2019-12-04
22:47:48
来源:

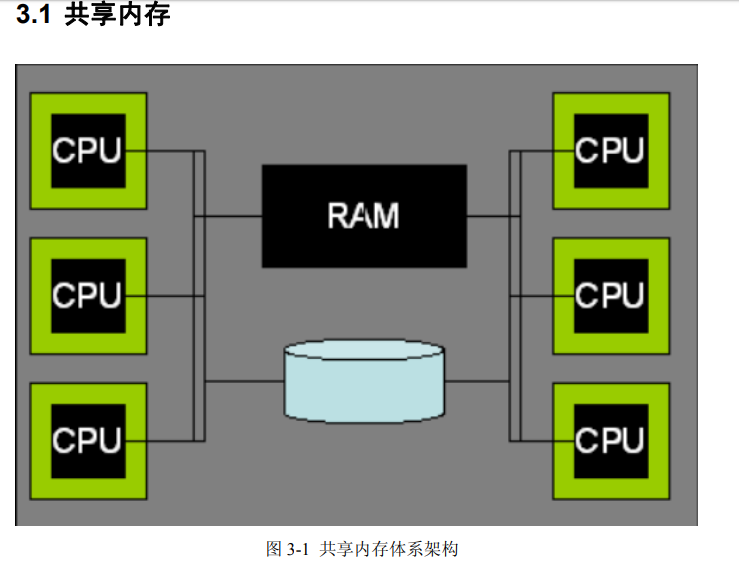




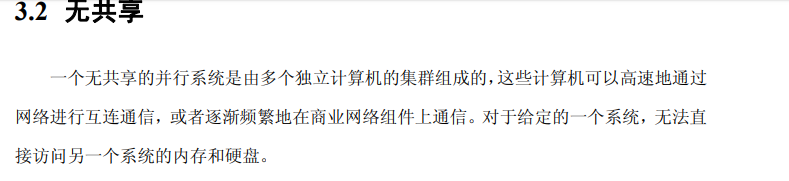

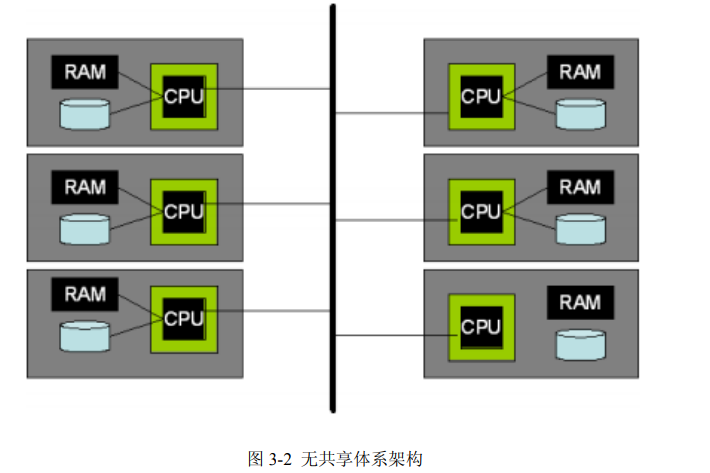






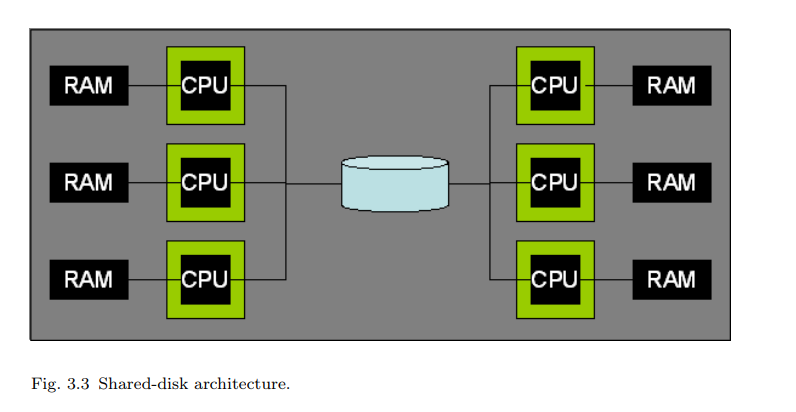








用户使用它来处理各种各样的自定义数据分析任务)这样低级别的可编程的数据处理后端, 这些设计理念正在获得越来越多的认可。然而,尽管这些设计理念正在更加广泛地影响计算, 数据库系统并行性的设计仍然有新的问题产生。 并行软件架构在未来十年将迎来一个重要挑战,这个挑战来自于处理器供应商开发出新 一代“众核”架构的构想。这些设备将会引进一种新的硬件设计理念,即在一个单一的芯片上 拥有数十、数百甚至数千的处理单元,通过高速芯片网络互联,但是,仍然保留了许多现有 的瓶颈,比如访问芯片外的内存和磁盘。这将会导致在磁盘和处理器的内存路径上产生新的 不平衡和瓶颈,这就必定需要重新审视 DBMS 架构,以满足硬件性能潜力。 在面向服务的计算领域,一些相关的架构转向更大的规模已经是可以预见的。这里的核 心理念是,由数以万计的电脑组成的大数据中心来为用户安排处理(硬件和软件)。在这样 的规模下,只有实现高度自动化,才能负担得起应用程序和服务器管理。没有什么管理任务 可以随着服务器的数量一直扩展。而且,集群中通常使用更不可靠的商业服务器,故障是不 可避免的,从故障中恢复就需要完全的自动化操作。在这样规模下的服务,将会每天出现磁 盘故障,每星期出现服务器故障。在这样的环境中,管理数据库的备份通常被整个数据库的 冗余在线副本所取代,这些副本维护在不同磁盘上不同的服务器中。根据数据的价值,冗余 副本可能保存在不同的数据中心。仍然可以采用自动离线备份,从而可以从应用程序、管理 工作或者用户错误中恢复。然而,从最常见的错误和故障中恢复是将故障快速转移到冗余的 在线副本。冗余可以用多种方式实现:(a)在数据存储级的复制(存储区域网络);(b)在数据 库存储引擎级别的复制(将在第 7.4 节讨论);(c)由查询处理器执行冗余查询(第 6 章);或 者(d)在客户端软件级别自动生成冗余数据库请求(例如,WEB 服务器或应用程序服务器)。 在一个更高的解耦水平,在实际应用中为多个具备 DBMS 功能的服务器进行分层部署是很 普遍的,以减少“DBMS 记录”的请求率。这些机制包括各种形式的、针对 SQL 查询的中 间层数据库缓存(包括专业的内存数据库,比如 Oracle TimesTen),以及更多被配置成服务 于这个目的的传统数据库。在部署层次的更高层面,许多支持编程模型(比如 Enterprise Java Bean)的、面向对象的“应用-服务器”架构,可以配置成为配合 DBMS 工作的、应用对象 的事务缓存。然而,这些各式各样的方案的选择、设置和管理,仍然是不标准的,并且很复 杂,普遍接受的优秀模型仍然难以实现。