R. Amiri, M. A. Almasi, J. G. Andrews and H. Mehrpouyan, "Reinforcement Learning for Self Organization and Power Control of Two-Tier Heterogeneous Networks," in IEEE Transactions on Wireless Communications, vol. 18, no. 8, pp. 3933-3947, Aug. 2019.
doi: 10.1109/TWC.2019.2919611
keywords: {decision making;distributed control;distributed power generation;learning (artificial intelligence);Markov processes;multi-agent systems;network theory (graphs);power control;power system control;self-adjusting systems;Q-learning-based distributed power allocation algorithm;heterogeneous network interference;transmit power adaptation;Q-DPA algorithm;self-organizing mechanism;power optimization problem;multiagent Markov decision process;data-driven decision making;machine learning;HetNet;self-organizing networks;two-tier heterogeneous networks;power control;reinforcement learning;Interference;Femtocells;Macrocell networks;Quality of service;Signal to noise ratio;Wireless communication;Resource management;Self-organizing networks;HetNets;reinforcement learning;Markov decision process},
URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8731967&isnumber=8794662
摘要:自组织网络(SON)可以帮助管理密集异构网络(HetNets)中的严重干扰。鉴于需要自动配置功率和其他设置,机器学习是SON中数据驱动决策的有前途的工具。在本文中,HetNet被建模为密集的双层网络,其中传统的宏小区覆盖有更密集的小小区(例如,毫微微小区或微微小区)。首先,提出了一种基于多智能体马尔可夫决策过程的分布式框架,对网络中的功率优化问题进行建模。其次,我们提出了一种基于优化问题设计奖励函数的系统方法。第三,我们引入基于Q学习的分布式功率分配算法(Q-DPA)作为自组织机制,当新的小小区被添加到网络时,该机制能够实现持续的发射功率自适应。此外,提供了Q-DPA算法的样本复杂度以高概率地实现ε-最优性。仿真证明,在每平方公里几千个毫微微蜂窝的密度下,通过适当选择独立或合作学习和适当的马尔可夫状态模型,可以保持宏蜂窝用户所需的服务质量。
关键词:自组织网络,HetNets,强化学习,马尔可夫决策过程
引言:
自组织网络(SON)可以执行自我配置,自我优化和自我修复。这些操作可以涵盖基本任务,例如新安装的基站(BS)的配置,资源管理和网络中的故障管理。换句话说,SON尝试最小化人为干预,使用来自网络的测量值来最小化网络的安装,配置和维护成本。实际上,SON带来了两个主要因素:智能和自适应性。因此,机器学习技术可以在处理未充分利用传感数据中起主要作用,以提高SON的性能。
SON的主要职责之一是配置各种小型BS的发射功率以管理干扰。事实上,小型BS需要在加入网络之前配置其发射功率(作为自我配置)。随后,它需要在其在网络中的操作期间动态地控制其发射功率(作为自优化)。为了解决这两个问题,考虑将宏小区网络覆盖在小小区上,并专注于自主分布式功率控制,这是自组织的关键要素,因为它可以提高网络吞吐量并最大限度地减少能量使用。通过本地测量数据,例如信号与干扰加噪声比(SINR),以及使用机器学习来开发可以不断改进上述性能指标的SON框架。
A.相关工作
RL是机器学习的一个领域,其试图优化BS的发射功率以实现诸如吞吐量最大化之类的特定目标。RL在监督学习方法方面的主要优点之一是其训练阶段,其中不需要正确的输入/输出数据。实际上,RL通过应用与网络交互获得的经验来运作。
Q学习是一种无模型的RL方法。 Q-learning的无模型特征使其成为网络统计不断变化的场景的有效方法。此外,Q学习具有低计算复杂度并且可以由BS以分布式方式实现。因此,Q-learning可以为大型网络带来可扩展性,健壮性和计算效率。然而,设计一个适当的奖励功能,加速学习过程,避免虚假学习或学习现象[30]并非易事。因此,为了解决优化问题,需要确定用于Q学习的适当奖励函数。然而在最早的一些方案中,奖励函数不适用于密集网络。也就是说,首先,毫微微小区的可实现速率没有最小阈值。其次,奖励函数旨在将宏小区用户速率限制为其所需的QoS,而不是更高。该属性通过假设所引起的干扰仅影响宏小区用户来鼓励FBS使用更多功率来增加其自身速率。然而,邻居毫微微小区受此决定的影响,并且整体上网络的总和速率降低。此外,它们没有提供用于将HetNet建模为多智能体RL网络的通用框架或者设计满足网络的QoS要求的奖励函数的过程。在本文中,聚焦密集网络,并尝试为上述挑战提供一般解决方案。
