序言
我们在进行请求的时候,一般会设置虚拟的UserAgent,但是每次手动去设置很麻烦,而且同一个UserAgent访问次数多了,也很容易被屏蔽,所有我们需要大量的UserAent去供我们发起请求。
fake-useragent这个库包含了大量的UserAgent可以随意进行替换
安装fake-useragent
因为fake-useragent是一个python库,所以我们直接使用pip安装就可以了。
pip install fake-useragent
下面是一个简单获取不同浏览器UserAgent的例子
>>> import fake_useragent
>>> userAgent=fake_useragent.UserAgent()
>>> for i in range(5):
... print(userAgent.random)
...
Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36
Opera/9.80 (Windows NT 5.2; U; ru) Presto/2.7.62 Version/11.01
Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1500.55 Safari/537.36
Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36
这样每次就可以随机用不同的UserAgent去访问网站,你的请求也没那么容易被屏蔽了
获取UA
获取随机UserAgent
>>> import fake_useragent
>>> userAgent=fake_useragent.UserAgent()
>>> print(userAgent.random)
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36
如果你要设置成某个浏览器的UserAgent也是可以的
获取Chrome 的UA
>>> import fake_useragent
>>> userAgent=fake_useragent.UserAgent()
>>> print(userAgent.chrome)
Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36
获取Firefox 的UA
>>> import fake_useragent
>>> userAgent=fake_useragent.UserAgent()
>>> print(userAgent.firefox)
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0
在Scrapy中实现随机UserAgent
方法1:直接在程序中添加UserAgent
# -*- coding: utf-8 -*-
import scrapy
from fake_useragent import UserAgent
class ExampleSpider(scrapy.Spider):
name = 'example'
header={'User-Agent':UserAgent().random}
def start_requests(self):
url='http://example.com'
yield scrapy.Request(url,headers=self.header)
def parse(self, response):
print(response.request.headers['User-Agent'])

方法2:在middlewares中添加UserAgent
- 在process_request()方法里面,添加一个中间件
def process_request(self, request, spider):
from fake_useragent import UserAgent
ua = UserAgent()
request.headers['User-Agent'] = ua.random
- 在settings文件里面默认的UserAgent关闭掉
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'dome1.middlewares.Dome1DownloaderMiddleware': 543,
}
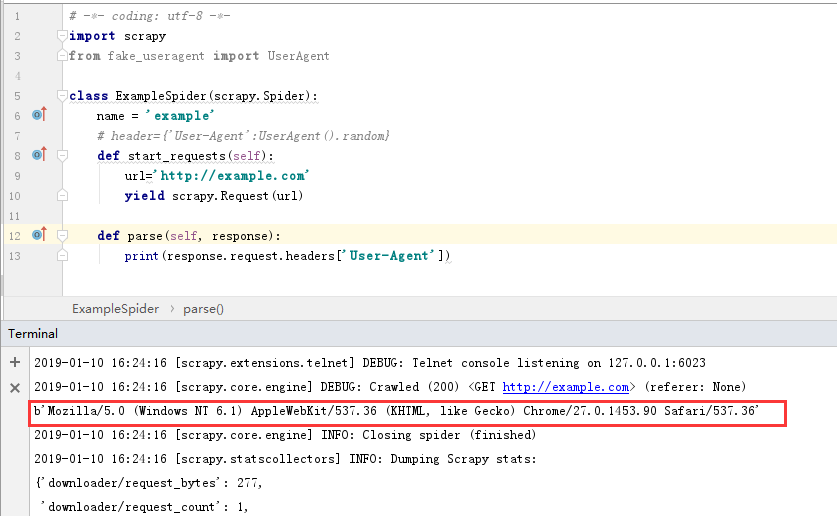
第一次运行

第二次运行

可以看到两次运行的UserAgent都是不一样的,表示我们的随机UserAgent也是设置成功了
方法3:直接在sttings文件里面上设置UserAgent
把settings文件里面的默认UserAgent替换掉,替换成随机的UserAgent
from fake_useragent import UserAgent
USER_AGENT=UserAgent().random
第一次运行
第二次运行
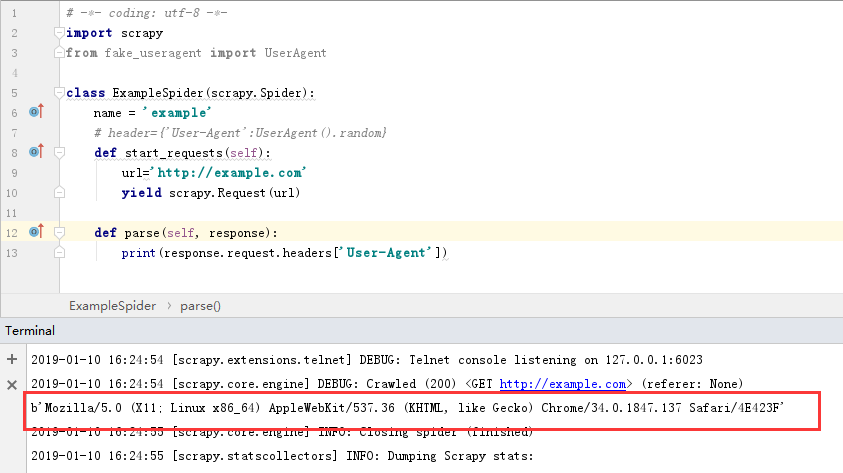
可以看到两次的结果都是不一样的,说明我的的随机UserAgent已经是设置成功了呢
以上就是Scrapy设置代理IP的过程,以上教程如果觉得对你有帮助的话,请点击一下推荐让更多的人看到!