cudamatrix/cublas-wrappers.h
该头文件对cuBLAS的接口进行了简单的封装(函数名的简化和部分kaldi函数的封装)。
比如
cublasSgemm_v2封装为cublas_gemm
cublas_copy_kaldi_fd和cublas_copy_kaldi_df封装为cublas_copy
cudamatrix/cu-kernels.{h,cu}
以cuda_add_col_sum_mat函数为例
对Kaldi cuda kernel或cublas进行了简单的封装(针对不同精度浮点型)
cudamatrix/cu-kernels.h
inline void cuda_add_col_sum_mat(int Gr, int Bl, double* result, const double* mat, const MatrixDim d, const double alpha, const double beta) { cudaD_add_col_sum_mat(Gr, Bl, result, mat, d, alpha, beta); } inline void cuda_add_col_sum_mat(int Gr, int Bl, float* result, const float* mat, const MatrixDim d, const float alpha, const float beta) { cudaF_add_col_sum_mat(Gr, Bl, result, mat, d, alpha, beta); } //... } |
kernel的定义
cudamatrix/cu-kernels.cu // Reduce a matrix 'mat' to a column vector 'result' template<EnumTransformReduce TransReduceType, typename Real> __global__ static void _transform_reduce_mat_cols( Real *result, const Real *mat, const MatrixDim d, const TransReduceOp<TransReduceType, Real> op) {
__shared__ Real sdata[CU1DBLOCK]; const int tid = threadIdx.x; const int i = blockIdx.x; const int row_start = i * d.stride;
Real tdata = op.InitValue(); for (int j = tid; j < d.cols; j += CU1DBLOCK) { tdata = op.Reduce(tdata, op.Transform(mat[row_start + j])); } sdata[tid] = tdata; __syncthreads();
// Tree reduce # pragma unroll for (int shift = CU1DBLOCK / 2; shift > warpSize; shift >>= 1) { if (tid < shift) sdata[tid] = op.Reduce(sdata[tid], sdata[tid + shift]); __syncthreads(); }
// Reduce last warp. Threads implicitly synchronized within a warp. if (tid < warpSize) { for (int shift = warpSize; shift > 0; shift >>= 1) sdata[tid] = op.Reduce(sdata[tid], sdata[tid + shift]); }
// Output to vector result. if (tid == 0) { result[i] = op.PostReduce(sdata[0], result[i]); } }
void cudaD_add_col_sum_mat(int Gr, int Bl, double* result, const double* mat, const MatrixDim d, const double alpha, const double beta) { _transform_reduce_mat_cols<<<Gr, Bl>>>(result, mat, d, TransReduceOp<SUMAB, double>(alpha, beta)); } |
cudamatrix/cu-vector.h
与matrix/kaldi-vector.h类似的,该头文件声明了几个向量类。与之不同的是,但其运算的实现基于CUDA或CBLAS。
class CuVectorBase
Cuda向量抽象类。该类对基础运算与内存优化进行了封装,只提供向量运算。不涉及尺寸缩放和构造函数。
尺寸缩放和构造函数由派生类CuVector和CuSubVector负责。
向量初始化
void SetZero();
向量信息
MatrixIndexT Dim() const { return dim_; }
向量的读取与转换
inline Real* Data() { return data_; }
inline Real operator() (MatrixIndexT i) const
CuSubVector<Real> Range(const MatrixIndexT o, const MatrixIndexT l)
向量的拷贝函数
void CopyFromVec(const CuVectorBase<Real> &v);
向量的运算
void ApplyLog();
void AddVec(const Real alpha, const CuVectorBase<OtherReal> &v, Real beta = 1.0);
//*this += alpha * M [or M^T]
//linear_params_.AddMat(alpha, other->linear_params_);
//linear_params_ += alpha * other->linear_params_
void AddMat ( const Real alpha,
const MatrixBase< Real > & M,
MatrixTransposeType transA = kNoTrans
)
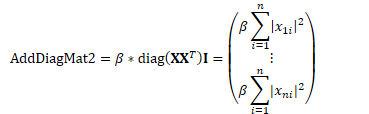
//*this = alpha * diag(M * M^T) + beta * *this
diag(M M^T)+beta ** M (1 2 3) (4 5 6) (7 8 9)
(1 4 7) (2 5 8) (3 6 9) (1^2+2^2+3^2, *, *) (*, 4^2+5^2+6^2, *) (*, *, 7^2+8^2+9^2) diag=() |
void CuVectorBase<Real>::AddDiagMat2(Real alpha, const CuMatrixBase<Real> &M,
MatrixTransposeType trans, Real beta) {
//*this = alpha * diag(M * M^T) + beta * *this
this->AddDiagMatMat(alpha, M, trans, M, other_trans, beta);
}
//*this = alpha * diag(M * N^T) + beta * *this
void CuVectorBase<Real>::AddDiagMatMat(Real alpha, const CuMatrixBase<Real> &M,
MatrixTransposeType transM,
const CuMatrixBase<Real> &N,
MatrixTransposeType transN, Real beta) {
// v = alpha * diag(M * N^T) + beta * v
static void _add_diag_mat_mat_MNT(const Real alpha, const Real* M,
const MatrixDim dim_M, const Real* N,
const int stride_N, const Real beta,
Real* v)
//data_ = alpha * diag(M.Data() * N.Data()^T) + beta * data_
cuda_add_diag_mat_mat_MNT(dimGrid, dimBlock, alpha, M.Data(), M.Dim(),
N.Data(), N.Stride(), beta, data_);
class CuVector: public CuVectorBase<Real>
该类表示普通Cuda向量,并实现尺寸缩放和一般的构造函数。
多种构造函数
explicit CuVector(const CuVector<Real> &v) : CuVectorBase<Real>() {
Resize(v.Dim(), kUndefined);
this->CopyFromVec(v);
}
template<typename OtherReal>
explicit CuVector(const CuVectorBase<OtherReal> &v) : CuVectorBase<Real>() {
Resize(v.Dim(), kUndefined);
this->CopyFromVec(v);
}
template<typename OtherReal>
explicit CuVector(const VectorBase<OtherReal> &v) : CuVectorBase<Real>() {
Resize(v.Dim(), kUndefined);
this->CopyFromVec(Vector<Real>(v));
}
重载赋值运算符
CuVector<Real> &operator = (const CuVectorBase<Real> &other) {
Resize(other.Dim(), kUndefined);
this->CopyFromVec(other);
return *this;
}
CuVector<Real> &operator = (const CuVector<Real> &other) {
Resize(other.Dim(), kUndefined);
this->CopyFromVec(other);
return *this;
}
CuVector<Real> &operator = (const VectorBase<Real> &other) {
Resize(other.Dim());
this->CopyFromVec(other);
return *this;
}
Utils
void Swap(CuVector<Real> *vec);
void Swap(Vector<Real> *vec);
void Resize(MatrixIndexT length, MatrixResizeType resize_type = kSetZero);
class CuSubVector: public CuVectorBase<Real>
该类表示一个不占有实际数据的泛化向量或向量索引,可以表示高级向量的子向量或矩阵的行。实现多种用于索引的构造函数。
多种构造函数
CuSubVector(const CuVectorBase<Real> &t, const MatrixIndexT origin,
const MatrixIndexT length) : CuVectorBase<Real>() {
KALDI_ASSERT(static_cast<UnsignedMatrixIndexT>(origin)+
static_cast<UnsignedMatrixIndexT>(length) <=
static_cast<UnsignedMatrixIndexT>(t.Dim()));
CuVectorBase<Real>::data_ = const_cast<Real*>(t.Data()+origin);
CuVectorBase<Real>::dim_ = length;
}
/// Copy constructor
/// this constructor needed for Range() to work in base class.
CuSubVector(const CuSubVector &other) : CuVectorBase<Real> () {
CuVectorBase<Real>::data_ = other.data_;
CuVectorBase<Real>::dim_ = other.dim_;
}
CuSubVector(const Real* data, MatrixIndexT length) : CuVectorBase<Real> () {
// Yes, we're evading C's restrictions on const here, and yes, it can be used
// to do wrong stuff; unfortunately the workaround would be very difficult.
CuVectorBase<Real>::data_ = const_cast<Real*>(data);
CuVectorBase<Real>::dim_ = length;
}
cudamatrix/cu-matrix.h
与matrix/kaldi-matrixr.h类似的,该头文件声明了几个矩阵类。与之不同的是,但其运算的实现基于CUDA或CBLAS。当Kaldi基于CUDA环境编译且GPU可用(CuDevice::Instantiate().Enabled() == true)则使用CUDA卡进行计算,否则使用CPU进行计算(CBLAS)。
class CuMatrixBase
Cuda矩阵抽象类。该类对基础运算与内存优化进行了封装,只提供矩阵运算。不涉及尺寸缩放和构造函数。
尺寸缩放和构造函数由派生类CuMatrix和CuSubMatrix负责。
class CuMatrix
该类表示普通Cuda矩阵,并实现尺寸缩放和一般的构造函数。
class CuSubMatrix
该类表示一个不占有实际数据的泛化矩阵或矩阵索引,可以表示其他矩阵的矩阵。实现多种用于索引的构造函数。
继承于CuMatrixBase,用于对矩阵的子矩阵(块矩阵)进行运算。