DNN声学模型说话人自适应的经验性评估
2018年3月27日
发表于:Sound (cs.SD); Computation and Language (cs.CL); Audio and Speech Processing (eess.AS)
说话人自适应时从说话人无关模型中估计一个说话人相关的声学模型,以减小训练集与测试集由于说话人差异导致的不匹配。
已经出现了许多DNN自适应方法,但是缺乏实验比较。
声学模型采用TDNN-LSTM声学模型。
自适应源时标准中文普通话声学模型
自适应目标是带口音的中文普通话声学模型
本文对三种典型的说话人自适应方法:
- LIN
- LHUC
- KLD
进行经验性评估。对上述三种模型及其组合进行了性能比较。
关于说话人口音程度对说话人自适应性能的影响,本文也进行了测试。
训练-测试不匹配:训练集不能匹配新声学环境或者不能泛化至新的说话人。
为了解决未见过说话人识别问题以及声学环境不匹配问题,提出了多种声学模型补偿和自适应方法。
DNN自适应方法可以粗略地分为三类:
- 说话人适应层插入方法
LIN、LHN、LON是最常见的说话人适应层插入方法,其中LIN最常用。
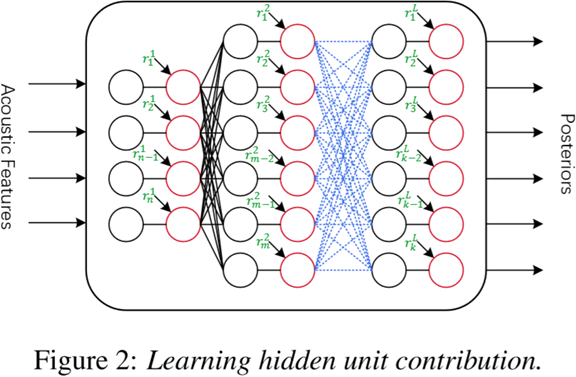
LHUC(Learning Hidden Unit Contribution)是说话人适应层插入方法地新类型,通过插入特殊的层以控制隐层的幅值(amplitude),使得SI网络参数变得说话人相关。
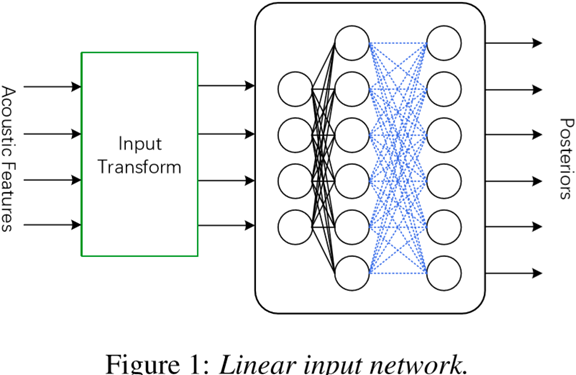
LIN的训练通常使用一个较小的学习率,如0.00001。
- 子空间方法
目标是找到一个用于自适应的低维说话人子空间。最直觉的应用是使用基于子空间的特征,如:i-Vectors,作为神经网络声学模型训练中的增补特征,或用于说话人自适应训练(SAT)。
除子空间的特征之外的另一种子空间方法,被称为:说话人编码,也是把特征用作增补[25]。
对于每个说话人,特定神经网络单元集合被链接到原始SI网络中,并进行优化。
基于i-Vector的SAT已经称为训练DNN声学模型时的小技巧,以提供较小但稳定的性能提升。
- 模型直接适应方法
一种直觉的想法是使用新的说话人数据来直接调整DNN参数。使用新数据来对SI模型进行重训练/调优是最简单的方式,又被称为重训练说话人无关(Retrained Speaker Independent,RSI)自适应。为避免过拟合,通常进行保守训练(Conservative Training),如KL散度(Kullback-Leibler Divergence)正则化[26]。通过把KL散度项添加到用于更新神经网络参数的原交叉熵代价函数中,该方法试图将适应后模型的后验分布接近于用于适应的源模型。虽然该方法十分有效,但是需要为每个说话人构建一个神经网络。
KLD正则化
L2正则化项使得自适应后模型参数与SI模型参数相接近。
对于声学模型训练,需要最小化交叉熵:
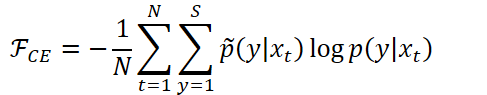

