Lattice是一个无环WFSA,结点可以是hmm状态、hmm(音素)、词,每个结点是一段音频在某个时间的对齐
用训练好的声学模型、现成的语言模型和发音字典构建解码网络(wfst),最后将提取的测试集的语音特征输入以上解码网络,得到网格结构(lattice)的语音识别结果。
Lattice可用于语言模型的得分重估计
一个Lattice是为一段音频产生的,Lattice是一个带权无向图,其中每个点代表一个声学单元,每条弧包含两个权重(声学权重和语言权重)。解码时,会使用Viterbi算法?结合两种权重搜索Lattice,得分最高的路径就是解码结果。
识别的结果以lattice呈现,可以保存为standard lattice format (SLF)文件。
Lattice输出可以用于重打分、生成n-best结果.
Lattice类型只是一个基于特定半环模板化的 FST
来自 <https://shiweipku.gitbooks.io/chinese-doc-of-kaldi/content/lattice.html>
Lattice的运算操作:
修剪Lattice
计算最优路径
计算N-best结果
语言模型重打分
概率缩放
Lattice联合(用于MMI)
Lattice组合
Lattice内插
Lattice由LatticeSimpleDecoder类(解码器)生成,这个类是一个从SimpleDecoder类修改得来。 SimpleDecoder是Viterbi-Beam搜索算法的一种直接实现。
Lattice的产生过程大致为:LatticeSimpleDecoder首先产生状态级晶格,并且用Lattice-Delta修剪它,然后使用特殊的确定性算法,只保留每个单词序列的最佳路径。
http://kaldi-asr.org/doc/lattices.html
因为每个状态一个token,限制了可能得到的不同token历史记录的数量,所以他们不是最合适的。若每个模型状态对应多个token,并且如果认为来自不同前序单词的token是不同的,就可以避免上述限制。这样就为生成hypotheses(译者注:意为可能的识别结果)的lattice(译者注:网格)提供了可能,lattice比单Best输出更有用。基于这个思想的算法称为lattice N-best。
对输入语音进行解码转录成文本形成搜索空间, 为了减少识别错误,这种搜索空间通常不是单一的,而是以多个假设的形式存在(如网格形式, N-best 等)
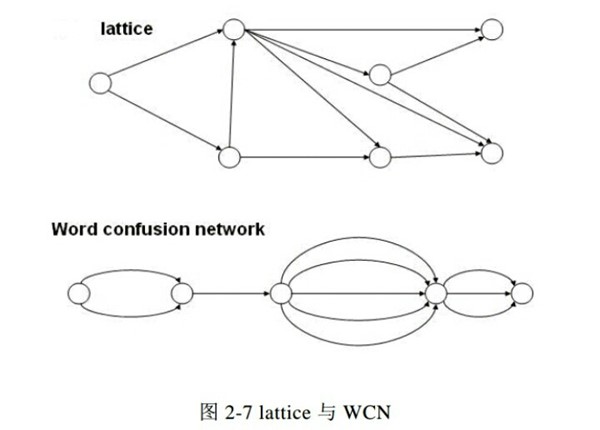
Lattice
Lattices describe all theories considered by the Recognizer that have not been pruned out. Lattices are a directed graph containingNodes and Edges. A Node that corresponds to a theory that a word was spoken over a particular period of time. An Edge that corresponds to the score of one word following another. The usual result transcript is the sequence of Nodes though the Lattice with the best scoring path. Lattices are a useful tool for analyzing "alternate results".
Lattices是一个有向图,结点是词,边是转移概率。转录的结果是遍历Lattices后得到的最高得分词序列
源代码中Lattice类型的解析
typedef fst::VectorFst<LatticeArc> Lattice;
Lattice是一个弧为LatticeArc基于VectorFst模板的FST
typedef fst::ArcTpl<LatticeWeight> LatticeArc;
LatticeArc是一个弧参数为LatticeWeight基于ArcTpl的类
typedef fst::LatticeWeightTpl<BaseFloat> LatticeWeight;
LatticeWeight是一个使用BaseFloat类型作为浮点型基于LatticeWeightTpl的类
LatticeWeightTpl是一个模板,定义在fst命名空间(fstext/lattice-weight.h),与词典半环类似
即OpenFst中的LexicographicWeight模板:
LexicographicWeight<TropicalWeight, TropicalWeight>
这两个模板的加运算都被定义为取max,但是"max"被不同地定义。
LexicographicWeight首先比较第一个元素,并使用第二个元素打破关系。 LatticeWeight首先比较总和; 然后使用差异来打破关系。 因此,具有(a,b)的LatticeWeight等价于具有(a + b,a-b)的LexigraphicWeight。 LatticeWeight背后的基本直觉是保持采用最低代价路径(其中总代价是语言加声学代价)的语义,同时分别"记住"声学代价和语言代价是什么。 在理想世界中,我们可能希望保持更多的信息分离:例如,语言模型代价,转换模型代价,发音概率代价。 但这是不实际的,因为这些信息在解码图中全部混合在一起,并且在解码图中将其分离将导致解码图大小的显着扩展。
如前所述,Lattice中的输入符号表示transition-ids,输出符号表示字(或解码图的输出上的任何符号)。
当设计Kaldi时,我们考虑使用LexicographicWeight类型,而不是LatticeWeight类型,其中第一个元素是(graph + acoustic)成本,第二个元素就是声音成本。 我们最终决定反对这一点,因为虽然它可能为某些目的稍微更有效,我们认为这将是太混乱。
在lattice上的许多算法(例如,采取最佳路径或修剪)对于使用Lattice类型而不是CompactLattice类型是最有效的。 问题是,使用CompactLattice类型,权重包含transition-id的序列,并且像采取最佳路径的操作将权重作乘法,这对应于将这些序列链接在一起。 对于许多算法,需要的时间是lattice中字长度的两倍。如上所述,您可以从档案(ark)中读取Lattice,即使它包含CompactLattice,因为Holder类型(LatticeHolder)将执行自动转换。 因此,即使在"lats_rspecifier"中指定的归档文件或脚本文件包含CompactLattice格式(通常会这样),下面代码仍然有效,因为这是我们通常写Lattice的方式。
SequentialLatticeReader lattice_reader(lats_rspecifier);
for (; !lattice_reader.Done(); lattice_reader.Next()) {
std::string key = lattice_reader.Key();
Lattice lat = lattice_reader.Value();
...
