简介
Map用户保存具有映射关系的数据,因此Map集合里保存着两组数,一组值用户保存Map里的key,另一组值用户保存Map里的value,key和value都可以是任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false。
接口中定义的方法:

Map中还包括一个内部类Entry,该类封装了一个key-value对。Entry包含如下三个方法:

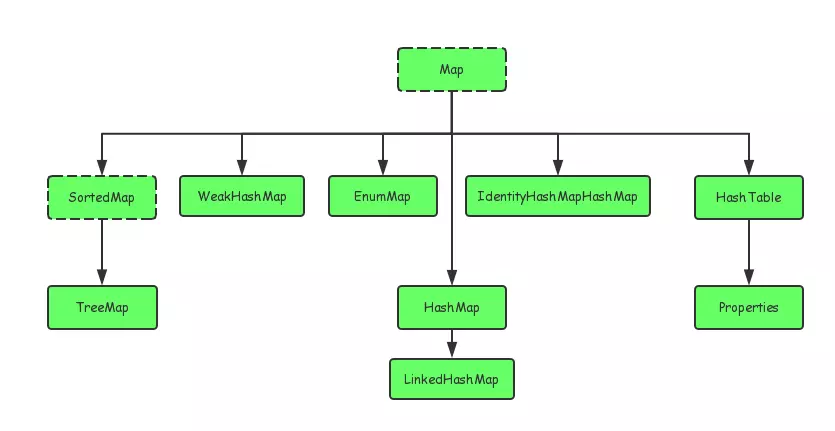
实现类
这里介绍Map接口下的三个重要的集合实现类:
- HashMap类:HashMap是实现了Map接口的key-value集合,实现了所有map的操作,允许key和value为null,它相当于Hashtable,与之存在的区别是hashMap不是线程安全的,HashMap允许null值。
- TreeMap类:TreeMap是基于红黑树的实现,也是记录了key-value的映射关系,该映射根据key的自然排序进行排序或者根据构造方法中传入的比较器进行排序,也就是说TreeMap是有序的key-value集合
- Hashtable类:它是类似与HashMap的key-value的哈希表,不允许key-value为NULL值,另外一点值得注意的是Hashtable是线程安全的
对比
虽然HashMap、Hashtable、TreeMap这三个都是Map接口的实现,其内部实现及性能等还是存在区别。
基本
- HashMap:初始化容量为16,扩容每次为2*oldCap,key和value可以为NULL值
- Hashtable:初始化容量为11,扩容每次为2*oldCap+1,key和value不可以为NULL值
- TreeMap:初始化容量为0,内部是红黑树结构,不存在hash冲突的情况,不存在扩容的操作,key和value不可以为NULL值
Key相等判断标准
- HashMap:两个key通过equals()方法比较返回true,并且两个key的hashCode值也相等
- Hashtable:两个key通过equals()方法比较返回true,并且两个key的hashCode值也相等
- TreeMap:两个key通过compareTo()方法返回0
内部原理
- HashMap:HashMap是散列表实现,内部是数组+链表或者红黑树的结构
- Hashtable:Hashtable也是散列表实现,内部是数组+链表的结构
- TreeMap:TreeMap内部是红黑树的结构
线程安全
- HashMap:不是线程安全的,其实通过Map m = Collections.synchronizeMap(hashMap)的方式也可以使得HashMap变成线程安全的,但是这样做对程序的性能可能是噩梦,在后面会介绍ConcurrentHashMap,建议在多线程的情况下可以使用ConcurrentHashMap替换HashMap.
- Hashtable:是线程安全的,内部方法使用关键字synchronized修饰
- TreeMap:不是线程安全的
这里的Hashtable属于同步容器,还有更多的并发容器可以使用,请参考:Java学习笔记—多线程(同步容器和并发容器)
性能分析
按照如下代码对HashMap、Hashtable、TreeMap的性能进行测试
public class HashMapProgress { //定义用于测试的HashMap private static HashMap<Integer,Integer> hashMap = new HashMap<>(); //定义用于测试的Hashtable private static Hashtable<Integer,Integer> hashtable = new Hashtable<>(); //定义用于测试的TreeMap private static TreeMap<Integer,Integer> treeMap = new TreeMap<>(); /** * 添加元素的方法 * @param map 对应的map * @param count 添加个数 */ public static void addEntry(Map<Integer,Integer> map, int count){ Long startTime = System.currentTimeMillis(); if (count <= 0){ return; } for (int i = 0; i < count; i++) { map.put(i,i); } Long endTime = System.currentTimeMillis(); System.out.println("添加(" + count + ")个元素使用时间:" + (endTime - startTime) + "s"); } /** * 获取元素的方法 * @param map * @param count */ public static void getEntry(Map<Integer,Integer> map, int count){ Long startTime = System.currentTimeMillis(); if (count <= 0){ return; } for (int i = 0; i < count; i++) { map.get(i); } Long endTime = System.currentTimeMillis(); System.out.println("获取(" + count + ")个元素使用时间:" + (endTime - startTime) + "s"); } public static void main(String[] args){ System.out.println("-------HashMap测试开始-----"); addEntry(hashMap,1000000); getEntry(hashMap,1000000); System.out.println("-------HashMap测试结束-----"); System.out.println("-------Hashtable测试开始-----"); addEntry(hashtable,1000000); getEntry(hashtable,1000000); System.out.println("-------Hashtable测试结束-----"); System.out.println("-------TreeMap测试开始-----"); addEntry(treeMap,1000000); getEntry(treeMap,1000000); System.out.println("-------TreeMap测试结束-----"); } }
分别测试了100000,1000000,10000000个数据的情况,测试结果如下所示:
| 数据量 | HashMap | Hashtable | TreeMap |
|---|---|---|---|
| 100000 | 插入用时:18s 查询用时:9s | 插入用时:14s 查询用时:5s | 插入用时:33s 查询用时:17s |
| 1000000 | 插入用时:98s 查询用时:20s | 插入用时:625s 查询用时:31s | 插入用时:242s 查询用时: 145s |
| 10000000 | 插入用时:9773s 查询用时:811s | 插入用时:15055s 查询用时:3369s | 插入用时:22354s 查询用时: 3889s |
通过上表可以看出随着数据量的增加,时间变化差异还是很大的,而在单线程的情况下还是尽量使用HashMap,相对于Hashtable、TreeMap性能更好,而针对特定的情况需视情况而论。
参考: