1.背景知识(进程、多道技术)
顾名思义,进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。
进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。
了解操作系统,详见:https://www.cnblogs.com/JackLi07/p/9226851.html
#一 操作系统的作用: 1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口 2:管理、调度进程,并且将多个进程对硬件的竞争变得有序 #二 多道技术: 1.产生背景:针对单核,实现并发 ps: 现在的主机一般是多核,那么每个核都会利用多道技术 有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个 cpu中的任意一个,具体由操作系统调度算法决定。 2.空间上的复用:如内存中同时有多道程序 3.时间上的复用:复用一个cpu的时间片 强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样 才能保证下次切换回来时,能基于上次切走的位置继续运行
2.python并发编程之多进程(理论)
进程:正在进行的一个过程或者说一个任务。而负责执行任务则是cpu。
2.1进程与程序的区别
程序仅仅只是一堆代码而已,而进程指的是程序的运行过程。
需要强调的是:同一个程序执行两次,那也是两个进程,比如打开暴风影音,虽然都是同一个软件,但是一个可以播放体育世界,一个可以播放电影世界。
2.2并发与并行
一 并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
二 并行:同时运行,只有具备多个cpu才能实现并行
单核下,可以利用多道技术,多个核,每个核也都可以利用多道技术(多道技术是针对单核而言的)
有四个核,六个任务,这样同一时间有四个任务被执行,假设分别被分配给了cpu1,cpu2,cpu3,cpu4,
一旦任务1遇到I/O就被迫中断执行,此时任务5就拿到cpu1的时间片去执行,这就是单核下的多道技术
而一旦任务1的I/O结束了,操作系统会重新调用它(需知进程的调度、分配给哪个cpu运行,由操作系统说了算),可能被分配给四个cpu中的任意一个去执行

所有现代计算机经常会在同一时间做很多件事,一个用户的PC(无论是单cpu还是多cpu),都可以同时运行多个任务(一个任务可以理解为一个进程)。
启动一个进程来杀毒(360软件)
启动一个进程来看电影(暴风影音)
启动一个进程来聊天(腾讯QQ)
所有的这些进程都需被管理,于是一个支持多进程的多道程序系统是至关重要的
多道技术概念回顾:内存中同时存入多道(多个)程序,cpu从一个进程快速切换到另外一个,使每个进程各自运行几十或几百毫秒,这样,虽然在某一个瞬间,一个cpu只能执行一个任务,但在1秒内,cpu却可以运行多个进程,这就给人产生了并行的错觉,即伪并发,以此来区分多处理器操作系统 的真正硬件并行(多个cpu共享同一个物理内存)
2.3同步异步and阻塞非阻塞(重点)
同步:
#所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回。按照这个定义,其实绝大多数函数都是同步调用。但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务。 #举例: #1. multiprocessing.Pool下的apply #发起同步调用后,就在原地等着任务结束,根本不考虑任务是在计算还是在io阻塞,总之就是一股脑地等任务结束 #2. concurrent.futures.ProcessPoolExecutor().submit(func,).result() #3. concurrent.futures.ThreadPoolExecutor().submit(func,).result()
异步:
#异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果。当该异步功能完成后,通过状态、通知或回调来通知调用者。如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(有些初学多线程编程的人,总喜欢用一个循环去检查某个变量的值,这其实是一种很严重的错误)。如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作。至于回调函数,其实和通知没太多区别。 #举例: #1. multiprocessing.Pool().apply_async() #发起异步调用后,并不会等待任务结束才返回,相反,会立即获取一个临时结果(并不是最终的结果,可能是封装好的一个对象)。 #2. concurrent.futures.ProcessPoolExecutor(3).submit(func,) #3. concurrent.futures.ThreadPoolExecutor(3).submit(func,)
阻塞:
#阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到io操作)。函数只有在得到结果之后才会将阻塞的线程激活。有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。 #举例: #1. 同步调用:apply一个累计1亿次的任务,该调用会一直等待,直到任务返回结果为止,但并未阻塞住(即便是被抢走cpu的执行权限,那也是处于就绪态); #2. 阻塞调用:当socket工作在阻塞模式的时候,如果没有数据的情况下调用recv函数,则当前线程就会被挂起,直到有数据为止。
非阻塞:
#非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程。
小结*:
#1. 同步与异步针对的是函数/任务的调用方式:同步就是当一个进程发起一个函数(任务)调用的时候,一直等到函数(任务)完成,而进程继续处于激活状态。而异步情况下是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行当,函数返回的时候通过状态、通知、事件等方式通知进程任务完成。 #2. 阻塞与非阻塞针对的是进程或线程:阻塞是当请求不能满足的时候就将进程挂起,而非阻塞则不会阻塞当前进程