B.贡献
提出了一个基于多智能体马尔可夫决策过程(MDP)的学习框架。通过将FBS视为agent,所提出的框架使FBS能够自主地加入并适应密集网络。由于毫微微蜂窝基站的无计划和密集部署,向网络中的所有用户提供所需的QoS成为一个重要问题。因此,本文设计了奖励函数和训练FBS以实现这一目标。此外,本文引入了基于Qlearning的分布式功率分配方法(Q-DPA)作为所提出框架的应用。使用Q-DPA所提出的奖励函数来最大化毫微微小区的传输速率,同时优先考虑宏小区用户的QoS。
本文贡献如下:
1)提出一个与学习方法选择无关但能将所需的RL类比连接到无线通信的框架。该框架使用单个MDP模拟多智能体网络,其中每个MDP包含了所有Agent的联合操作并作为其动作集。
2)提出了一种基于优化问题和RL性质设计奖励函数的系统方法。实际上,由于密集网络中的资源稀缺,本文提出了奖励函数的一些属性,以满足所有用户的最低要求的同时最大化网络的总传输速率。该过程简单通用,且设计的奖励函数采用低复杂度多项式的形式。此外,与基于贪婪的算法相比,所设计的奖励函数增加了网络可实现的总传输速率,同时消耗的功率大大减少。
3)提出Q-DPA作为所提出的框架的应用,以在密集的毫微微蜂窝网络中执行分布式功率分配。Q-DPA使用因子分解方法从最优解中导出独立和合作学习。Q-DPA在毫微微小区使用本地信号测量来训练FBS,以便:(i)最大化毫微微小区的传输速率,(ii)以高概率实现所有毫微微小区用户所需的最低QoS,(iii)维持密集部署的毫微微蜂窝网络中的宏蜂窝用户的QoS。此外,将在Q-DPA中实现ε最优策略所需的最小样本数量作为其样本复杂度。
4)基于独立/合作学习和马尔可夫状态模型的不同组合引入四种不同的学习配置。通过进行广泛的模拟,以量化不同学习配置对网络性能的影响。仿真表明,所提出的Q-DPA算法可以降低功耗,从而减少对宏小区用户的干扰。
下行系统模型
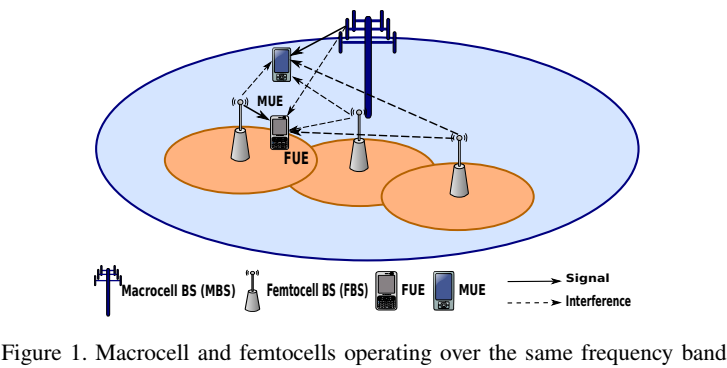
为了控制干扰电平并向用户提供其所需的最小SINR,关注毫微微小区网络的下行链路中的功率分配。
本文针对一个子带,同时所提出的解决方案可以扩展到每个FBS支持不同子带上的多个用户的情况。
MUE的SINR:
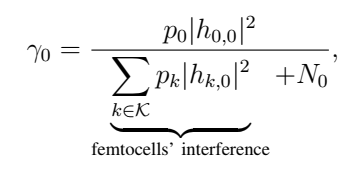
FUE的SINR:

本文针对密集网络(密度导致跨层和干扰),在低密度网络中可以忽略该干扰项,但在由大量毫微微蜂窝基站组成的密集网络中不能忽略。
