>>> s="abc"
>>> type(s)
<class 'str'>
>>> s=u"abc"
>>> type(s)
<class 'str'>
>>> s=b"abc"
>>> type(s)
<class 'bytes'>
>>> s="abc"
>>> d="abc"
>>> s is d
True
>>> s="好好学习"
>>> s=b"好好学习"
File "<stdin>", line 1
SyntaxError: bytes can only contain ASCII literal characters.
>>> s.encode("gbk")
b'xbaxc3xbaxc3xd1xa7xcfxb0'
>>> s.encode("gbk").decode("gbk")
'好好学习'
遍历
>>> for i in "abc":
... print(i)
...
a
b
c
>>> s="abc"
>>> for i in range(len(s)):
... print(s[i])
...
a
b
c
>>>
>>> s="abcdefg"
>>> s[0]
'a'
>>> s[-1]
'g'
>>> s[-2]
'f'
>>> s[3:6]
'def'
>>> s[3:9:2]
'df'
>>> s[::-1]
'gfedcba'
>>>字符串不能被修改的,可以转化为list再进行修改
>>> type(s)
<class 'str'>
>>> list(s)
['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>>
>>> s
'abcdefg'
>>> s.split()
['abcdefg']
>>> list(s)
['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> a=list(s)
>>> del a[3:6]
>>> a
['a', 'b', 'c', 'g']
>>> "".join(a)
'abcg'
>>>
>>> dir("abc")
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
>>> "a b c d".split()
['a', 'b', 'c', 'd']
>>> "a
b c d".split()
['a', 'b', 'c', 'd']
>>> "a||b||c".split("||")
['a', 'b', 'c']
>>> "a
b
c".splitlines()
['a', 'b', 'c']
>>> "a
b
c".splitlines()
['a', 'b', 'c']
>>> "a
b
c".splitlines()
['a', 'b', '', 'c']
>>>
>>> "a
b
c".splitlines(13)
['a
', 'b
', 'c']
>>> "".joint([1,2])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'joint'
>>> "".join(["1","2"]) #join里传参必须是list
'12'
>>> "**".join(["1","2"])
'1**2'
>>> "abcabcc".count("a")
2
>>> "abcabcddsab".count("ab")
3
>>> "
abc
".lstrip()
'abc
'
>>> "
abc
".rstrip()
File "<stdin>", line 1
"
abc
".rstrip()
^
IndentationError: unexpected indent
>>> "
abc
".rstrip()
'
abc'
>>> "aaaavvvbbbb".strip("a")
'vvvbbbb'
>>> "aaabbbbbssssddd".lstrip("a") #strip清除空格
'bbbbbssssddd'
>>> "aaabbbbbssssddd".rstrip("a")
'aaabbbbbssssddd'
>>> " a b ".strip() #只会去除掉边界前后的空格,a和b之间的 空格不会处理
'a b'
>>> "ABDcs".lower()
'abdcs'
>>> "ABDfef".upper()
'ABDFEF'
>>> "i am a girl".title()
'I Am A Girl'
>>> "abdffs".find("cd") #找不到返回-1
-1
>>> "abdddsdf".find("ds")
4
>>> "abdddb".index("afe") #index 找不到就报错,异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>>如果不想报错就try ..except。。
>>> try:
... "abcdef".index("cdx")
... except ValueError: #except 后面不指定就会拦截所有异常
... print("cdx is not found")
...
cdx is not found
>>>格式化输出,打印东西使用如下

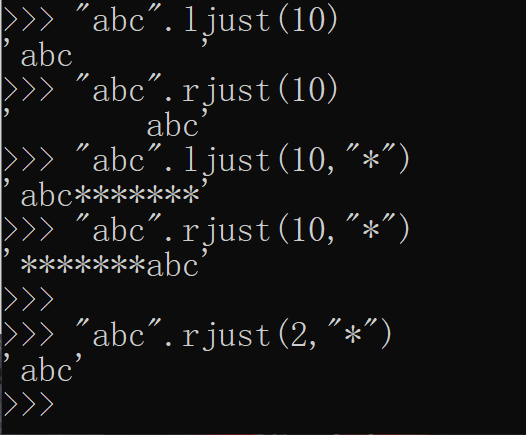
>>> "abcd".replace("ab","***")
'***cd'
>>> "i am a girl!".capitalize()
'I am a girl!'
>>> "abcdfs".startwith("abc")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'startwith'
>>> "abdcdffr".startswith("abc")
False
>>> "abcddsfd".startswith("bc")
False
>>> "abcdd".endwith("ef")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'endwith'
>>> "abcdd".endswith("ef")
False
>>> "abdcd".endswith("ed")
False
>>> "abcdd".endswith("ef")
False
>>> "abdcd".endswith("ed")
False
>>> "abc".isdigit()
False
>>> "1123".isdigit()
True
>>> "123.123".isdigit()
False
>>> "ab".isnumeric()
False
>>> "AB".isupper()
True
>>> "Ab".isupper()
False
>>> "Ab".isupper()
False
>>> "Abs".islower()
False
>>> "abd".islower()
True
>>>
>>> "abd".zfill(10) #补零
'0000000abd'
习题
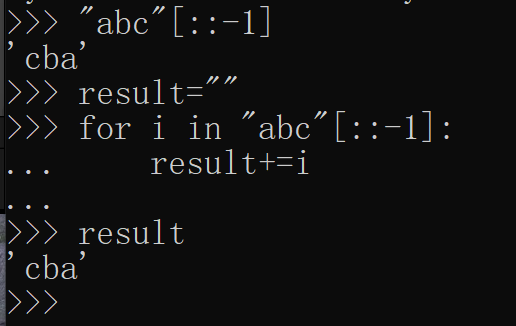
1.反转:
两种方法
1)切片
>>> s="abcd"
>>> s[::-1]
'dcba'
2)循环abc-》cba

2.去重
abvbbccc->abvc
>>> set("abc")
{'b', 'c', 'a'}
>>> set("abcabc")
{'b', 'c', 'a'}
>>> "".join(set("abcabc"))
'bca'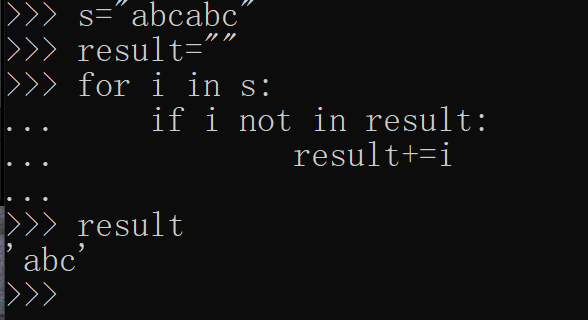
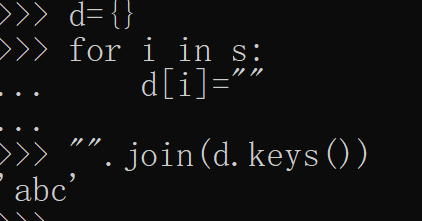
3.统计单词的字母数量
>>> "God is a girl".split()
['God', 'is', 'a', 'girl']
>>> len("God is a girl".split())
4