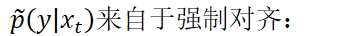
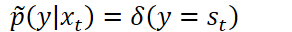

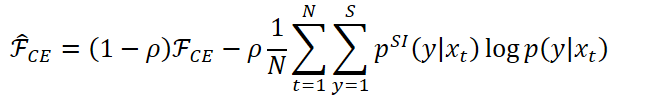
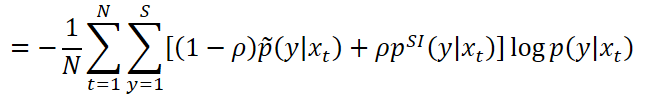
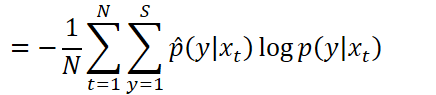
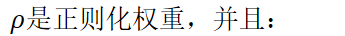


LHUC(学习性隐层单元贡献)

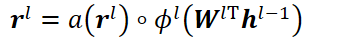

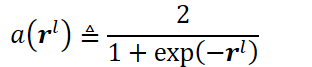
以限制r的元素取值为[0, 2]。

Previous studies on LHUC [22] have demonstrated that adapting more layers in the network can get continuously better accuracy. Hence we inserted LHUC parameters after each hidden layers.
实验
实验基于i-Vector与cMLLR(fMLLR)特征训练的SAT-DNN(TDNN-LSTM)声学模型。
[25] O. Abdel-Hamid and H. Jiang, "Fast speaker adaptation of hybrid nn/hmm model for speech recognition based on discriminative learning of speaker code," in Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013, pp. 7942–7946.
三种方法的组合:
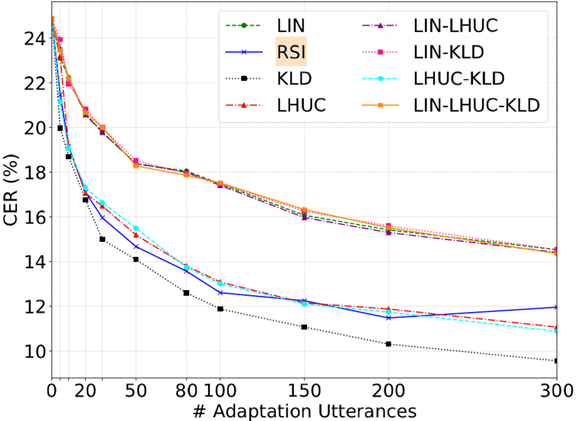
组合并不能带来性能提升。
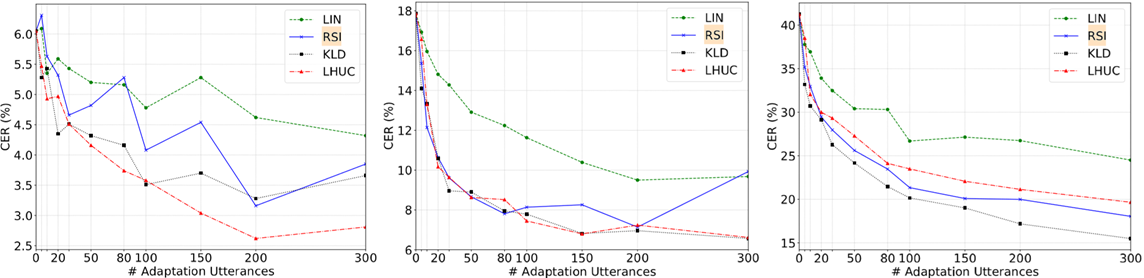
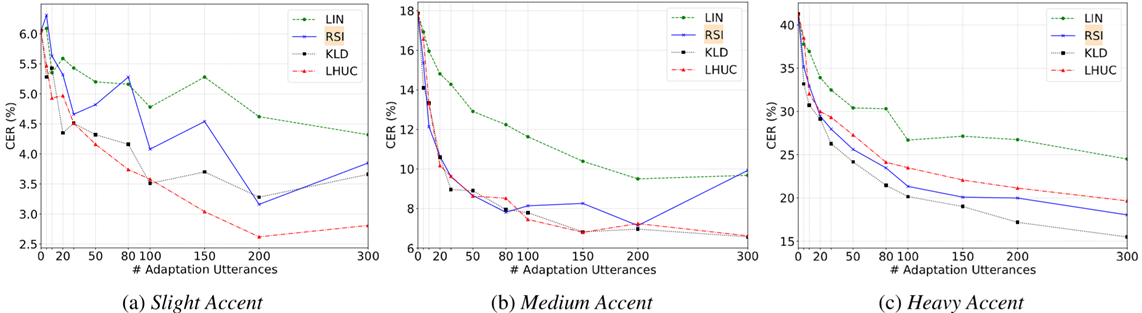
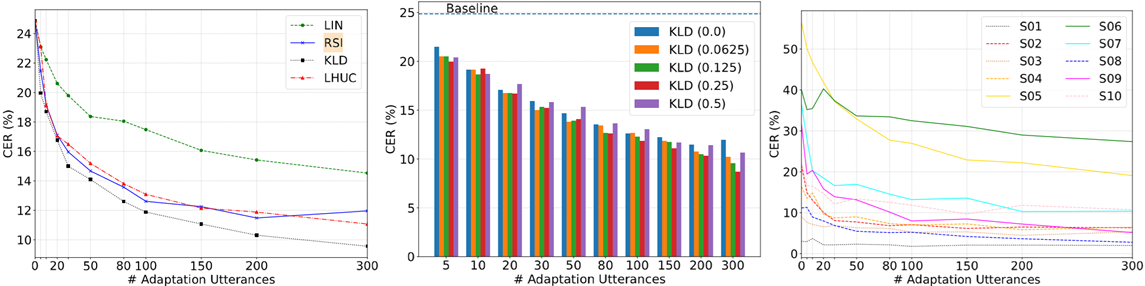
我们使用不同数量的适应数据调查了LIN,RSI,KLD和LHUC的适应能力。以前对LHUC的研究[22]表明,适应网络中更多的层次可以获得持续更好的准确性。因此,我们在每个隐藏层之后插入LHUC参数。对于LIN,模型的学习率为0.00001,而0.001和0.01分别用作KLD和LHUC的初始学习率。从图3a所示的结果中,我们可以看出,对于所有说话人而言,KLD在不同数量的自适应数据上都达到了最佳性能,并且比RSI更稳定。 LIN作为简单的图层插入方法也很有帮助,但其性能不如其他两种。对于RSSI和LUCC,它们的性能在大多数情况下都是可比的,但当适应数据大小超过200时,RSI就会出现偏差。
此外,与[26]类似,我们对基于KLD的适应进行了深入研究,结果如图3b所示。首先,[26]得出对于KLD适应使用少量数据(5或10个话语)反而不如基线,本文实验表明即使使用少量数据也能带来不错的性能提升。我们认为,这是因为测试说话人口音很重,即SI数据与目标说话人数据之间的差异十分明显。 使用不同ρ值[0.0625,0.5]进行比较也表明,即使对于不同大小的适应数据,即使ρ较小,也可以获得合理的CER减少。对于大数据集和小数据据,中等权重(例如,0.25)最优;对于中等大小数据集,较小正则化权重(例如,0.0625)最优。我们还比较了不同口音说话人的性能。图3c的结果显示KLD适用于每个测试说话人,并且在SI模型中具有最高CER的说话人(即,S5,具有最重的口音)实现了最大的CER减少。但随着适应数据的增加,每个说话人的增益越来越小。