问题制定:
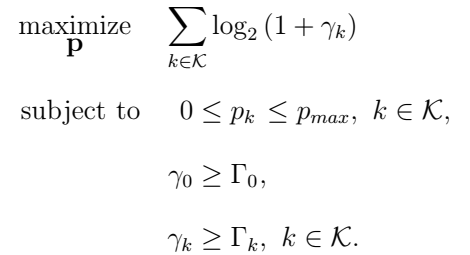
存在缺点:非凸性;迭代算法对实时实现提出了挑战;仅知道第K个FBS的发射功率而不知道剩余FBS的发射功率。
解决:将给定的问题视为黑盒,并尝试通过与网络交互和简单计算逐渐学习发射功率与所得传输速率之间的关系。
如果实现自组织,每个FBS能够自主运行,则FBS能够随时连接到网络并不断调整其发射功率以实现目标。因此,优化问题需要自适应解决方案。实现自适应的步骤可概括为:(i)FBS测量其相关FUE的干扰电平,(ii)确定支持FUE的最大发射功率,同时不会大大降低网络中其他用户的性能。
学习框架:
A.多智能体MDP和策略评估
单个智能体MDP包括智能体,环境,动作集和状态集。智能体可以通过选择不同的操作在不同的状态之间转换。智能体程序采取的操作跟踪称为策略。随着每次转换,智能体将从其环境中获得奖励,作为其行动的结果,并且将折扣的奖励总额保存为累积奖励。智能体将继续其行为,目标是最大化累积奖励,累积奖励的价值评估所选择的策略。折扣财产增加了近期奖励的影响,并降低了后期奖励的影响。如果转换的数量有限,则也可以使用非折扣的奖励总和。
公式见笔记
本文依靠强化学习(RL)来推导出最优的Q函数。RL使用时间差为广义策略迭代(GPI)方法提供实时解决方案
B.MDP系数
在大型MDP中,由于关联状态 - 动作空间的大小相对于智能体数量的指数增加,问题的解决方案变得难以解决。为解决此问题,使用因式MDP作为大型MDP的分解技术。对于事实上的MDP,想法是许多大型MDP由具有许多弱互连部分的系统生成。每个部分都有其关联的状态变量,状态空间可以相应地计入子集。子集的定义会影响解的最优性,研究最优分解方法有助于理解多智能体RL解决方案的最优性。在文献[36]中,多跳网络的功率控制被建模为MDP,并且状态集被分解为多个子集,每个子集指向单跳。文献[37]表明,子集可以根据来自环境的代理的本地知识来定义。同时,我们的目标是将功率控制分配给网络节点。因此,由于问题的定义以及每个FBS只知道自身能力的事实,使用[37]中的假设并定义代理的个体动作集。[ C. Guestrin, M. Lagoudakis, R. Parr, "Coordinated reinforcement learning", Proc. ICML, pp. 227-234, Jul. 2002.]
C.毫微微小区蜂窝网作为多智能体MDP

在无线通信系统中,资源管理策略等同于MDP中的策略功能。为了将毫微微蜂窝网络集成在多智能体MDP中,根据上图定义了以下内容。
•环境:从FBS的角度来看,环境由宏蜂窝和所有其他毫微微蜂窝组成。


Q-DPA,奖励功能和样本复杂性:
