pandas的数据结构介绍
要使用pandas,你首先要熟悉它的两个主要数据结构:Series和DataFrame。虽然它们并不能解决所有问题,但它们为大多数应用提供了一种可靠的、易于使用的基础
Series
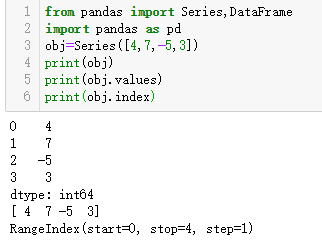
Series的字符串表现形式为:索引在左,值在右。由于我们没有为数据指定索引,于是会自动创建一个0到N-1的整数型索引。可以通过values和index属性来获取其数组表示形式和索引对象
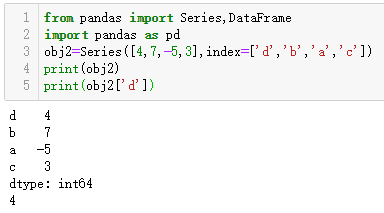
可以指定索引。与NumPy相比,你可以通过索引的方式选取Series中的单个或一组值
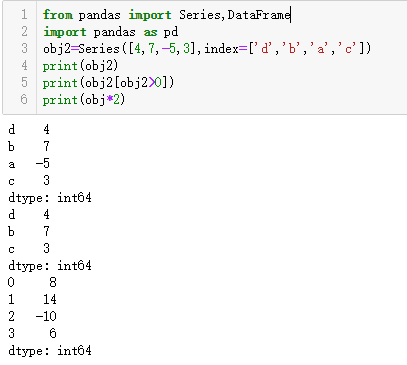
NumPy运算(如根据布尔型数值进行过滤,标量乘法,应用数学函数等)都会保留索引和值之间的连接:
还可以将Series看成是一个定长的有序字典,如果数据被存放在一个Python字典中,也可以通过这个字典来创建Series
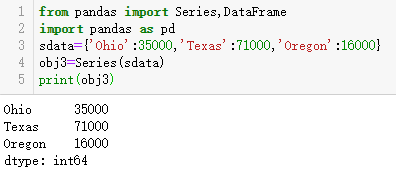
如果只传入一个字典,则结果Series中的索引就是原字典的健。也可以指定索引
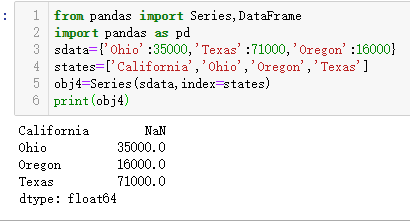
Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切:
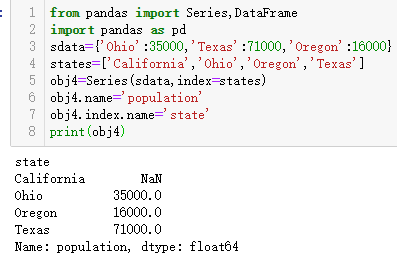
总结:结合以上程序,放在Series里的可以有:列表;列表+索引;字典;字典+索引。一共四种
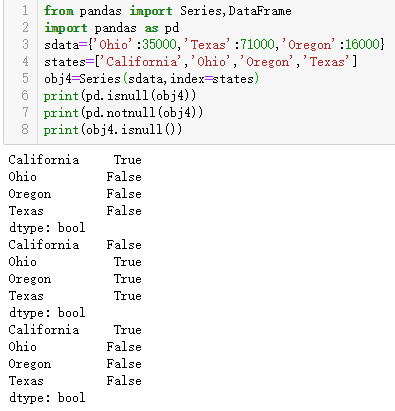
pandas的isnull和notnull函数可以用于检测缺失数据。也可以用Series的实例方法:例如:obj4.isnull()
DataFrame
DataFrame是一个表格型数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看作由Series组成的字典(和Series共用同一个索引)。其实,DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数组结构)。有关DataFrame内部的技术细节远远超过本书所讨论的范围
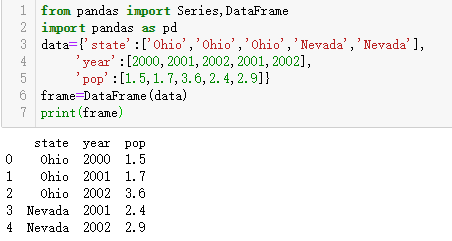
构建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典
结果DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列
如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:(指定的列序列,必须在data字典里)
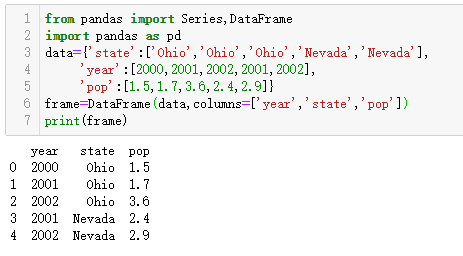
如果指定的列不在data字典里,就会变成NaN
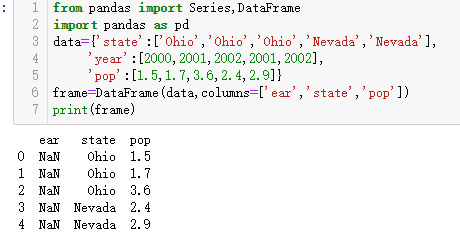
通过类似字典标记的方式和属性的方式,可以将DataFrame的列获取为一个Series
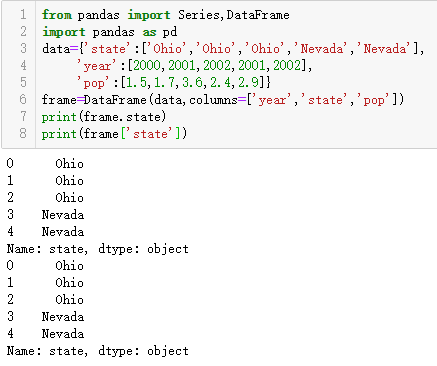
也可通过行索引字段ix来获取各列
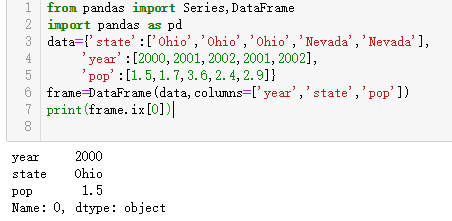
关键字del用于删除列
警告:通过索引方式返回的列只是相应数据的视图而已,并不是副本。因此,对返回的Series所做的任何就地修改都会反映到源DataFrame上。通过Series的copy方法即可显示地复制列。
可以输入给DataFrame构造器的数据有:
二维ndarray
由数组、列表或元组组成的字典
由Series组成的字典
由字典组成的字典
字典或Series的列表
等等.....
详细见书中表格5-1
跟Series一样,都有index.name的属性和columns.name的属性
values属性也会以二维ndarray形式返回DataFrame中的数据
如果DataFrame各列的数据类型不同,则值数组的数据类型就会选用能兼容所有列的数据类型

索引对象
(124页)
妈的!服务器奔溃!全他妈删了!没保存的后果!
(138页)
angluarjs2入门学习资源
mosquitto安装和测试
loj#6031. 「雅礼集训 2017 Day1」字符串(SAM 广义SAM 数据分治)
loj#6030. 「雅礼集训 2017 Day1」矩阵(贪心 构造)
loj#6029. 「雅礼集训 2017 Day1」市场(线段树)
HDU4609 3-idiots(生成函数)
loj#6436. 「PKUSC2018」神仙的游戏(生成函数)
BZOJ3028: 食物(生成函数)
洛谷P4841 城市规划(生成函数 多项式求逆)