2.4进程的创建
但凡是硬件,都需要有操作系统去管理,只要有操作系统,就有进程的概念,就需要有创建进程的方式,一些操作系统只为一个应用程序设计,比如微波炉中的控制器,一旦启动微波炉,所有的进程都已经存在。
而对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为4种形式创建新的进程:
1. 系统初始化(查看进程linux中用ps命令,windows中用任务管理器,前台进程负责与用户交互,后台运行的进程与用户无关,运行在后台并且只在需要时才唤醒的进程,称为守护进程,如电子邮件、web页面、新闻、打印)
2. 一个进程在运行过程中开启了子进程(如nginx开启多进程,os.fork,subprocess.Popen等)
3. 用户的交互式请求,而创建一个新进程(如用户双击暴风影音)
4. 一个批处理作业的初始化(只在大型机的批处理系统中应用)
无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的:
1. 在UNIX中该系统调用是:fork,fork会创建一个与父进程一模一样的副本,二者有相同的存储映像、同样的环境字符串和同样的打开文件(在shell解释器进程中,执行一个命令就会创建一个子进程)
2. 在windows中该系统调用是:CreateProcess,CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
关于创建的子进程,UNIX和windows
1.相同的是:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),任何一个进程的在其地址空间中的修改都不会影响到另外一个进程。
2.不同的是:在UNIX中,子进程的初始地址空间是父进程的一个副本,提示:子进程和父进程是可以有只读的共享内存区的。但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的。
2.5进程的终止
1. 正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,在windows中用ExitProcess)
2. 出错退出(自愿,python a.py中a.py不存在)
3. 严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...)
4. 被其他进程杀死(非自愿,如kill -9)
2.6进程的层次结构
无论UNIX还是windows,进程只有一个父进程,不同的是:
1. 在UNIX中所有的进程,都是以init进程为根,组成树形结构。父子进程共同组成一个进程组,这样,当从键盘发出一个信号时,该信号被送给当前与键盘相关的进程组中的所有成员。
2. 在windows中,没有进程层次的概念,所有的进程都是地位相同的,唯一类似于进程层次的暗示,是在创建进程时,父进程得到一个特别的令牌(称为句柄),该句柄可以用来控制子进程,但是父进程有权把该句柄传给其他子进程,这样就没有层次了。
2.7进程的状态
一个进程有三种状态:运行、阻塞、就绪
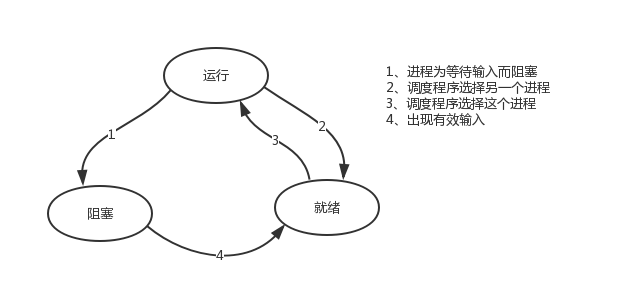
2.8进程并发的实现
进程并发的实现在于,硬件中断一个正在运行的进程,把此时进程运行的所有状态保存下来,为此,操作系统维护一张表格,即进程表(process table),每个进程占用一个进程表项(这些表项也称为进程控制块)

该表存放了进程状态的重要信息:程序计数器、堆栈指针、内存分配状况、所有打开文件的状态、帐号和调度信息,以及其他在进程由运行态转为就绪态或阻塞态时,必须保存的信息,从而保证该进程在再次启动时,就像从未被中断过一样。
3.python并发编程之多进程(python实现)
3.1multiprocessing模块介绍
python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程。Python提供了multiprocessing。
multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。
multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
需要再次强调的一点是:与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
3.2Process类的介绍
创建进程的类:
#Process([group [, target [, name [, args [, kwargs]]]]]) 由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
group参数未使用,值始终为None target表示调用对象,即子进程要执行的任务 args表示调用对象的位置参数元组,args=(1,2,'jack',) 注意最后面的逗号不要忘记 kwargs表示调用对象的字典,kwargs={'name':'jack','age':18} name为子进程的名称
方法介绍:
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间。
属性介绍:
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
3.3Process类的使用(两种方式开启进程)
注意:在windows中Process()必须放到# if __name__ == '__main__':下
创建并开启子进程的方式一(面向过程):
from multiprocessing import Process import time def task(name): print('%s is running' % name) time.sleep(3) print('%s is done' % name) if __name__ == '__main__': p = Process(target=task, args=('子进程1',)) p.start() # 仅仅只是给操作系统发了一个信号,父子进程均为独立运行,相互不影响 print('主进程')