A.基于Q学习的分布式功率分配(Q-DPA)
FBS的训练发生在L帧上。在每帧的开始,FBS选择动作,即发射功率。然后,FBS将帧发送到预期的FUE。 FUE反馈所需的测量值,例如CQI,因此FBS可以估计FUE处的SINR,并计算奖励。最后,FBS更新其Q表。
由于训练帧数量有限,每个FBS需要以覆盖大部分动作空间的方式选择其动作,同时改进策略。因此,FBS选择结合探索exploration (随机策略)和利用exploitation(确定性策略)的行动,称为电子贪婪的探索。在e-greedy方法中,FBS以概率 1-e(即,利用)贪婪地行动并随机地以概率e(即,探索)行动。在利用中,FBS选择在其自己的Q表(独立学习)或Q表(合作学习)的总和中具有当前状态的最大值的动作。在探索中,FBS随机选择一个动作以覆盖动作空间并避免偏向局部最大值。先前的研究显示对于有限次数的迭代,与仅利用或探索相比,电子贪婪策略导致更接近最佳值的最终值。
1-e(即,利用)贪婪地行动并随机地以概率e(即,探索)行动。在利用中,FBS选择在其自己的Q表(独立学习)或Q表(合作学习)的总和中具有当前状态的最大值的动作。在探索中,FBS随机选择一个动作以覆盖动作空间并避免偏向局部最大值。先前的研究显示对于有限次数的迭代,与仅利用或探索相比,电子贪婪策略导致更接近最佳值的最终值。
B.奖励函数
奖励功能的设计至关重要,因为它直接影响FBS的目标。通常,没有设计奖励函数的定量方法。在这里,我们提出了一种系统的方法,用于根据所考虑的优化问题的性质推导出奖励函数。然后,将设计的奖励函数的行为与文献[19] - [21]中的行为进行比较。
第k个FBS的奖励函数被视为上述四个变量的函数:MUE的最小所需SINR,FUE所需的最小SINR,每次行动后MUE和第k个FUE的速率。
为了设计适当的奖励函数,需要估计第k个FBS朝向优化问题目标的进度。根据奖励函数的输入参数,定义了两个进度估算器,,一个用于MUE,一个用于第k个FUE。为了降低计算复杂度,将奖励函数定义为进度估计器的多项式函数:
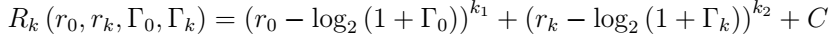
奖励函数中的恒定偏差C对学习算法有两个影响:(i)给定策略π的状态的最终值,(ii)agent在学习过程开始时的行为如下:
1)偏差对状态最终值的影响:
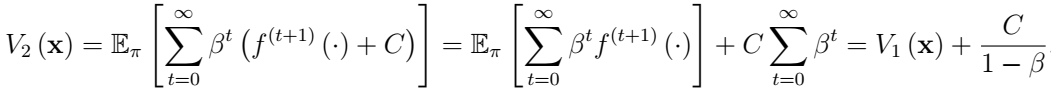
奖励函数的偏差将常数值 c/(1-ß)添加到状态的值。然而,在算法收敛之后,所有状态都受到相同的影响。
c/(1-ß)添加到状态的值。然而,在算法收敛之后,所有状态都受到相同的影响。
2)在学习过程开始时偏差的影响:
使用Q函数,假设agent的Q函数初始化为零值
