以效率非常高。
- 再利用第50000条的创建时间,作为条件查出10条数据
三、方案三
实践中,前端通常是按照上一页 下一页这种方式来查询的,所以可以预先将当前页的首尾两条数据的create_time从前台传入,作为条件,这样就可以避免子查询。
SELECT
t.*
FROM
t_view_log AS t
WHERE
t.create_time >= (
SELECT t.create_time FROM t_view_log AS iv ORDER BY iv.create_time DESC LIMIT 50000 OFFSET 1
)
ORDER BY
t.create_time DESC
LIMIT 10;
-- 耗时不到1秒
现在很多UI设计,已经不再提供具体的页码供翻页操作了,仅保留首页、上一页、下一页按钮,包括移动端的下划加载更多数据,都是基于这种思路,这更利于查询优化。同时还能省略COUNT(*)的统计函数。
在并发场景下,条件数据create_time会出现重复,当出现大量重复时,会导致局部的循环分页,无法前进或后退,此时就需要以页大小作为偏移,才能解决。
思考:数据页上万后,真的有必要考虑后面的数据分页吗,百分之九十的情况是没人关注后面的数据,关注点往往停留在前几页。所以,从业务上,可以只给用户展示前面的一百页数据,将这块数据做缓存,也就能从业务上规避技术难题了。