EMNIST: an extension of MNIST to handwritten letters
MNIST数据集
MNIST数据集已经成为机器学习、分类以及计算机视觉系统的一个基准数据集。由于其任务的可理解性和直观性、相对较小的规模和存储要求以及数据集本身的可访问性和易用性,MNIST数据集如今被广泛采用 。
概述
一个较好基准的重要性不可低估,而且对于问题的标准化方法,尤其是在竞争激烈和快节奏的领域,如机器学习和计算机视觉。这些任务为分析和比较不同的学习方法和技巧提供了一种快速、定量和公平的方法。这使得研究人员能够快速洞察方法和算法的性能和特点,尤其是当任务是直观的和概念上简单的任务时。
由于单个数据集可能只涵盖一项特定任务,因此存在一套不同的基准任务对于采用更全面的方法来评估和表征算法或系统的性能非常重要。在机器学习社区中,有几个标准化的数据集被广泛使用,并变得极具竞争力。其中包括MNIST数据集[1]、CIFAR-10和CIFAR-100数据集[2]、STL-10数据集[3]和街景门牌号(SVHN)数据集[4]。
MNIST数据集包含10类手写数字分类任务,于1998年首次推出,目前仍是计算机视觉和神经网络领域最广为人知和使用最广泛的数据集。然而,一个好的数据集需要代表一个足够有挑战性的问题,使它既有用又确保它的寿命[5]。这也许是MNIST在面对使用深度学习和卷积神经网络获得的越来越高的精度时所遭受的损失。多个研究小组已经发表了99.7%以上的准确率[6]–[10],这是一个分类准确率,在这个分类准确率下,数据集的标注可能会受到质疑。因此,它更多的是一种测试和验证分类系统的手段,而不是一个有意义或有挑战性的基准。
MNIST数据集的可访问性几乎肯定有助于其广泛使用。整个数据集相对较小(与最近的基准数据集相比),可以自由访问和使用,并且以完全直接的方式进行编码和存储。编码不使用复杂的存储结构、压缩或专有数据格式。因此,从任何平台或通过任何编程语言访问和包含数据集都非常容易。
为了促进这一数据集的使用,显然需要创建一套定义明确的数据集,全面规定分类任务的性质和数据集的结构,从而能够在多组结果之间进行简单直接的比较。本文介绍了这样一套数据集,称为扩展修正NIST (EMNIST)。这些数据集来自NIST特殊数据库19,旨在为神经网络和学习系统提供更具挑战性的分类任务。通过直接匹配原始MNIST数据集中的图像规格、数据集组织和文件格式,这些数据集被设计为现有网络和系统的直接替代。
EMNIST数据集
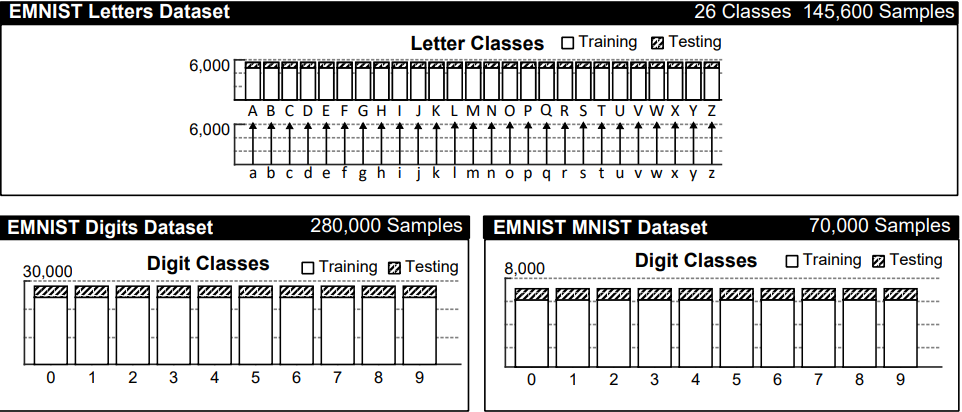
EMNIST数据集中“按类别分类”和“按合并分类”数据集都包含完整的814255个字符,只是分配的类别数量不同。因此,样本字母类中的分布在两个数据集之间是不同的。但在两个数据集之间,数字类中的样本数量保持不变。
EMNIST平衡数据集(balanced)是最广泛适用的数据集,因为它包含所有按合并类的平衡子集。选择47类数据集而不是62类数据集,是为了避免纯粹由于大写字母和小写字母之间的错误分类而导致的分类错误。
EMNIST字母数据集试图通过合并所有大写和小写类别来形成一个平衡的26类分类任务,从而进一步减少因大小写混淆而发生的错误。