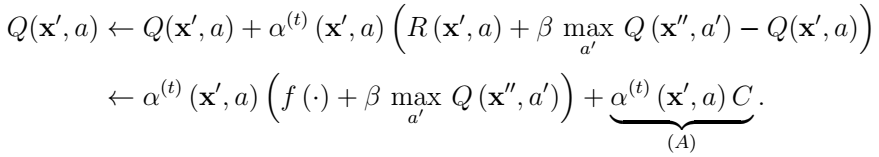
因此,只要agent没有对状态空间进行足够的探索,已经访问过的状态在学习过程的开始或多或少会对代理有吸引力。
agent在学习过程中的行为变化可以用来使主体偏向期望的动作或状态。 但是,在基本的Q学习中,agent事先不了解环境。 因此,我们选择偏差等于零,C = 0,并将奖励函数定义为
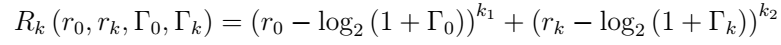
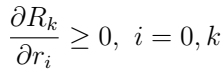
本文设计奖励函数:
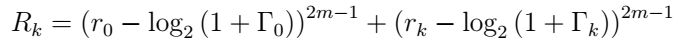
二阶奖励函数行为:
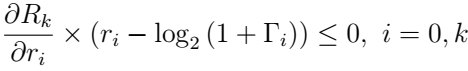
指数和接近度奖励函数行为:
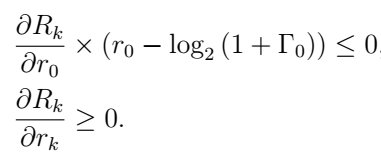
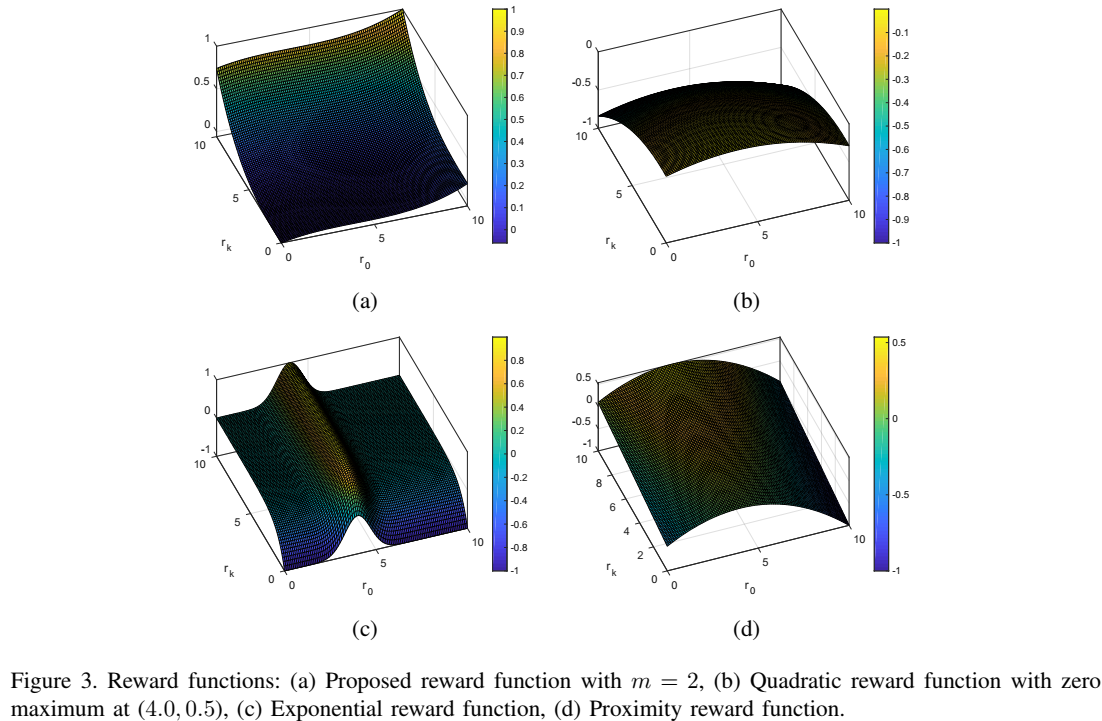
 m=2所提的奖励函数,(b)二阶奖励函数,最大值为零(4.0,0.5),(c)指数奖励函数,(d)邻近奖励函数。
m=2所提的奖励函数,(b)二阶奖励函数,最大值为零(4.0,0.5),(c)指数奖励函数,(d)邻近奖励函数。 或MUE的速率
或MUE的速率 来奖励函数的行为。图3a中提出的奖励函数显示推动FBS选择增加
来奖励函数的行为。图3a中提出的奖励函数显示推动FBS选择增加 第k个FUE的速率和MUE的速率的发射功率电平,而其他奖励函数在最小速率要求附近具有其最大值。
第k个FUE的速率和MUE的速率的发射功率电平,而其他奖励函数在最小速率要求附近具有其最大值。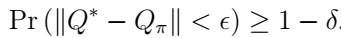
样本复杂性取决于生成样本的探索策略。在Q-DPA中,e-greedy策略被用作探索策略。但是,e-greedy策略取决于正在更新的agent的Q函数。事实上,电子贪婪政策的分布是未知的。本文提供了Q学习的样本复杂性的一般约束。
命题1:
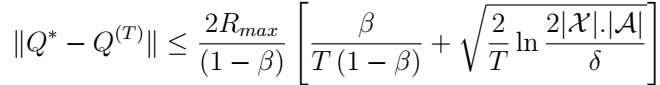
这个命题证明了Q学习的稳定性
推论:
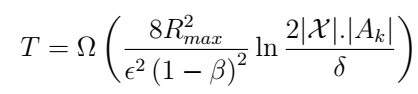
仿真结果:
A.仿真设置
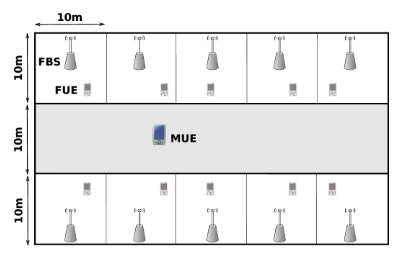

为了执行Q学习,基于实现90%的最优性,概率至少为0.9,即 δ=0.1,计算所需帧的最小数量,即L.模拟参数在表II中给出。
δ=0.1,计算所需帧的最小数量,即L.模拟参数在表II中给出。
模拟从一个毫微微蜂窝基站开始。 FBS使用IL运行Q-DPA。收敛后,下一个FBS将添加到网络中。新的FBS运行Q-DPA,而另一个FBS已经过训练,并且只会贪婪地选择其发射功率。