创建并开启子进程的方式二(面向过程):
from multiprocessing import Process import time class MyProcess(Process): # 必须继承Process类 def __init__(self, name): super().__init__() self.name = name def run(self): # 进程函数用run表示 print('%s is running' % self.name) time.sleep(3) print('%s is done' % self.name) if __name__ == '__main__': p = MyProcess('子进程1') p.start() print('主')
3.4Process对象的属性或方法
3.4.1 Process对象的属性:name与pid
from multiprocessing import Process import time import random def task(name): print('%s is piaoing' %name) time.sleep(random.randrange(1,5)) print('%s is piao end' %name) if __name__ == '__main__': p1=Process(target=task,args=('egon',),name='子进程1') #可以用关键参数来指定进程名,p1只是一个进程对象 p1.start() print(p1.name,p1.pid,)
3.4.2 Process对象的方法之:terminate与is_alive
from multiprocessing import Process import time import random def task(name): print('%s is piaoing' %name) time.sleep(random.randrange(1,5)) print('%s is piao end' %name) if __name__ == '__main__': p1=Process(target=task,args=('egon',)) p1.start() p1.terminate()#关闭进程,不会立即关闭,所以is_alive立刻查看的结果可能还是存活 print(p1.is_alive()) #结果为True print('主') print(p1.is_alive()) #结果为False
3.4.3 Process对象的join方法:
如果主进程的任务在执行到某一个阶段时,需要等待子进程执行完毕后才能继续执行,就需要有一种机制能够让主进程检测子进程是否运行完毕,在子进程执行完毕后才继续执行,否则一直在原地阻塞,这就是join方法的作用
from multiprocessing import Process import time import random import os def task(): print('%s is piaoing' %os.getpid()) time.sleep(random.randrange(1,3)) print('%s is piao end' %os.getpid()) if __name__ == '__main__': p=Process(target=task) p.start() p.join() #等待p停止,才执行下一行代码 print('主')
3.5守护进程
如果我们有两个任务需要并发执行,那么开一个主进程和一个子进程分别去执行就ok了,如果子进程的任务在主进程任务结束后就没有存在的必要了,那么该子进程应该在开启前就被设置成守护进程。主进程代码运行结束,守护进程随即终止。
关于守护进程需要强调两点:
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children。
from multiprocessing import Process import time import random def task(name): print('%s is piaoing' %name) time.sleep(random.randrange(1,3)) print('%s is piao end' %name) if __name__ == '__main__': p=Process(target=task,args=('egon',)) p.daemon=True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() print('主') #只要终端打印出这一行内容,那么守护进程p也就跟着结束掉了
3.6互斥锁
互斥锁顾名思义,就是互相排斥,如果把多个进程比喻为多个人,互斥锁的工作原理就是多个人都要去争抢同一个资源:卫生间,一个人抢到卫生间后上一把锁,其他人都要等着,等到这个完成任务后释放锁,其他人才有可能有一个抢到......所以互斥锁的原理,就是把并发改成穿行,降低了效率,但保证了数据安全不错乱。
from multiprocessing import Process, Lock # 需要导入Lock模块 import time def task(name, mutex): mutex.acquire() print('%s 1' % name) time.sleep(1) print('%s 1' % name) time.sleep(1) print('%s 1' % name) mutex.release() if __name__ == '__main__': mutex = Lock() # 实例化得到互斥锁 for i in range(3): p = Process(target=task, args=('进程%s' % i, mutex)) # 传入子进程 p.start()
3.7互斥锁与join(模拟抢票软件)
使用join可以将并发变成串行,互斥锁的原理也是将并发变成串行,那我们直接使用join就可以了,为何还要互斥锁?