}
格式类型转换的示例是:
Lattice lat;
// initialize lat.
CompactLattice compact_lat;
ConvertLattice(lat, &compact_lat);
转换为CompactLattice类型涉及一个"因式分解"操作,函数fst :: Factor()(由fstext / factor.h中的us定义),它标识出可以组合成一个CompactLattice弧的状态链。 将OpenFst算法应用于lattice的典型示例如下(此代码,从latbin / lattice-best-path.cc修改,找到通过lattice的最佳路径):
Lattice lat;
// initialize lat.
Lattice best_path;
fst::ShortestPath(lat, &best_path);
计算通过lattice的最佳路径
程序 lattice-best-path 计算通过lattice的最佳路径,并输出相应的输入符号序列(对齐,alignment)和输出符号序列(转录,transcription)。 像往常一样,输入和输出是以档案的形式。示例命令行是:
lattice-best-path --acoustic-scale=0.1 ark:in.lats ark:out.tra ark:out.ali
程序lattice-nbest计算通过lattice的N个最佳路径(使用OpenFst的ShortestPath()函数),并将结果作为lattice(CompactLattice)输出,但其具有特殊结构。 如OpenFst中的ShortestPath()函数所记录的,开始状态有(最多)n个发射弧,每个弧连接到一条单独路径的开始。 注意,这些路径可以共享后缀。 示例命令行是:
lattice-nbest --n=10 --acoustic-scale=0.1 ark:in.lats ark:out.nbest
语言模型重打分
因为LatticeWeight的"图部分"(第一部分)包含的语言模型得分与transition-model得分和任意发音或静音概率混合在一起的,所以我们不能将其替换为新的语言模型得分,否则我们会失去转移概率和发音概率。 相反,我们必须先减去"旧"LM概率,然后添加新的LM概率。 这两个阶段的核心操作是"组合"(也有一些权重的缩放)。 这样做的命令行是:首先,删除旧的LM概率:
lattice-lmrescore --lm-scale=-1.0 ark:in.lats G_old.fst ark:nolm.lats
然后添加新的LM概率:
lattice-lmrescore --lm-scale=1.0 ark:nolm.lats G_new.fst ark:out.lats
注意,还有其他方法来做到这一点;请参阅下面的lattice-compose的文档(告诉我们程序lattice-lmrescore是什么).实际上,我们将首先使用简单的版本。假设我们给出了LM-scale和LM G.fst。我们首先将G.fst中的所有代价乘以S.然后对于每个lattice,我们在右边用G组成它(L o G),对其使用lattice-determinize(仅保留每个单词序列通过G的最佳路径),并将其输出。这对positive S的效果良好,但对于negative S,它将相当于对每个单词序列采用通过G的最差路径。为了解决这个问题,我们做如下改动。对于每个输入的lattice,我们首先通过S的倒数来缩放点阵的语言模型(或LM)成本;我们然后在G.fst右边合成;我们对所得到的lattice运行lattice-determinize(参见上文),其对每个单词序列仅保留通过lattice的最佳路径;然后我们将lattice图/ LM分数缩放为S.这对于negative S是正确的。当输入的lattice对于每个单词序列仅具有通过它的单个路径时,上述过程才有意义(例如,如果它是lattice确定的)。我们假设在程序之间传递的所有lattice都有这个属性(这就是为什么写出"raw"状态级lattice不是一个好主意,除非你知道你在做什么)。
注意,为了使composition(组合的fst)工作,该程序需要将G.fst从"极小-加法半环"上映射到LatticeWeight半环。 这通过将G.fst的权重放入权重的第一部分("图"部分),并且将权重的第二部分置为零(在半环中,这是1)来做到这一点。在C++级别,这个映射使用OpenFst的MapFst机制来完成.其中,我们定义了一个Mapper类来将StdArc映射到LatticeArc,然后创建一个类型为MapFst的对象,根据需要进行评估,并将G.fst转换为LatticeWeight权重类型。
- lattice的改进
人们为了研究如何对ASR的输出建立有效的索引进行了
很多研究,lattice中包含大量的冗余信息,除了直接在lattice上建立索引之
外,人们还研究了如何去除lattice中的冗余信息。人们提出了类似lattice的
模型,但去除了lattice中的冗余信息,如混淆网络
[33]
和PSPLs(Position
SpecificPosteriorLattices)[34]。