表二:模拟参数第二个FBS收敛后,下一个FBS被添加到网络中,依此类推。将所有结果与系统中活动femtocell的数量相对应,从1到10。
B. Q-DPA的性能
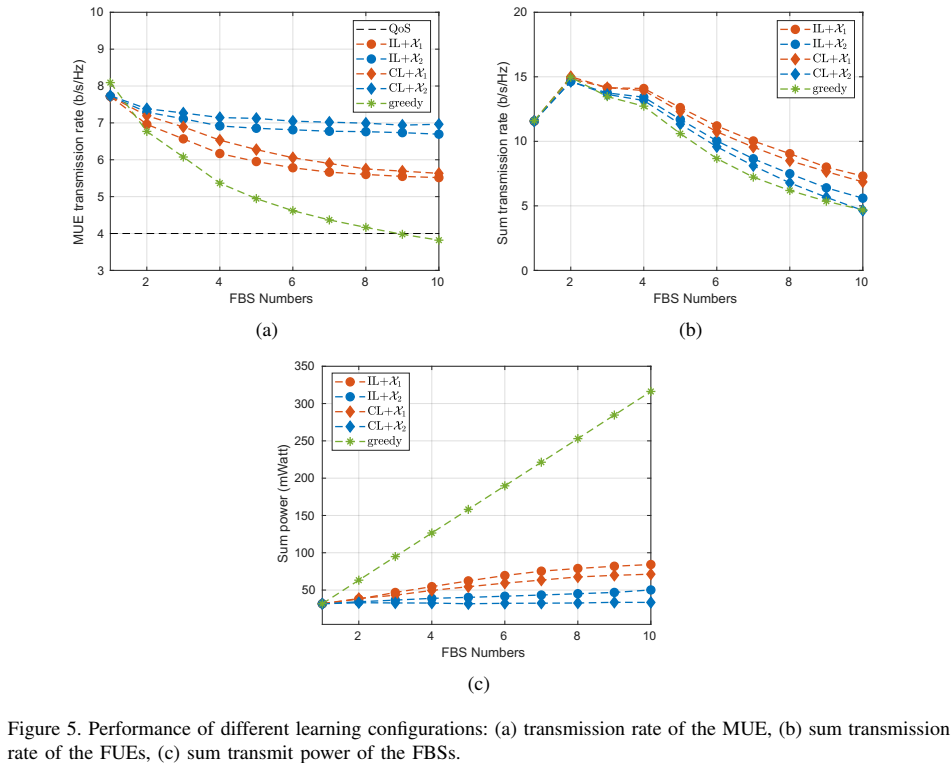
在表III中,我们比较了四种学习配置的表现。在每列中,数字1用作指标,表示达到的最高性能,数字4用于表示观察到的最低性能。第一列表示FBS的发送功率的总和,第二列表示FUE的传输速率的总和,第三列表示MUE的传输速率。
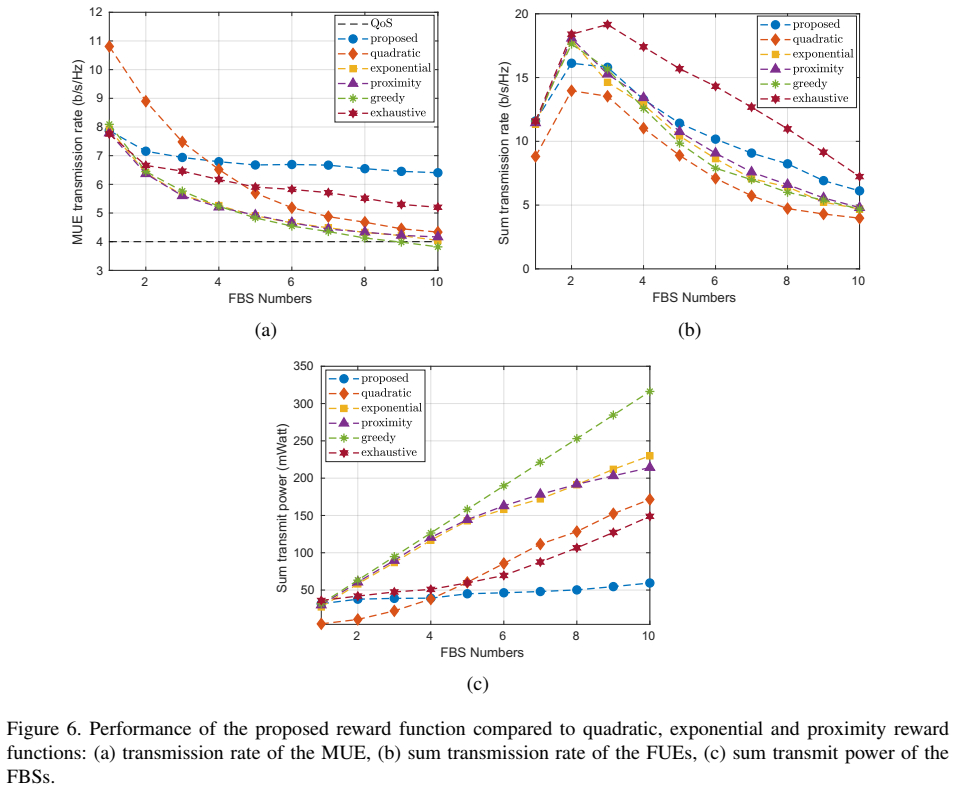
根据图5c,在贪婪算法中,每个FBS使用最大可用功率进行传输。 因此,贪婪方法在MUE中引入了最大的干扰,并且在图5a中具有最低的MUE传输速率。 另一方面,尽管使用了最大功率,但贪婪算法也无法实现FUE的最高传输速率(图5b)。 这又是由于高干扰水平。

从模拟结果中得出结论,IL和CL存在不同的权衡。更具体地,IL支持更高的FBS总和传输速率和更低的MUE传输速率,而CL可以支持更高的MUE传输速率,代价是FBS的整体较低的总传输速率。从功耗的角度来看,与CL相比,IL会导致更高的功耗。一般来说,IL训练FBS与CL相比是自我选择。当agent之间没有通信手段时,IL非常有用。另一方面,CL训练FBS以通信开销为代价更加考虑其他FBS。
C.奖励函数性能

在本文中,我们提出了一个双层femtocell网络的学习框架。该框架允许向网络添加新的毫微微蜂窝基站,而毫微微蜂窝基站自身训练以调整其发射功率以支持其服务用户,同时保护宏蜂窝用户。另一方面,作为分布式方法的所提出的方法可以解决密集HetNets中的功率优化问题,同时显着降低功率使用。所提出的框架是通用的,并且激励用于毫微微蜂窝网络中的管理方案的基于机器学习的SON的设计。此外,该框架可用作评估不同学习配置(如马尔可夫状态模型,奖励函数和学习率)的绩效的基准测试。此外,所提出的框架也可以应用于其他受干扰限制的网络,例如认知无线电网络。
在未来的工作中,在当前设置中考虑启用mmWave的femtocell会很有趣。事实上,高路径损耗和阴影以及mmWave方向信号对阻塞的脆弱性会影响学习效果[43]。这将反过来影响随后的功率优化问题。另外,正如我们在仿真部分中详细讨论的那样,所提出的方法与穷举搜索之间存在性能差距。虽然,所提出的方法导致较少的计算复杂性;我们希望通过利用神经网络作为学习方法的函数逼近来改进和弥补这一差距。实际上,神经网络可以更有效地处理大型状态动作空间。此外,另一个未来的补充工作是实现更高的数据速率和填补性能差距,将网络的干扰模型提供给分解过程。这样,可以为全局Q函数提供更好的分解。