from multiprocessing import Process,Lock import json import time def search(name): time.sleep(1) with open('db.txt', 'r', encoding='utf-8') as f: dic = json.load(f) print('<%s> 查到剩余票数 【%s】' % (name, dic['count'])) def get(name): time.sleep(1) dic = json.load(open('db.txt', 'r', encoding='utf-8')) if dic['count'] > 0: dic['count'] -= 1 time.sleep(3) json.dump(dic, open('db.txt', 'w', encoding='utf-8')) print('<%s> 购票成功!' % name) else: print('购票失败,没有余票了..') def task(name, mutex): search(name) mutex.acquire() get(name) mutex.release() if __name__ == '__main__': mutex = Lock() for i in range(5): p = Process(target=task, args=('用户%s' % i, mutex)) p.start()
#把文件db.txt的内容重置为:{"count":1} from multiprocessing import Process,Lock import time,json def search(name): dic=json.load(open('db.txt')) print('�33[43m%s 查到剩余票数%s�33[0m' %(name,dic['count'])) def get(name): dic=json.load(open('db.txt')) time.sleep(1) #模拟读数据的网络延迟 if dic['count'] >0: dic['count']-=1 time.sleep(1) #模拟写数据的网络延迟 json.dump(dic,open('db.txt','w')) print('�33[46m%s 购票成功�33[0m' %name) def task(name,): search(name) get(name) if __name__ == '__main__': for i in range(10): name='<路人%s>' %i p=Process(target=task,args=(name,)) p.start() p.join()
实验发现使用join将并发改成穿行,确实能保证数据安全,但问题是连查票操作也变成只能一个一个人去查了,很明显大家查票时应该是并发地去查询而无需考虑数据准确与否,此时join与互斥锁的区别就显而易见了,join是将一个任务整体串行,而互斥锁的好处则是可以将一个任务中的某一段代码串行,比如只让task函数中的get任务串行。
3.8互斥锁小结
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行地修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。
虽然可以用文件共享数据实现进程间通信,但问题是:
1、效率低(共享数据基于文件,而文件是硬盘上的数据)
2、需要自己加锁处理
因此我们最好找寻一种解决方案能够兼顾:
1、效率高(多个进程共享一块内存的数据)
2、帮我们处理好锁问题。
这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。
队列和管道都是将数据存放于内存中,而队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来,因而队列才是进程间通信的最佳选择。
我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
3.9队列*
进程彼此之间互相隔离,要实现进程间通信(IPC),multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的
创建队列的类(底层就是以管道和锁定的方式实现):
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
参数介绍:
maxsize是队列中允许最大项数,省略则无大小限制。
但需要明确:
1、队列内存放的是消息而非大数据
2、队列占用的是内存空间,因而maxsize即便是无大小限制也受限于内存大小
主要方法介绍:
q.put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
q.get方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常.
q.get_nowait():同q.get(False)
q.put_nowait():同q.put(False)
q.empty():调用此方法时q为空则返回True,该结果不可靠,比如在返回True的过程中,如果队列中又加入了项目。
q.full():调用此方法时q已满则返回True,该结果不可靠,比如在返回True的过程中,如果队列中的项目被取走。
q.qsize():返回队列中目前项目的正确数量,结果也不可靠,理由同q.empty()和q.full()一样
其他方法(了解):
q.cancel_join_thread():不会在进程退出时自动连接后台线程。可以防止join_thread()方法阻塞
q.close():关闭队列,防止队列中加入更多数据。调用此方法,后台线程将继续写入那些已经入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将调用此方法。关闭队列不会在队列使用者中产生任何类型的数据结束信号或异常。例如,如果某个使用者正在被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.join_thread():连接队列的后台线程。此方法用于在调用q.close()方法之后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread方法可以禁止这种行为
实例:
multiprocessing模块支持进程间通信的两种主要形式:管道和队列 都是基于消息传递实现的,但是队列接口 ''' from multiprocessing import Process,Queue # 需要导入Queue模块 import time q=Queue(3) #put ,get ,put_nowait,get_nowait,full,empty q.put(3) q.put(3) q.put(3) print(q.full()) #满了 print(q.get()) # 先进先出FIFO print(q.get()) print(q.get()) print(q.empty()) #空了
3.10生产者消费者模型
为什么要使用生产者消费者模型
生产者指的是生产数据的任务,消费者指的是处理数据的任务,在并发编程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者和消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这个阻塞队列就是用来给生产者和消费者解耦的
from multiprocessing import Process,Queue import time def producer(q): for i in range(10): res = '包子%s' % i time.sleep(1) print('生产者生产%s' % res) q.put(res) def consumer(q): while True: time.sleep(2) res = q.get() if res == None: break print('消费者吃了%s' % res) if __name__ == '__main__': # 容器 q = Queue() # 生产者们 p1 = Process(target=producer, args=(q,)) # 消费者们 c1 = Process(target=consumer, args=(q,)) p1.start() c1.start() p1.join() q.put(None)
此时的问题是主进程永远不会结束,原因是:生产者p在生产完后就结束了,但是消费者c在取空了q之后,则一直处于死循环中且卡在q.get()这一步。我们的思路是发送结束信号,而有另外一种队列提供了这种机制。
JoinableQueue([maxsize]) ,这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
from multiprocessing import Process, JoinableQueue import time def producer(q): for i in range(3): res = '包子%s' % i time.sleep(1) print('生产者生产%s' % res) q.put(res) q.join() # 接收到task_done的信号后,等待消费者把自己放入队列中的所有的数据都取走,生产者才结束 def consumer(q): while True: time.sleep(2) res = q.get() print('消费者吃了%s' % res) q.task_done() # 发送信号给q.join(),说明已经从队列中取走一个数据并处理完毕了 if __name__ == '__main__': # 容器 q = JoinableQueue() # 生产者们 p1 = Process(target=producer, args=(q,)) p2 = Process(target=producer, args=(q,)) # 消费者们 c1 = Process(target=consumer, args=(q,)) c2 = Process(target=consumer, args=(q,)) c1.daemon = True c2.daemon = True p1.start() c1.start() p2.start() c2.start() p1.join() p2.join() print('zhu')